Polaris is Imply’s fully managed DBaaS built from Druid to deliver fast OLAP on both streaming and batch data. In this blog post we describe how to move tables from ClickHouse into Polaris. Since Clickhouse is also an OLAP engine, it is likely that the data is already in a form that can be directly ingested into Polaris. But Polaris also enables Rollup and Secondary Partitioning at ingestion time if additional optimization is desired. We’ll review how to export data from ClickHouse in a format that is easy to ingest into Polaris.
Exporting from ClickHouse
Polaris can import data in JSON format. It requires that each JSON object appear in a single line in the data file. From ClickHouse, such a file can be created using a SQL statement in the clickhouse-clientCLI by using FORMAT JSONEachRow:
# clickhouse-client
ClickHouse client version 22.4.1.1.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 22.4.1 revision 54455.
🙂 SELECT * FROM tutorial.kttm INTO OUTFILE 'data.json' FORMAT JSONEachRow;
SELECT *
FROM tutorial.kttm
INTO OUTFILE 'data.json'
FORMAT JSONEachRow
Query id: b4a5301b-09d5-4cb3-b10d-c7494f4eae7b
202862 rows in set. Elapsed: 0.696 sec. Processed 202.86 thousand rows, 108.91 MB (291.51 thousand rows/s., 156.50 MB/s.)
It is a good idea to compress the data and then transfer it to the Polaris platform. Polaris can ingest the data in compressed form.
# gzip data.json
Importing Data into Polaris
Now that we have the data, let’s bring it into Polaris. From the Polaris Home screen, click on “Create a table and load data”.
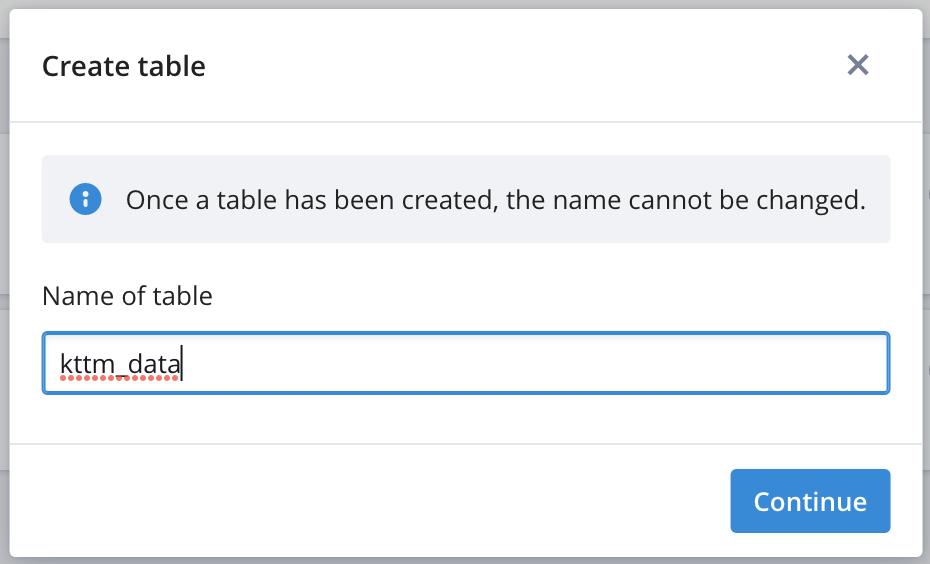
Give the table a name and click Continue:
Click on “+ Add data”
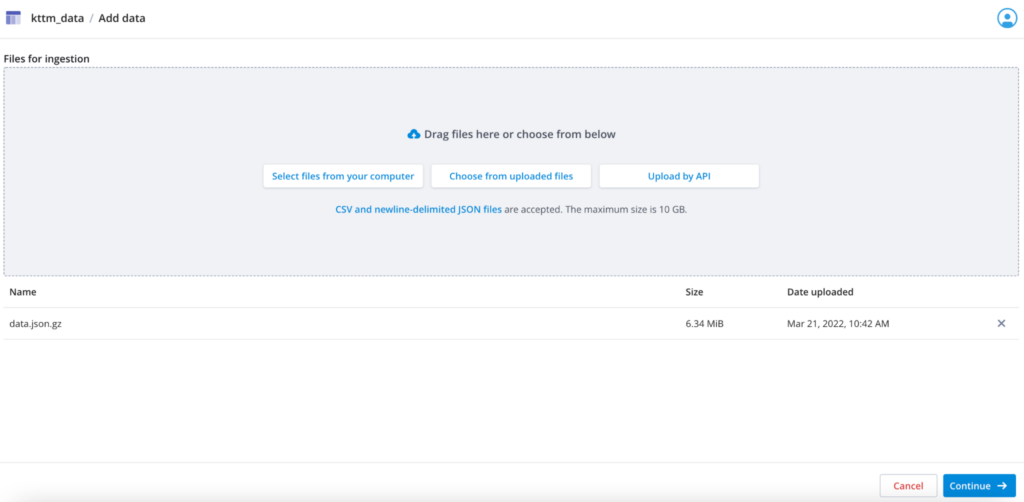
Drag your file into the window to upload it.
You can also use the “Upload by API” button to get the prebuilt curl API call to submit the data file. Just replace @YOURFILE.json with @data.json.gz and once it is uploaded select “Choose from uploaded files” to continue.
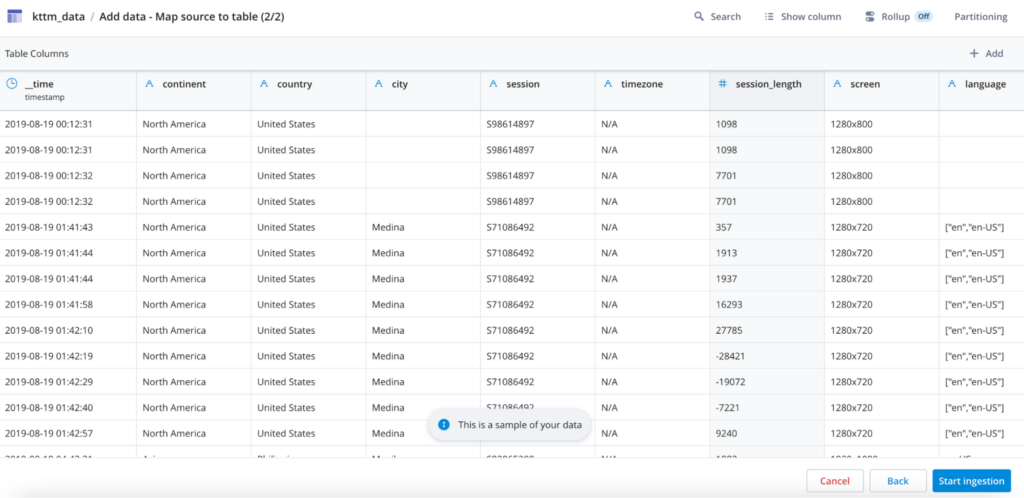
Once you’ve selected the file to load, click “Continue” and Polaris will sample the data, parse the columns and bring up the ingestion configuration screen:
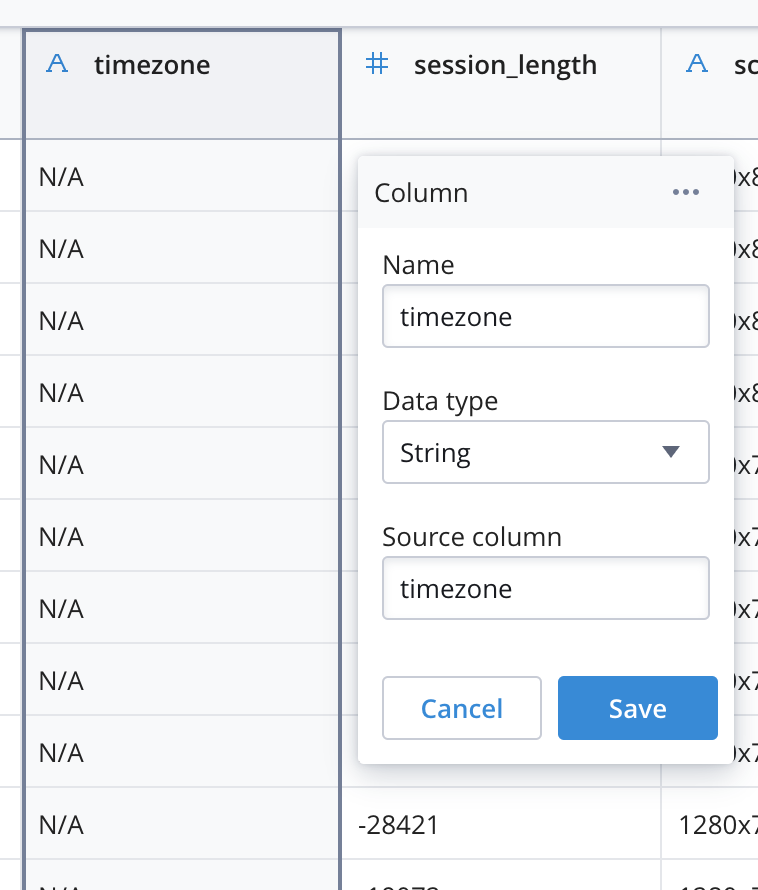
For the most part it will get the mapping of data types correct on its own. String and Numeric types will be properly identified and JSON arrays will be converted to multi-value columns. The one thing that is imperative to verify is that the column it has selected for the __time column is the correct one. The __time column in Polaris is used to partition the timeline into segments and __time it is the primary pruning strategy in Polaris, so you’ll want to pick the timestamp in the source that best indicates the time of the events you are modeling. In this case there is a single timestamp in the source data and it is correctly mapped to __time automatically.
If we want to change data types on any of the imported columns, or the source column mapping, simply click on the column header to edit it and click Save:
There is no need to change any mapping or data types in this example, so just click on “Start Ingestion” to start the load.
You can view the progress of the ingestion from the Home screen, by selecting “Ingestion Jobs”:
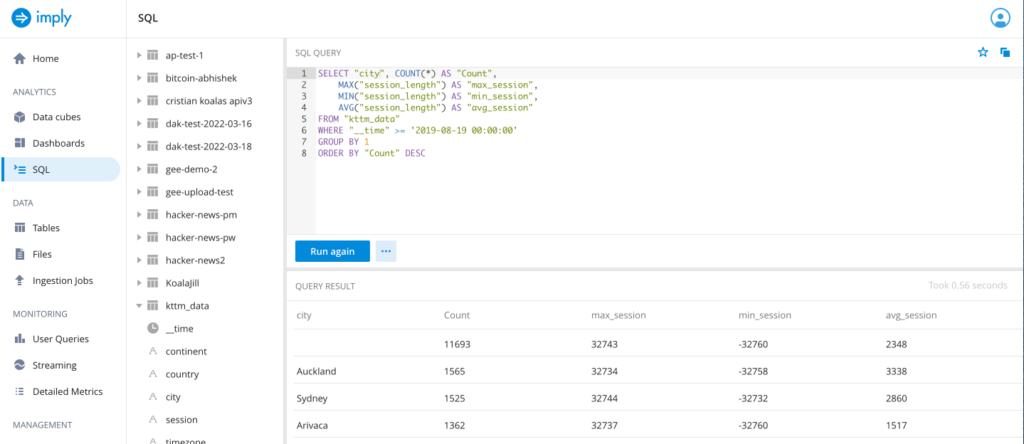
Querying the Data
Once the job completes, we are ready to query. From the Home screen select “SQL”:
Conclusion
Moving data from ClickHouse into Polaris is easy. Now you can do more with your data on Polaris. Check out the following links for visualization functions and event streaming in Polaris:
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....