Imply lookups for enhanced network flow visibility
Nov 26, 2018
Eric Graham
Modern day TCP/IP networks continue to evolve making management and monitoring ever harder In addition, stricter SLAs for uptime, mission critical enterprise applications and the need for fast MTTR makes ultra-fast databases and easy to use UIs critical for business success Modern day tools need to be flexible, not just supporting basic network flow for IP visibility, but by providing visibility into hostnames, microservice names, usernames and more Imply and Druid were designed from the ground up to help solve these exact problems.
The founders of Imply built one of the most popular open source databases available today for operational analytics, Druid Within Druid there are multiple ways to enhance visibility for existing network flow records This how-to blog covers one way to do this using Druid lookup tables You can think of lookup tables as a secondary fact table that you can use to query based on a key value.
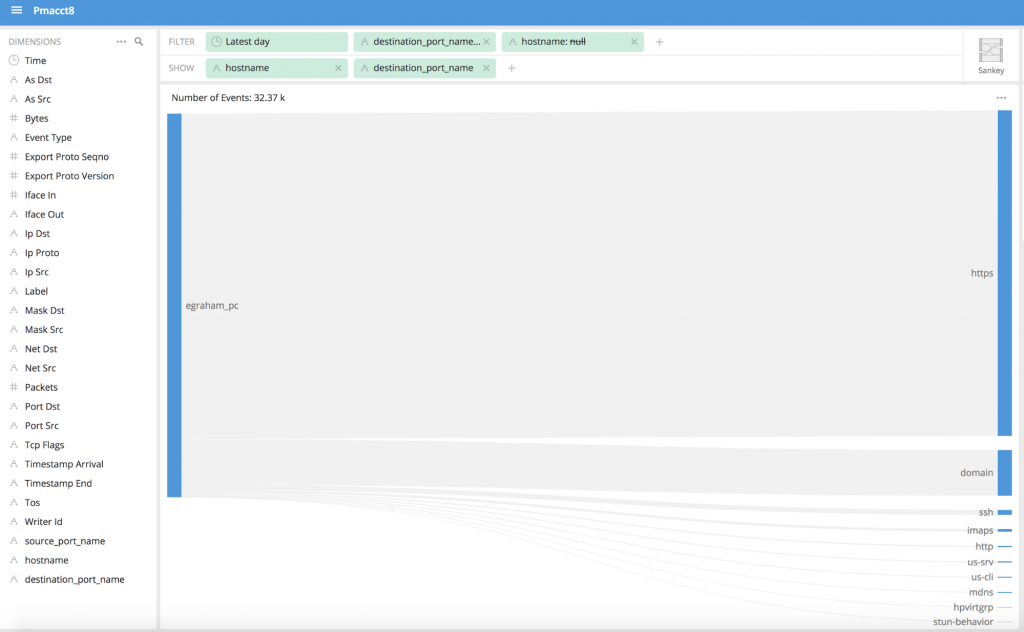
If I want to define hostname, which is not included in standard network flow records, I could use a lookup table to join the two tables based on IP address and assign my latest hostname to a dimension in Pivot, the Imply UI This works by providing a join at query time mapping IP to a hostname (name coming from a secondary lookup table) by using IP as the common dimension between tables.
The following steps can be used to define a basic lookup table using a csv for input This how-to assumes you have a data source loaded in Pivot and there is a dimension that matches your key value in the lookup table.
Include druid-lookups-cached-global in your extension list for Druid This can be defined in imply/conf/druid/_common/common.runtime.properties for the following variable.
Create your csv input file using a format similar to the following (primary key,value key) The creation of this file could easily be automated using DNS or IPAM systems Your primary table should already include the IPs you are mapping.
Check to see that your lookup table was loaded into your broker. You may have to wait for your poll interval to expire before the table is updated on the broker.
curl -X GET http://<your_broker_ip>:8082/druid/listen/v1/lookups
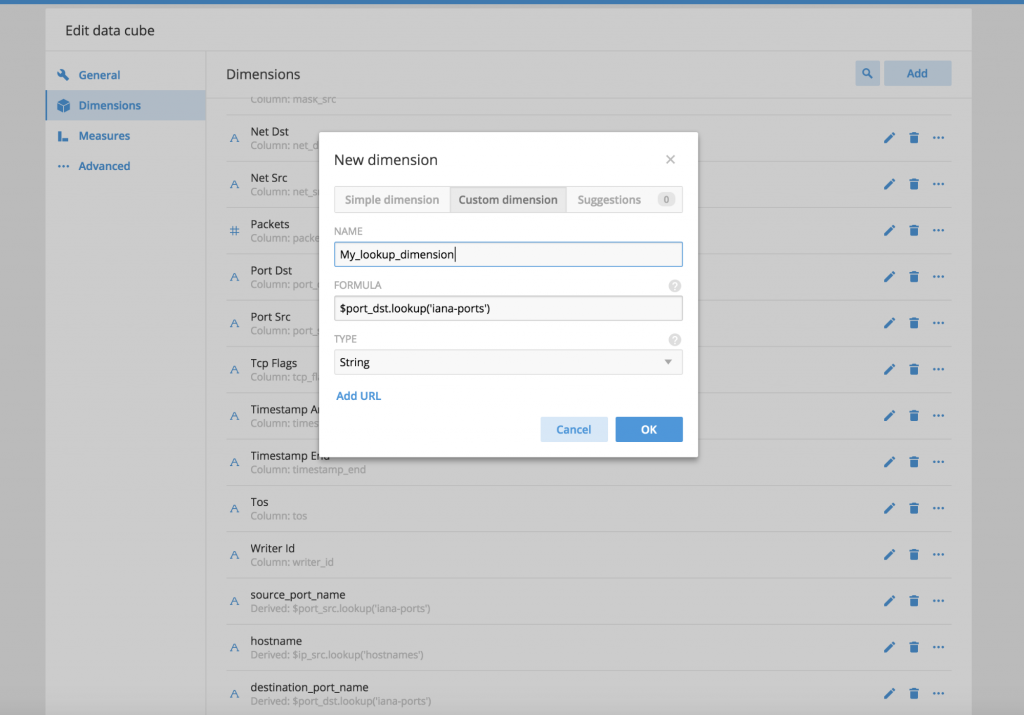
At this point, your lookup table should be ready to use in Pivot To use the lookup table, you can create a new dimension that uses Plywood to query the lookup and primary table The Plywood syntax looks something to the following.
$port_dst.lookup('iana-ports')
port_dst is the dimension name in my primary table and “iana-ports” is the name I used to define my lookup table in step 3 above.
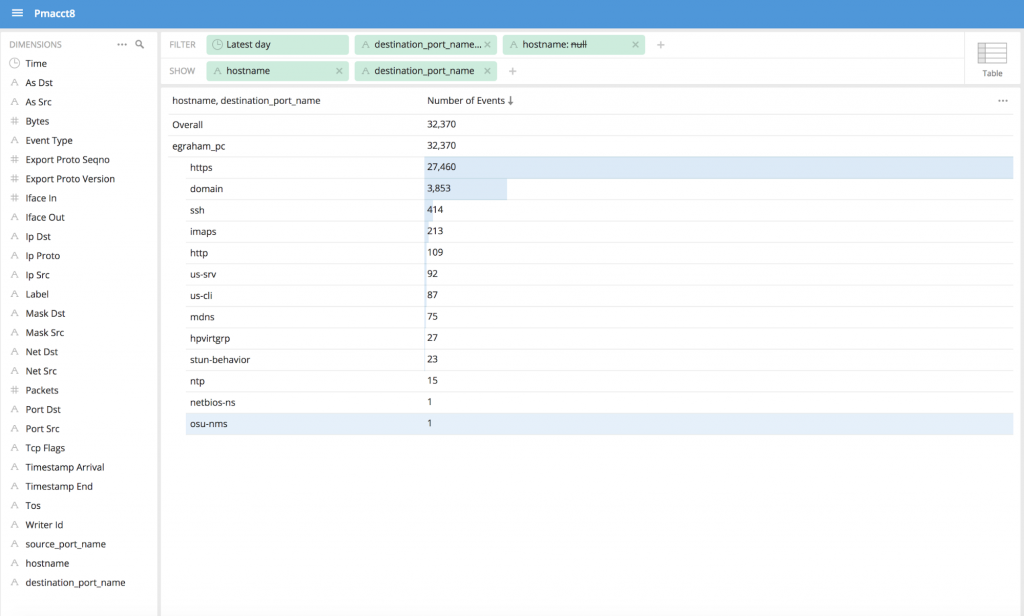
Save your dimension Now you can use this dimension to extract the lookup table name against the primary key value In the example below, I created multiple associations for IP to hostname and port to name mappings.
Note: Keep in mind that if you want to track changes to a mapped value over time, lookup tables are not the way to do it A better way would be merge your two tables together during ingest using Kafka or some other stream processing database.
In summary, lookup tables are a great way to provide additional visibility at query time Combined with Imply’s easy to use UI and Druid’s very fast response time, lookup tables are a truly powerful feature Although not perfect for every use case, they are a great way to provide additional visibility in certain cases Continue visiting our blog for future network flow related articles.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...