Oct 17, 2024
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreWelcome to Imply 4.0! This release has over 50 new features and various enhancements across all areas of the product. You can try it out here.
With every release, we make the Imply platform the easiest way to get to real-time self-service analytics at scale to power your data applications.
This release is no different. It bears the fruits of three major efforts:
Imply now provides a generic cluster management model for self-hosted use cases that works on non-Kubernetes environments, e.g. non-Dockerized on prem or VMs in the cloud. With a single click, you can reliably upgrade or downgrade all your Imply deployments and monitor them from a centralized dashboard.
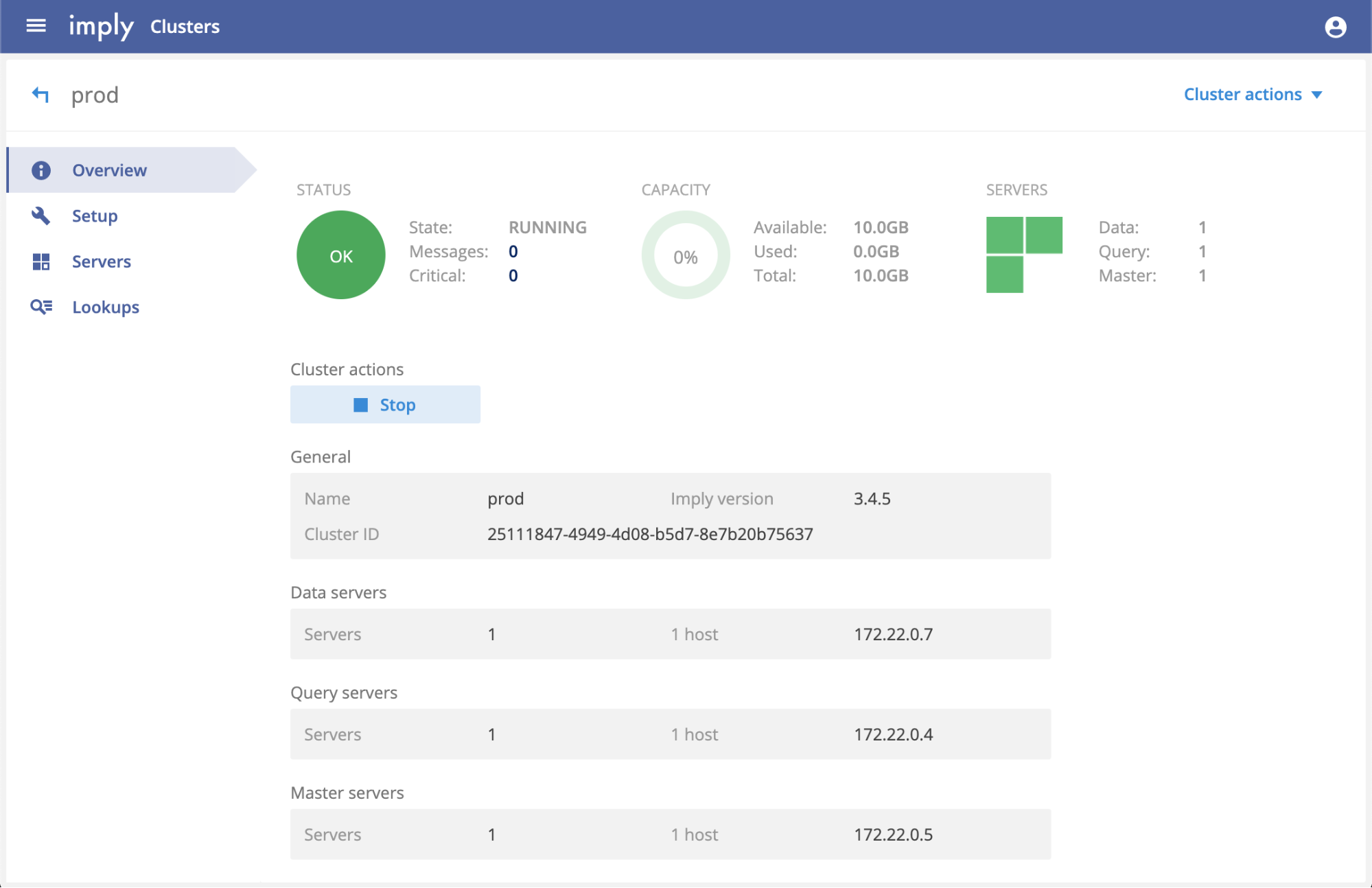
We’re also announcing the first release of Imply Private on GCP, using the Google Kubernetes Engine. Imply Private on GCP extends our Imply Private with Kubernetes offering to provide a similar experience to Imply Cloud on AWS, but in a self-contained environment completely under the control of our customers on GCP.
This implementation provides tighter integration with the GKE and Kubernetes environments, allowing users to choose GCP instances from a preset machine pool. This ability emulates an infinite pool of resources that you can scale up to through the manager with only a few clicks in the UI.
This milestone release includes a number of improvements to ensure Pivot remains the fastest and easiest tool for exploratory self-service analytics – even when operating against data sources with extremely high cardinality columns.
Query times for filter preview results are now much faster than in previous releases, and ad-hoc filter values can now be applied without waiting for preview values to be returned. This lets you apply filter changes more rapidly, which comes in especially handy when filtering on well-known dimension values.
Imply 4.0 also adds Alpha support for query cancellation when using Pivot. With this feature enabled, when the UI no longer needs a query, the query is cancelled across the entire stack. This frees up resources in both the Pivot application layer and on the Druid cluster.
Some examples of when query cancellation may impact performance and cost on a cluster include:
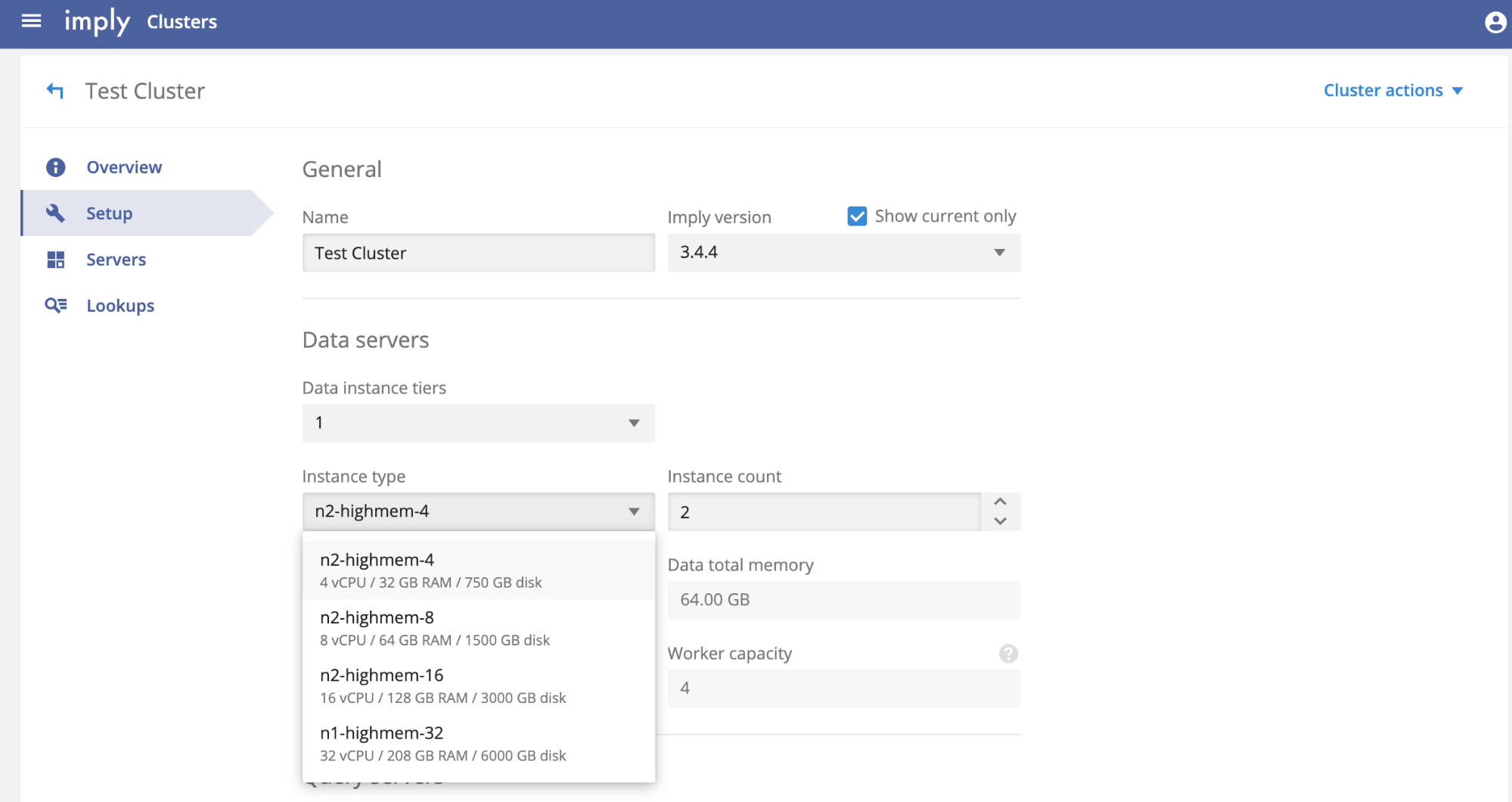
As part of an ongoing initiative to offer SQL as an alternative to the Plywood expression language throughout the Pivot UI, we’re happy to announce an early look at a major new capability in Pivot for Imply 4.0: the ability to create data cubes using an SQL statement wrapper.
Now you can easily create data cubes that leverage recent improvements to the Druid engine’s SQL querying capabilities. Most notably, you can use JOIN statements, with full support for dimensions and measure introspection.
Please note that Pivot SQL is still an alpha feature. The team is focused on ensuring that security, performance, and data integrity are not impacted when using these new capabilities. Until the feature is out of alpha, we don’t recommend using Pivot SQL in production environments.
In Imply 3.4, vectorized query execution was enabled by default. In Imply 4.0, the query engine has been vectorized to support calculations on Group By queries.
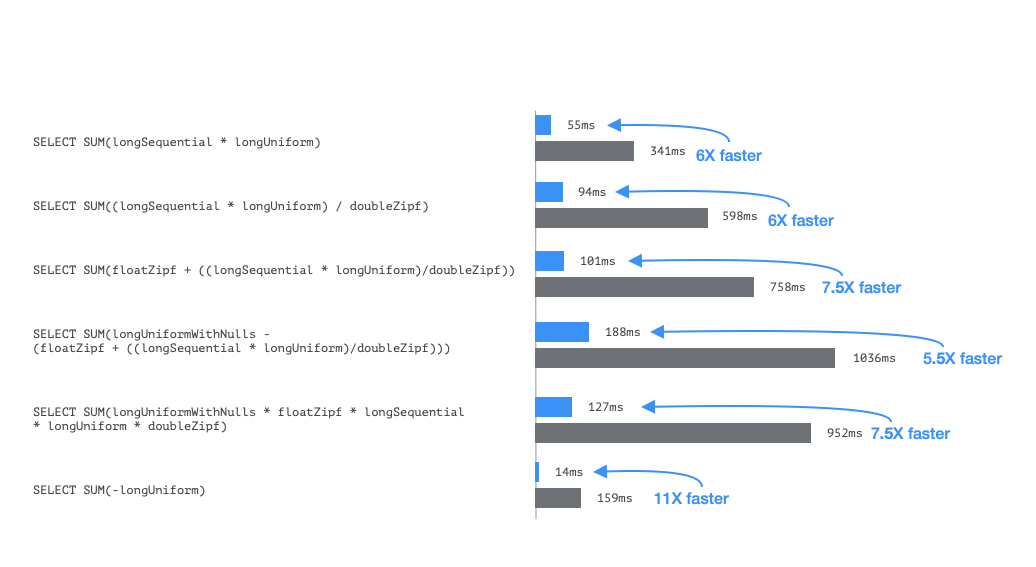
The following example demonstrates how much faster Imply 4.0 computes the total_price column on the fly as a virtual column when compared to Imply 3.4. This is a common usage pattern that couldn’t be vectorized in previous releases.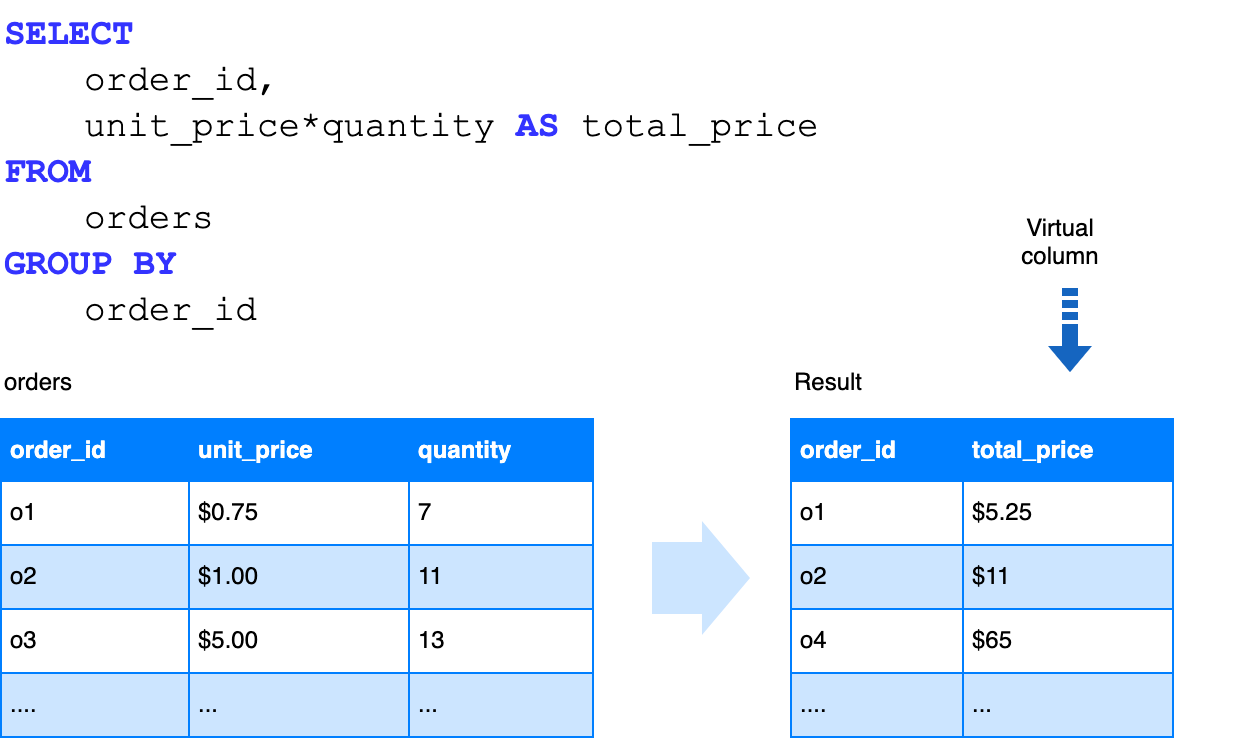
The benchmarks below show how we’ve reduced the execution time for these kinds of queries anywhere between 6x to 11x.
Optimal query performance depends on optimal data layouts. It’s often difficult to pre-determine the best data layout at ingestion time since optimal layout depends on future queries. At the same time, it is also difficult to maintain an optimal data layout while new data is continuously arriving in the cluster.
In this release, you can set up auto-compaction rules that reshape your segments into optimal sizes with optimized partitioning schemes as you learn about your workload over time. These autocompaction rules continuously run in the background to optimize newly arrived data over time.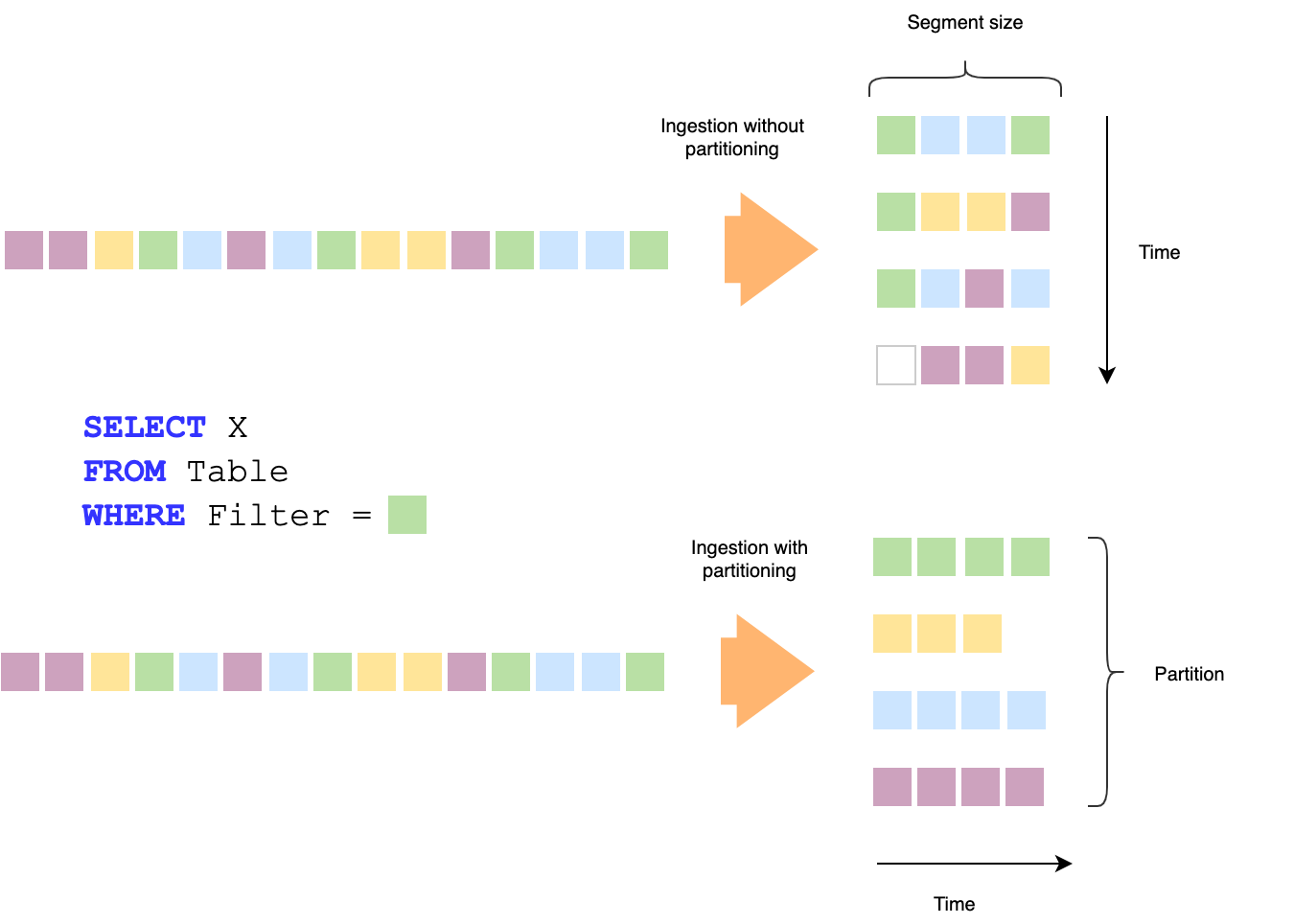
Types of use cases where this might apply are:
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn MoreThe Top Five Articles from the Imply Developer Center (Fall 2024 edition)
Build, troubleshoot, and learn—with the top five articles, lessons, and tutorials from Imply’s Developer Center for Fall 2024.
Learn More