Oct 17, 2024
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreCo-author: Peter Marshall
Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
We are excited to announce the release of Apache Druid 30.0. This release contains over 409 commits from 50 contributors.
Druid 30 continues the investment across the following three key pillars: Ecosystem integrations, Performance, and SQL capabilities.
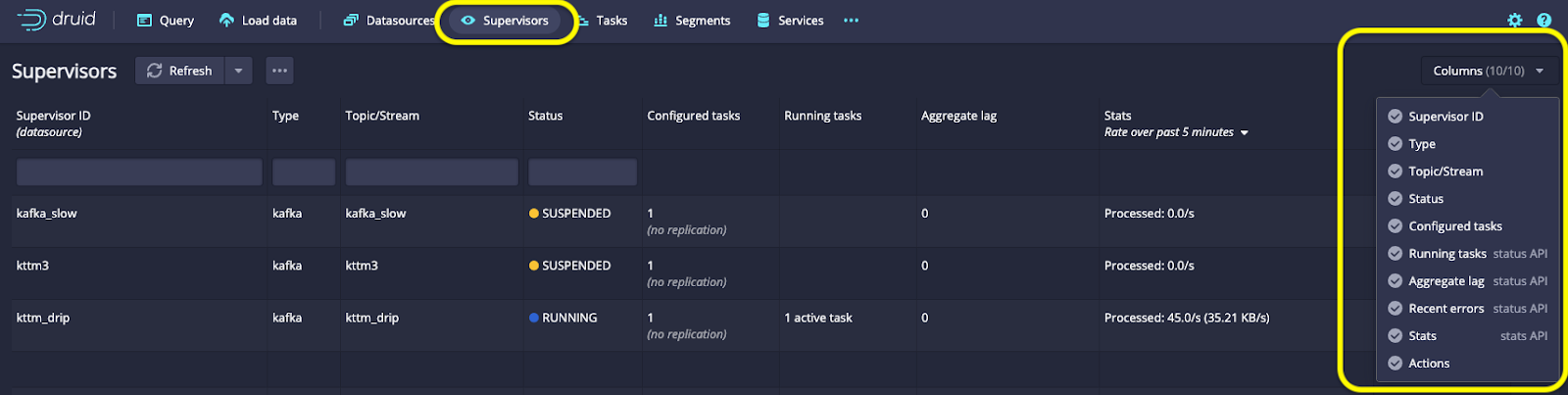
An essential part of the Druid ecosystem integration is the ability to ingest data from various sources upstream. In this release, we’ve updated the Supervisors view, where you can monitor data ingestion task status. This view includes additional column selections, such as recent stats and errors.
We have introduced a byte-based guardrail for Amazon Kinesis ingestion to improve reliability and scalability. Previously, the guardrail was based on record counts. This meant the limit would probably be too low for small records or too high for large records. This could sometimes cause ingestion failures due to insufficient memory to handle a sudden increase in individual record size. The new byte-based guardrail protects against such scenarios.
At the same time, we have set per-shard lag detection instead of global lag detection to improve Kinesis ingestion auto-scaling. This is useful in cases when an individual Kinesis shard receives a traffic spike instead of a traffic spike across all shards. The new per-shard auto-scaling responds more rapidly than previous releases of Druid.
The introduction of parallel incremental segment creation gives Apache Kafka ingestion a performance boost. For context, Druid sequentially persists data from real-time segments into deep storage for historical data retention. Druid pauses real-time ingestion during persistence, potentially leading to a lag if the persistence takes a long time. For data with a high dimension/metric count (1,000+), persistence does take a long time. In Druid 30, you can parallelize this operation by setting numPersistThreads to reduce Kafka ingestion lag substantially.
Rabbit MQ is a popular, widely adopted message queue solution. Compared to Kafka, it is significantly easier to deploy and provides richer message routing capabilities. However, it is not as scalable as Kafka and doesn’t support exactly-once delivery.
In this release, a community-contributed extension based on Druid’s modern ingestion algorithm enables you to load data from Rabbit MSQ Superstream as a peer of Kafka and Kinesis.
Note that this extension is still under development and only supports loading super-streams for now. It also lacks some of the UI controls available for Kafka and Kinesis.
In Druid 29, we introduced support for ingesting data from Deltalake. However, a key limitation of the feature was that Druid would process all data from the latest snapshot, even when you were only loading data from a specific partition or a subset of columns. In Druid 30, you can now filter data based on partitions and columns, which substantially reduces the amount of data to process during ingestion.
MSQ supports exporting large volumes of data from Druid. In Druid 30, we have added support to export to Google Cloud Storage (GCS). You can specify a GCS bucket with a prefix as part of your export query to make data available for analysis in downstream systems.
INSERT INTO
EXTERN( google(bucket => ‘your_bucket’, prefix =>’prefix/to/files’) )
AS CSV
SELECT…With the new azureStorage inputSource, you can load data across multiple storage accounts. This is especially useful in large organizations where data is distributed amongst several storage accounts.
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "azureStorage",
"objectGlob": "**.json",
"uris": ["azureStorage://storageAccount/container/prefix1/file.json", "azureStorage://storageAccount/container/prefix2/file2.json"]
},
"inputFormat": { "type": "json" },
...
}A frequent use case for data applications is allowing users to add custom tags and dimensions to data, typically stored in a complex column like JSON. To speed up application queries, Druid has an important feature called rollup, which allows you to adjust the time resolution of data to improve query performance. Rollup combines rows of data with matching dimensions, such as custom tags/dimensions.
Until now, it has not been possible to combine dimensions when one of them is a COMPLEX column, which can limit the usefulness of rollups. COMPLEX columns include JSON, IPv6, Geospatial, and a few advanced data types, the most important being rollup + JSON columns.
Rollups are implemented internally as a GROUP BY query + an ORDER BY query. Imagine a rollup as first grouping similar data together to enable aggregation of similar rows. Then, those rows are sorted in an order based on your choice so that queries can quickly skip over large parts of the data because the query engine knows the sort order of the underlying data.
In Druid 30, we have introduced the support of GROUP BY queries and ORDER BY queries on COMPLEX columns. This enables rollup on COMPLEX columns like JSON, which opens up new possibilities for performance optimization with complex dimensions.
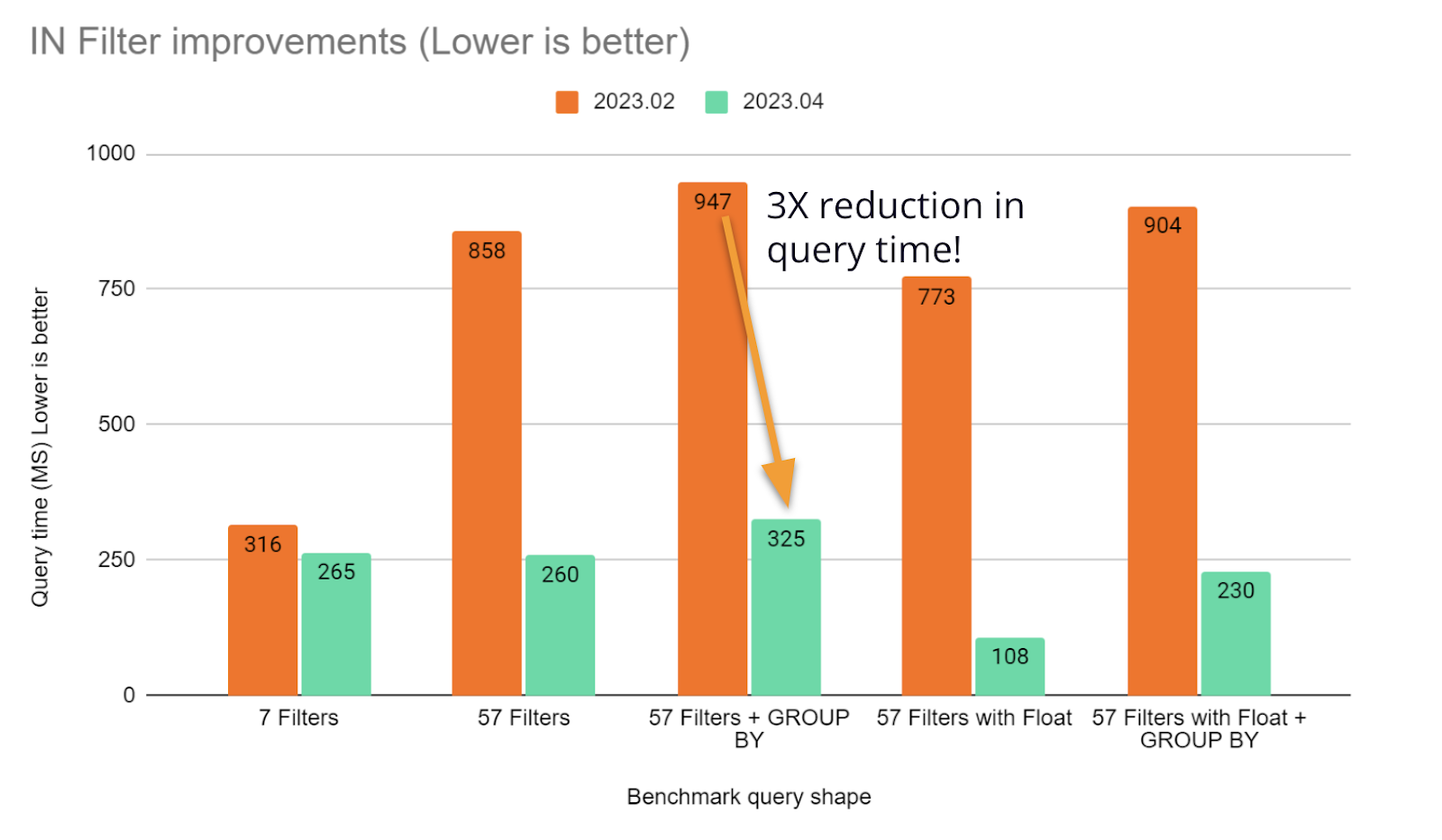
Previously, Druid’s IN filter was not strongly typed, which caused queries like the one below to be slow.
SELECT xyz FROM table WHERE filter IN (A,long,list,of,items)In this release, we have made the IN filter type aware, and we can optimize the execution by making assumptions about the underlying data type and reducing work on each row processed.
AND filters in Druid always used to follow the execution order below:
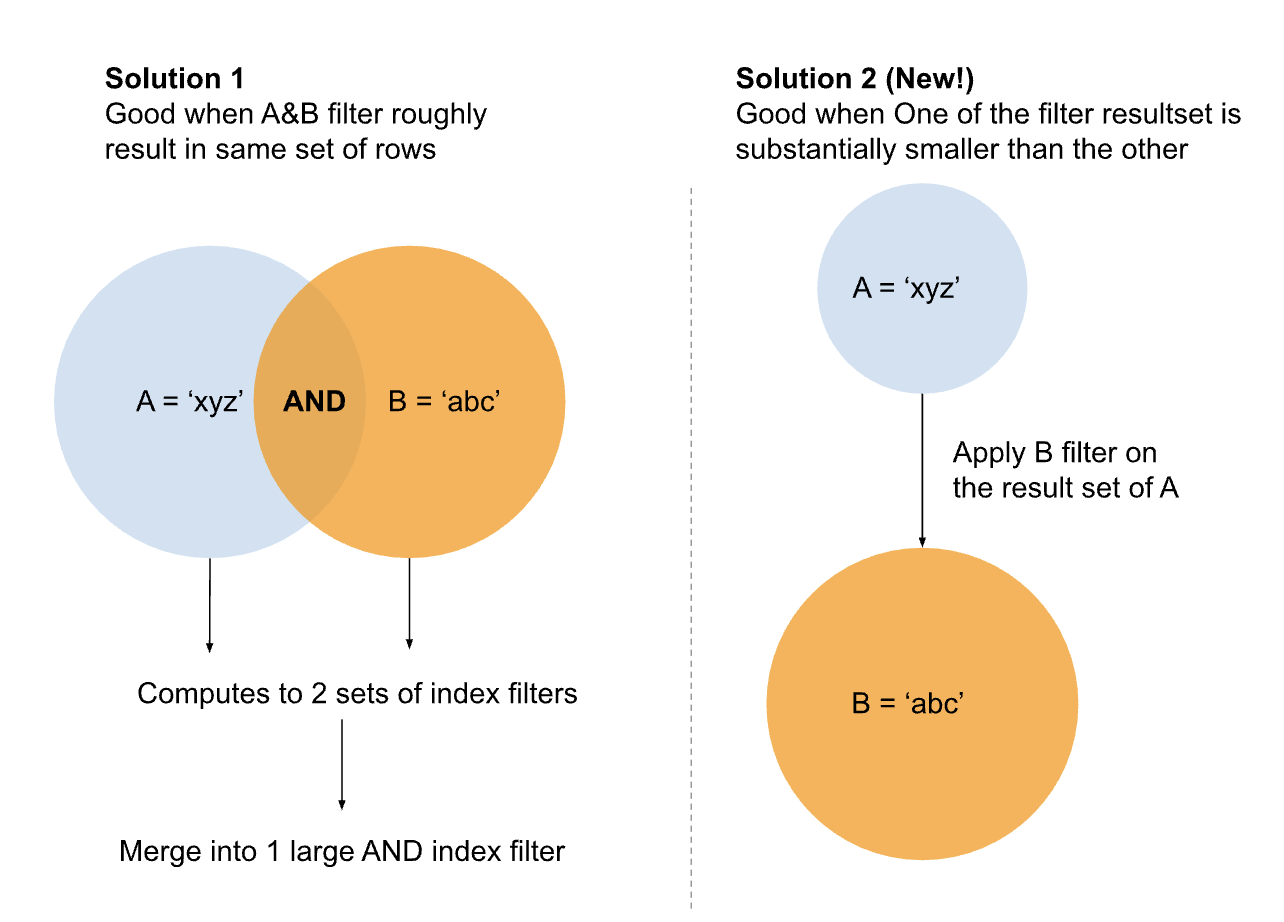
For example, take a query like:
SELECT SUM(longColumn)
FROM druid.table
WHERE stringColumn1 = '1000' AND stringColumn2 LIKE '%1%'Previously, Druid always used indexes to process filters if indexes were available. That’s not always ideal; imagine if stringColumn1 = ‘1000’ matches 100 rows. With indexes, we have to find every true value for stringColumn2 LIKE ‘%1%’ in order to compute the indexes for the filter. If stringColumn2 has more than 100 values, the performance turns out worse than if Druid simply checked for a match in the 100 remaining rows.
With the new logic, Druid now checks the selectivity of indexes as it processes each clause of the AND filter. In cases where it would take more work to compute the index than to match the remaining rows, Druid skips the index computation.
In Druid 30, we’ve continued improvements on concurrent compaction and ingestion, which can substantially reduce data fragmentation and improve performance for streaming ingestion with late arrival data. We’re proud to announce that the API is now stable and ready for production testing.
You have 2 options to enable concurrent append and replace:
To enable this feature, every ingestion/compaction task (index_paraell, index_single, index_kafka, index_kinesis, compact) touching a datasource must have the same setting.
To enable per task/datasource set useConcurrentLocks in the ingestion spec to True for all tasks involved.
Alternatively, to use the global task context default, set druid.index.task.default.context={“useConcurrentLocks”: true} globally for the entire cluster. Then useConcurrentLocks: false for all tasks on a given datasource to opt out of concurrent compaction for that datasource.
Historically, Druid has been a very loosely coupled distributed system. After a cluster shape change, such as scaling up, scaling down, restarts, upgrades, etc., each broker in the cluster queries each historical node it is aware of to rebuild the schema. In clusters with lots of nodes and a high number of segment counts, this can be a very time-consuming operation. For example, if there are 10 brokers, 300 historicals, with 10,000 segments on each historical, this means 10*300*10,000 queries. What can make the situation worse is that a lot of brokers/historicals start simultaneously, leading to resource contention so that no broker gets a full view of the cluster.
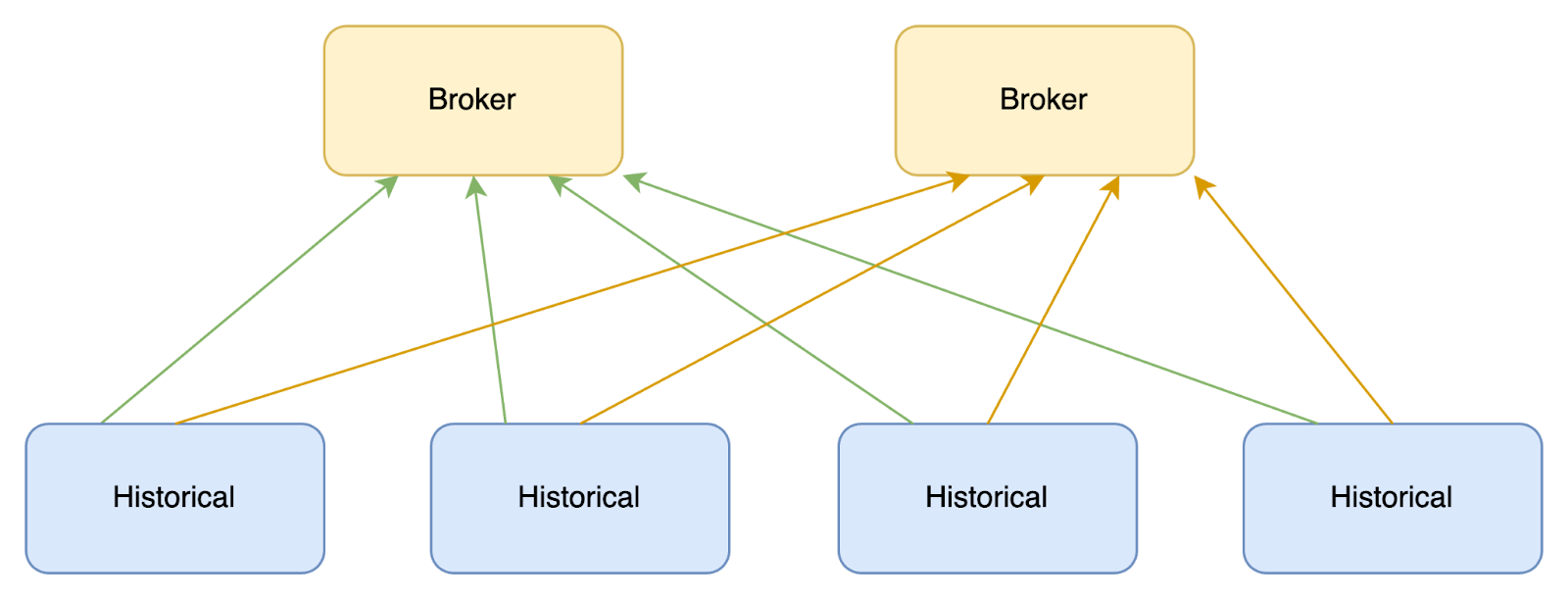
In Druid 30, we are introducing a new mode with a centralized schema. By default, the ingestion tasks publish the schema to the metadata store. The Coordinator also provides a mechanism to backfill schema information from existing segments. After the schema is in the centralized location, the Coordinator exposes it to the other services using an API. Then the Brokers periodically pull the schema information from the Coordinator, thus forming a complete view of the cluster. By default, this happens every minute. The centralized schema substantially reduces the amount of work required to get schema information for the cluster and speeds up the cluster startup process by reducing contention.
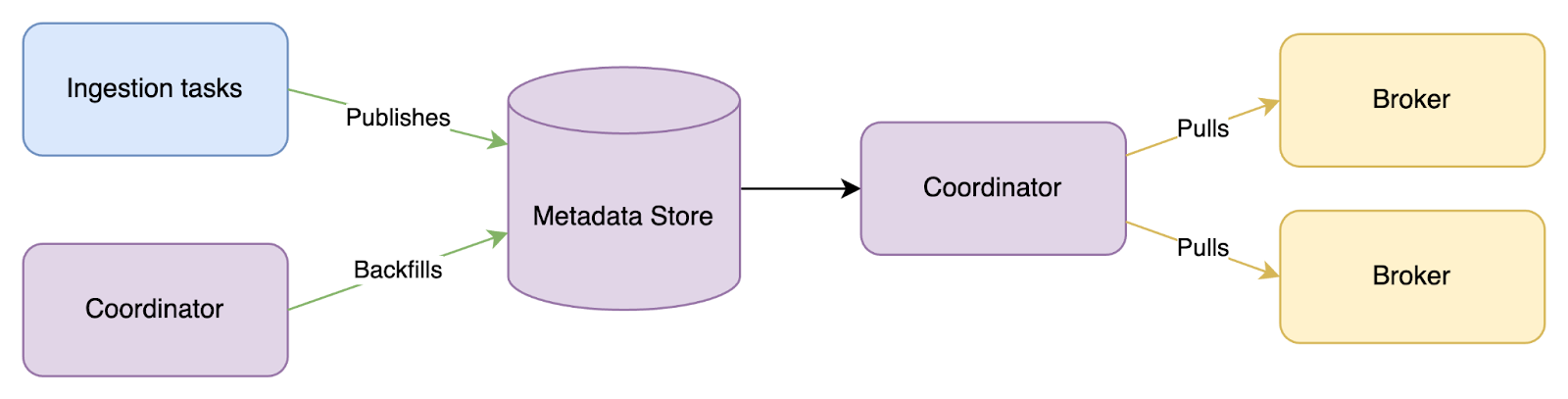
To enable this feature, set the following configs:
Druid’s UNION operator allows you to concatenate multiple results with varying schemas. Specifying the schema of the result set to match those of the incoming data sets requires some effort. The new TABLE(APPEND) function creates a UNION respecting the schemas of the incoming result sets automatically, NULLing appropriately for missing columns, and finding appropriate data types automatically.
For example:
SELECT * FROM TABLE(APPEND('table1','table2','table3'))It will get converted into a table like the one below:
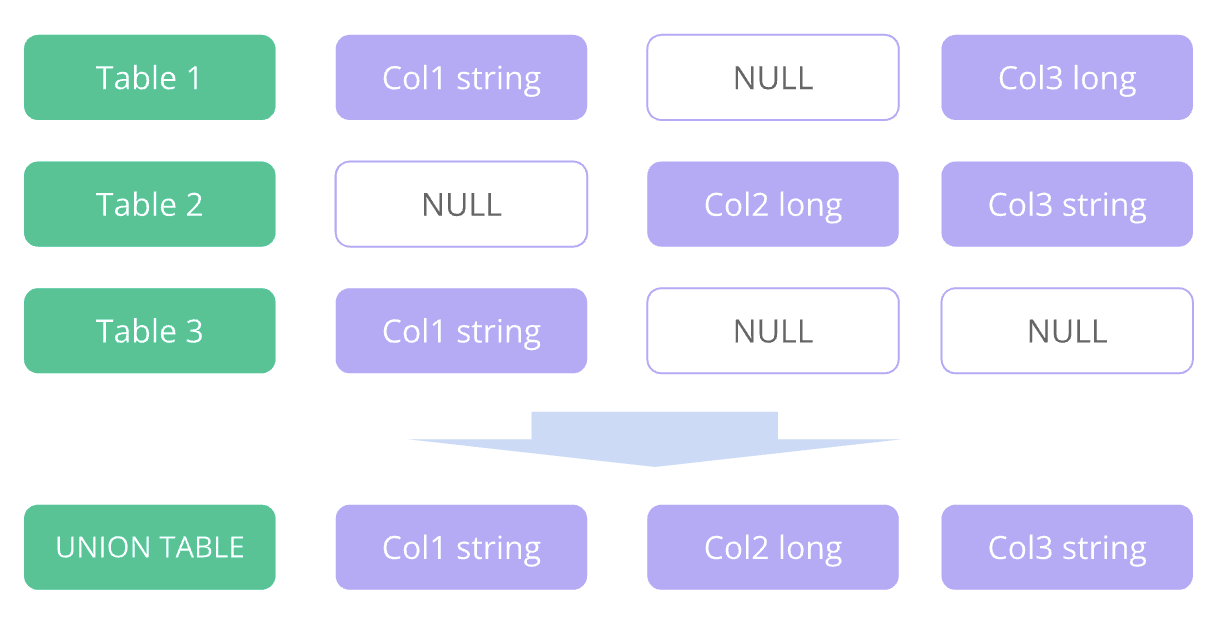
This means you can merge tables from multiple Apache Kafka ingestions on the query layer. And it’s supported in Pivot!
We are making steady progress toward the GA release for SQL window functions. To ensure data correctness, we have implemented an extensive suite of test cases. The chart below illustrates how we are approaching the goal that we set for GA. We strongly encourage you to start testing the Window functions and provide your feedback.
Items in the extended goal are features that Druid doesn’t support today, regardless of whether they are window functions or not. For example, some of the test cases require auto-type casting from BigInt to date data types. When the Window function is released as GA, those limitations will be covered in the documentation.

Originally introduced in Druid 0.18, Druid SQL supports dynamic parameters using a question mark (?) syntax, where parameters are bound to the ?. Parameters are supported in both the HTTP POST and JDBC APIs. Until now, you could not pass an array with double or null values as part of the dynamic query payload. Druid 30 adds support for doubles and null values in arrays for dynamic queries. an example is below:
{
"query": "SELECT doubleArrayColumn from druid.table where ARRAY_CONTAINS(?, doubleArrayColumn)",
"Parameters":[
{"type":"ARRAY", "value":[-25.7, null, 36.85]}
]
}For a full list of all new functionality in Druid 30.0.0, head over to the Apache Druid download page and check out the release notes.
Try out Druid via Python notebooks in the Imply learn-druid Github repo.
Alternatively, you can sign up for Imply Polaris, Imply’s SaaS offering that includes Druid 30’s production quality capabilities and a lot more.
Are you new to Druid? Check out the Druid quickstart, take Imply’s Druid Basics course, and head to the resource-packed Developer Center.
Check out our blogs, videos, and podcasts!Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn MoreThe Top Five Articles from the Imply Developer Center (Fall 2024 edition)
Build, troubleshoot, and learn—with the top five articles, lessons, and tutorials from Imply’s Developer Center for Fall 2024.
Learn More