Apache Druid 0.20.0 contains over 140 updates from 36 contributors, including new features, major performance enhancements (6x-11x on some queries!), bug fixes, and major documentation improvements.
As always, you can visit the Apache Druid download page to download the software and read the full release notes detailing every change. This Druid release is also available as part of the Imply distribution, a self-service analytics solution built around Druid, which includes our drag-and-drop Imply Pivot analytics UI.
We want to encourage you to try and explore Druid with this new release. In the Druid engine, we have made numerous improvements and we are looking forward to seeing the expanded possibilities the new features bring.
Extending Druid’s performance edge
We aim to keep Druid at the forefront of analytical database performance. In Druid 0.20.0, we have once again updated the core engine to improve query speed.
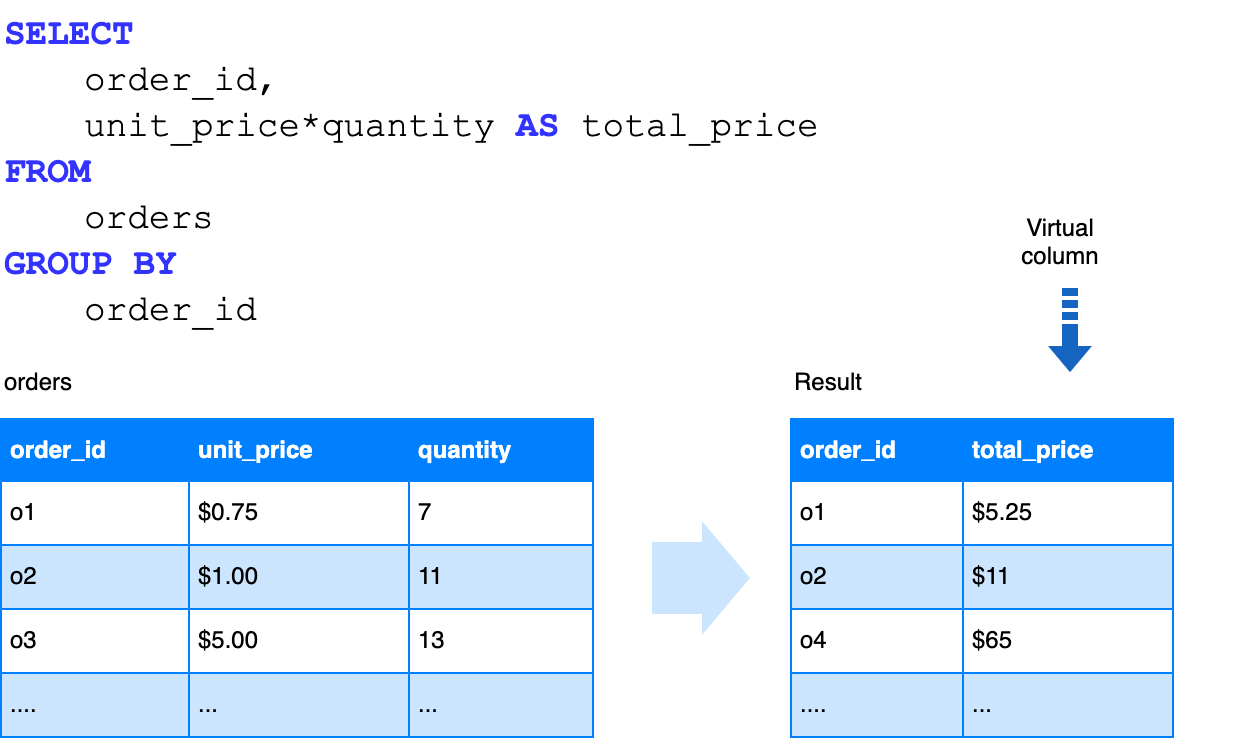
In Druid 0.19, vectorized query execution was enabled by default. In Druid 0.20.0, we have added vectorization for Group By queries and queries involving expression calculations, which is a very common usage pattern. The following example demonstrates how the total_price column is computed as a virtual column on-the-fly.
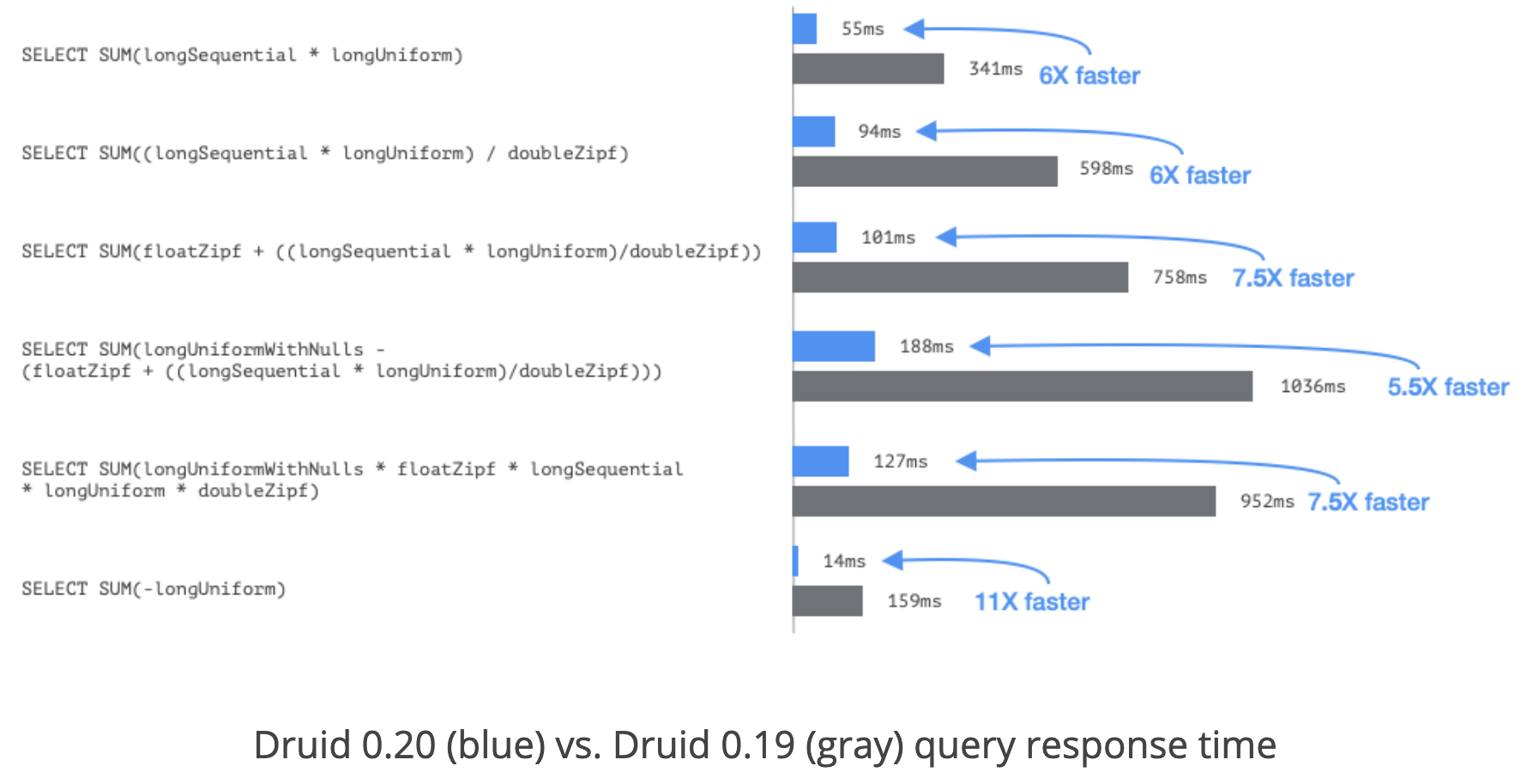
As you can see from the benchmarks below, we are reducing the execution time on these queries by 6x to 11x.
At the same time, we have improved the performance of many statistical aggregators, including min, max, histogram, variance, and ANY. For min/max/ANY aggregators, we are seeing a 30-80% performance improvement and there are also minor performance improvements on histogram aggregators.
Secondary partitioning support for auto-compaction
Optimal query performance depends on optimal data layouts.
It’s often difficult to pre-determine the best data layout at ingestion time, since optimal layout depends on queries to be run in the future. It is also difficult to maintain an optimal data layout as new data constantly arrives in the cluster.
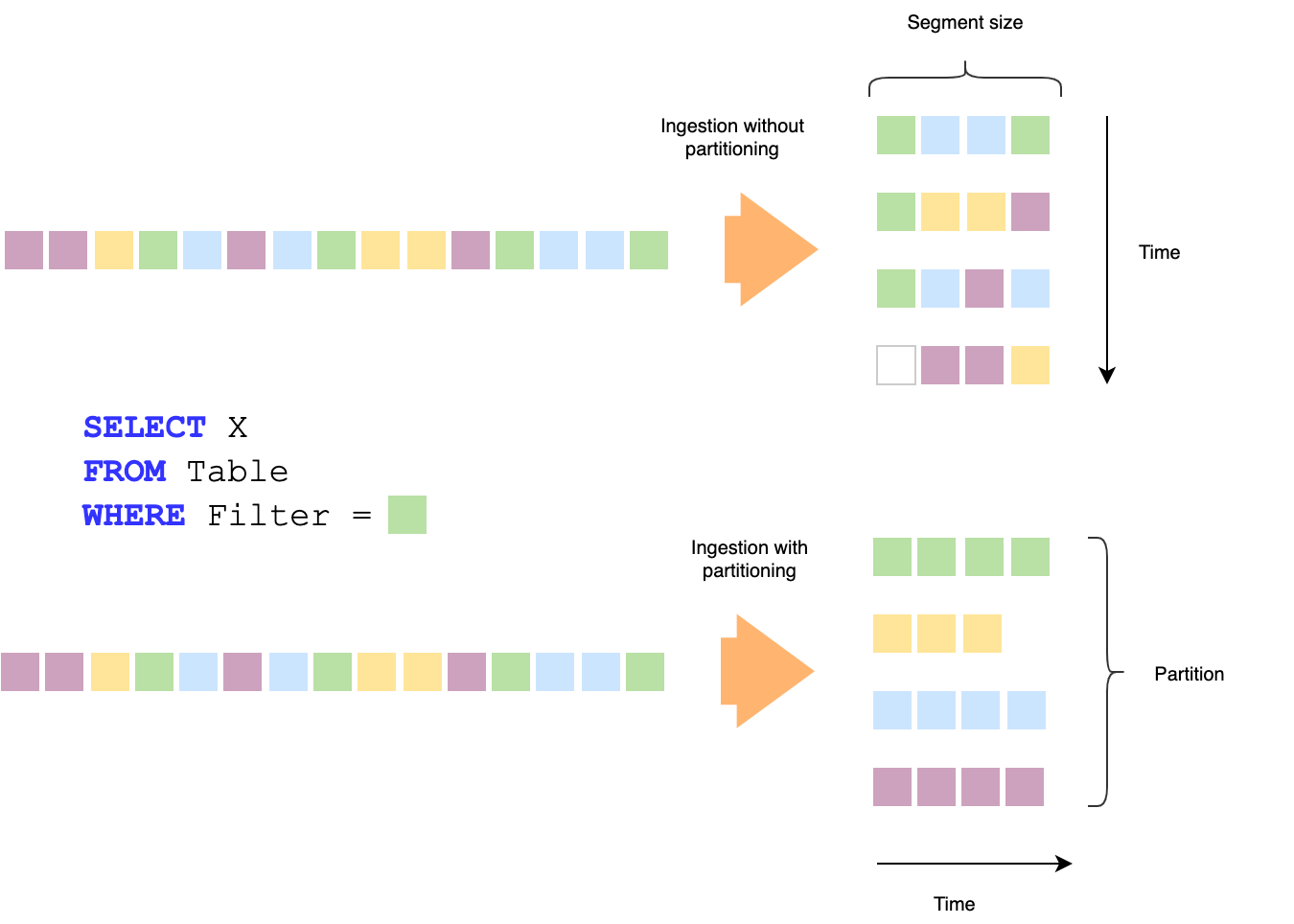
Two major data layout factors that contribute to query performance are segment size and partitioning scheme. We have seen up to 40 times increased speeds with production workloads with optimized data layouts when compared to non-optimized layouts.
Now you can set up auto-compaction rules that reshape your segments into optimal sizes with optimized partitioning schemes as you learn about your workload over time. Those auto compaction rules run continuously in the background so that newly arrived data is optimized over time.
This is a big step towards our ultimate goal of an auto-optimization system that constantly monitors the actual workload and optimizes the data layout.
In the following example, queries that filter on specific partitioning columns can quickly eliminate segments without actually reading them.
Types of use cases where this might apply are:
You use streaming ingestion but also want to take advantage of partitioning schemes that allow partition pruning.
You are appending data on a data source with partitioning enabled.
You have a sub-optimal hash partition spec with too many shards.
You want to optimize for a new query usage pattern without reingestion.
Making data ingestion easier
There are many features in 0.20 that aim to make data ingestion easier.
First, you can now use multiple sources for single ingestion. This allows you to combine data from CSV, Druid table, and any other supported sources into a single data source.
Second, hash partitioning now behaves like other partitioning methods, where you only need to specify the max number of rows. Previously, you had to determine numShards for hash partitions. This is now automatic.
Lastly, we improved the task slot usage metric to make it easier for you to monitor resource utilization of ingestion.
Druid web console data source view improvements
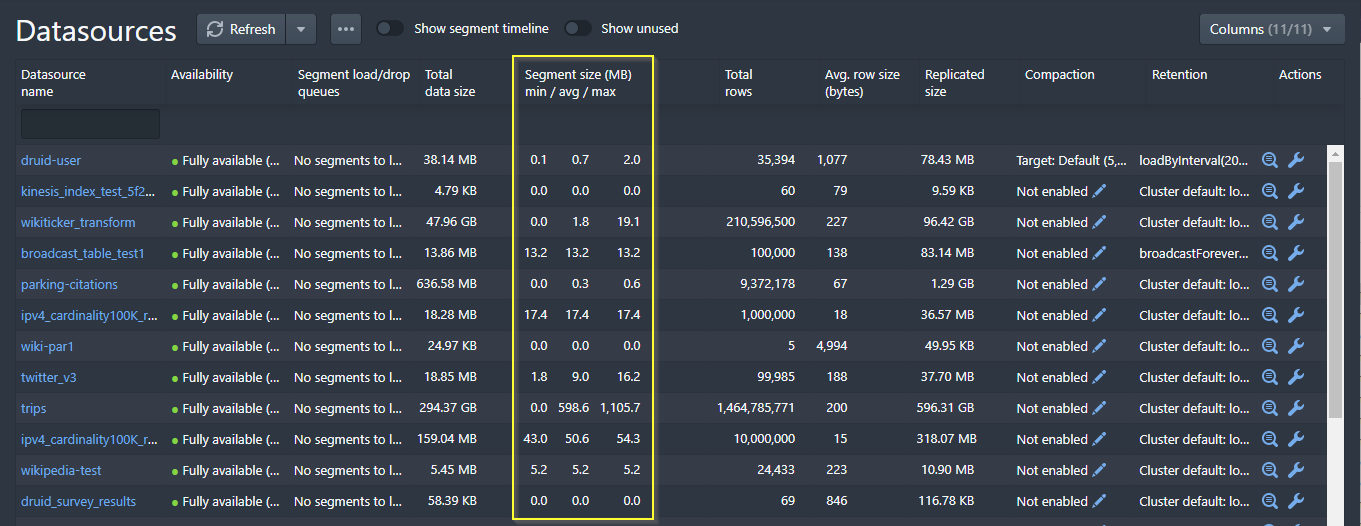
At the same time, we’ve changed the Druid web console to display a statistical distribution of segment size. If you see a significant difference between the minimum, average, and maximum sizes of the segment, then it’s a good indicator that compaction can help you improve query performance.
Druid web console query view improvements
We have also made numerous improvements to the Druid web console query view as well.
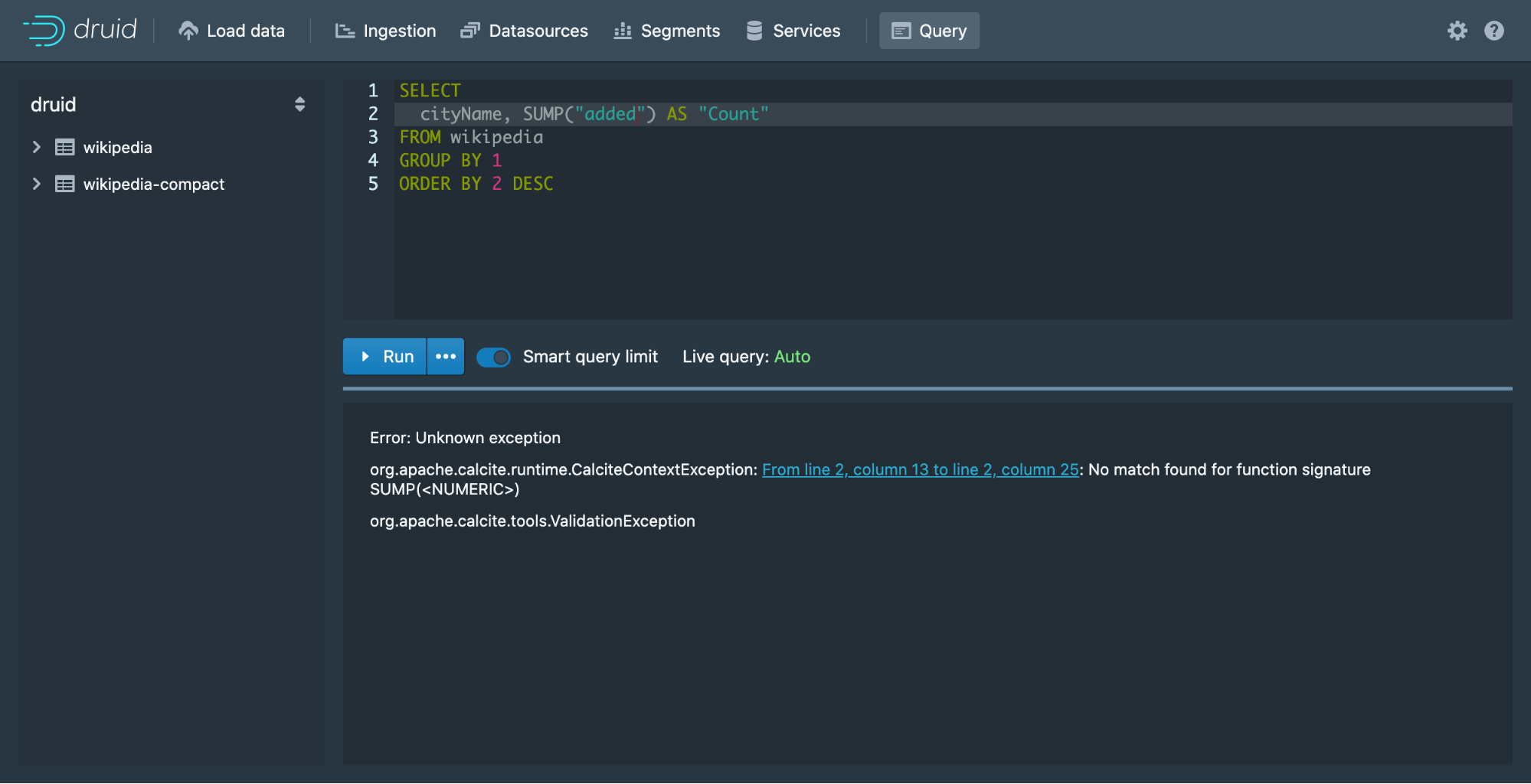
First of all, we made it really simple to find problems in query text. Now you simply click on the link in the error log view to jump to the right place in the query.
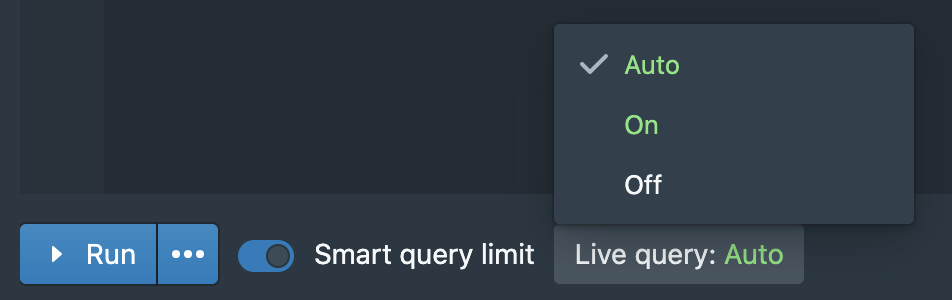
Second, the auto-run query has been replaced by Live query that automatically determines when to rerun the queries as you change filters.
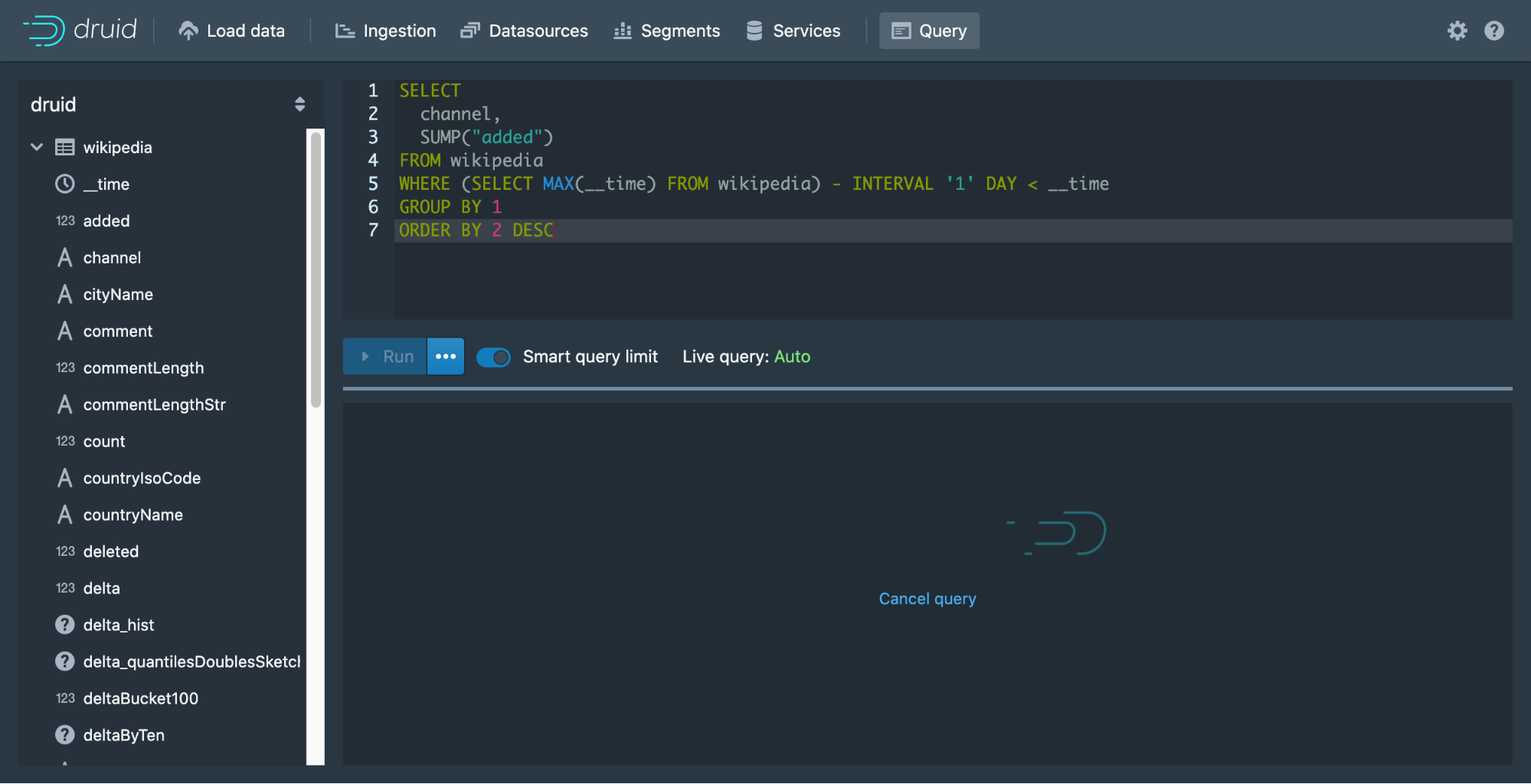
Third, you can easily cancel your queries to iterate quickly. In the past, if you made a mistake in the query, you had to wait until the query finished before you could make changes.
For a full list of all new functionality in Druid 0.20.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...