As Imply lore has it—to the extent lore does swirl the virtual halls of our distributed offices these days—the Druid project was named after the Druid character class in Dungeons & Dragons (DnD). In DnD, Druid is a shape-shifter, a character who can take on the form and abilities of animals.
Like the Druid class, data in Apache Druid is shape-shifting; it can take on the form and scope most relevant to answering the questions of the moment.
Imply Users: Tabaxis and Tortles
Over the course of Imply’s history, we’ve noticed that Imply users tend to fall into one of two types which — in the spirit of our Druid origin story — we can characterize as DnD classes as well.
On the one hand, we have Tabaxis. Tabaxis characters are quick and dexterous, with reflexes that allow them to move quickly, in strong bursts. They’re adventurous and curious.
These are users who want new features and product capabilities as soon as they can get them. They’re not afraid of trying new things. They rapidly expand their use cases and try to do new things on top of Imply, so they are constantly on the lookout for new capabilities. They prioritize the ability to get these new features and unlock use cases and solve new needs more than the risk of upgrading to a new feature or the cost involved in doing so.
On the other hand, we have Tortles. Tortles are slow to move but solid. Their shells give them a strong, stable defense mechanism against adversity.
These are users who are less interested in new things but favor stability and risk minimization. They have certain use cases that are limited in scope and that don’t often change from a functional perspective. The data doesn’t often need to change shape, for instance, or they have a limited set of known queries that they would ever need to be executed.
Tortles may use Imply as infrastructure, and aren’t expanding the functionality of the application built on top of it. They prioritize minimizing change and reducing cost of maintenance over getting new capabilities. In fact, they do not want any new capabilities because they introduce risk.
The two types differ in upgrade frequency and adoption of new capabilities.
Before November 2020, we released product updates on a quarterly basis. In hindsight this was a compromise between the interests of the two types, one which, unfortunately, served neither particularly well.
The Tabaxis types had to wait as long as three months to be able to even test an alpha version of a new feature. Tortles, on the other hand, would stick to a version of the product released at some point in time and rarely upgrade, which meant that we had to continuously maintain all versions of Imply released every quarter the same way. Over time, this takes a toll on Imply engineering bandwidth and affects the rate of patch delivery to all supported Imply versions.
New way forward
To better serve the needs of both types of users, we’re changing our release strategy. As of November 2020, Imply releases will follow one of two tracks: monthly Short Term Support (STS) releases and an annual Long Term Support (LTS) release.
The STS release aims to suit the needs of Tabaxis types, while LTS releases are geared for Tortles.
We’ve also changed our version naming scheme to match the new approach. Versions are now named <year>.<mo>, as in 2020.11 for the November release, and 2021.01 LTS for the 2021 long term support release.
The following summarizes the differences between the two tracks:
STS
Features Faster
For those who want to influence the short-term Imply product roadmap
New features every month
Fine-grained feature flags and feature lifecycle control
Ability to try out alpha/beta features on your own schedule
No batch releases (No patch releases (changes are incorporated in the next monthly release)
LTS
Stability & Security
For those who want to reduce cost & risk
Ensure stable workflows and applications
Monthly bug fixes for 1 year
Security fixes for 2 years
No alpha/beta features
No new features, no breaking changes
The tracks in action
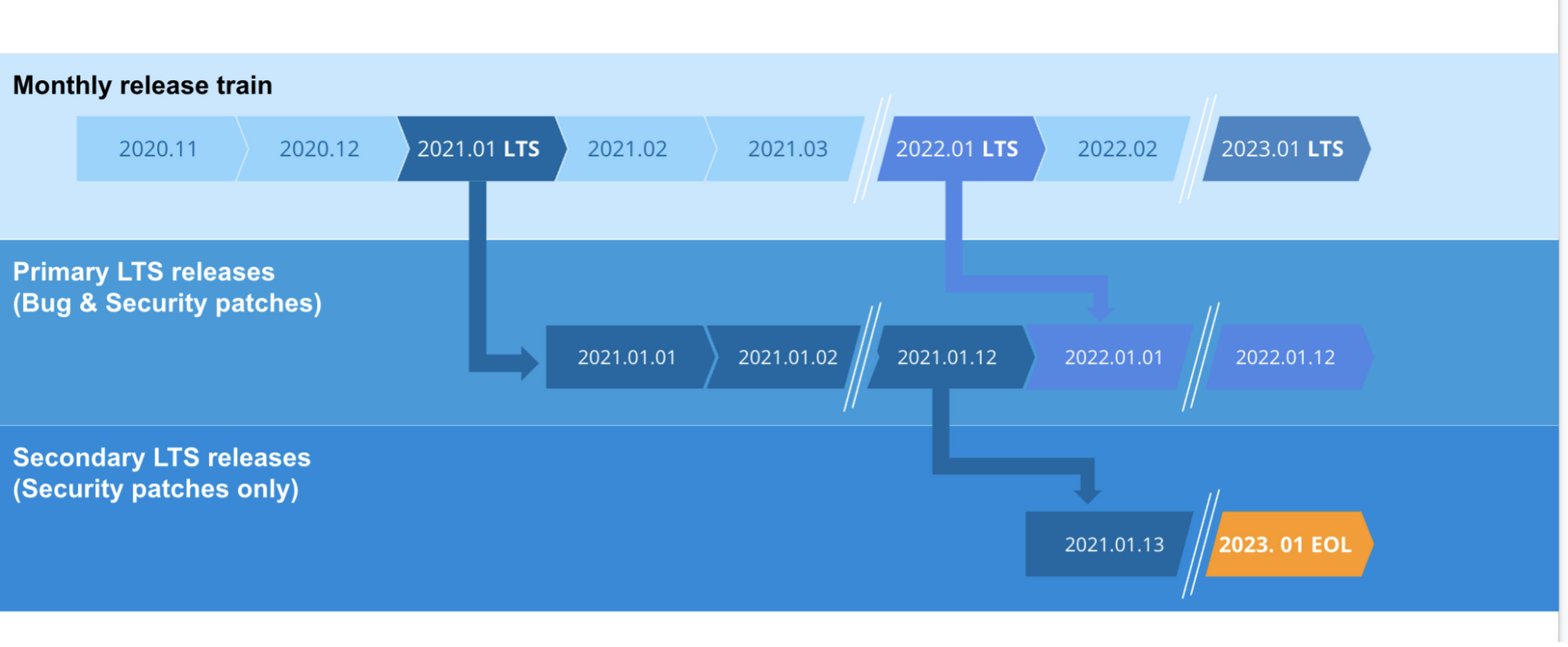
The following graphic shows the anticipated release cadence and versioning scheme for the two tracks over the next year:
Notice that the primary LTS release — that is, the latest LTS release — receives bug fixes and security patches for a full year. After a year, it receives important security patches only. At the end of the second year, the release no longer receives updates, and the release is considered end-of-life.
And they’re underway
We’ve already launched the new release strategy, with 2020.11 STS release now available. Soon we will have our first LTS version available.
We hope that a predictable release cadence and content clarity will improve maintenance planning and inspire confidence in Imply software updates, for the benefit of Tortles and Tabaxis alike!
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...