{kind=link}
Oct 17, 2024
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreA long time ago in a galaxy far, far away…
Someone had the bright idea to begin asking for metrics about their business….
The conversation probably went something like this: “Hey, remember when we planned those things, and then we did those things… did the, uh, numbers change the way we wanted?”
What followed was the creation of a global data analytics industry that spawned thousands of companies to answer this seemingly simple question.
The answer has been a *resounding* “definitely… maybe…”.
It’s been long known that metrics are critical for any business. Key metrics can vary from business to business, and range from sales figures, to product/user engagement, marketing campaigns, and everything in between. Businesses need to understand how their metrics change across many facets of their operations, and this is the core idea behind data analytics.
The easy part of data analytics is formulating questions. The hard part is finding answers. As companies grow, it is not uncommon that their data volumes and data complexity scales exponentially. It can be very challenging to find the right tool(s) for the job. Furthermore, people keep inventing new buzzwords so it’s impossible to tell what value add the latest machine learning / artificial intelligence / blockchain / edge computing thing is actually providing. In this post, I’m going to try to give you the high level picture of how the data analytics space has evolved and how we’re answering questions today. Why? I’ve spent my career in this space and have been both fascinated by and proud of its growth. Also, I work at a data analytics company and want you to buy our very excellent product.
Long before unicorns, free t-shirts, and brogrammers, people struggled to understand their business. They struggled because data analytics wasn’t yet a thing, and because of various technical limitations of the era (mainly limitations in database architectures: difficulties in querying across multiple disparate data sources, constraints in CPUs, memory, storage, and networks, and myriad other factors).
Even as businesses grew to understand the importance of data analytics, many still struggled to actualize insights because analytic workloads took valuable resources away from the transactional systems that were the backbone of the business.
Consider the following example. AwesomeCo has an awesome Point of Sale (POS) system, and a database they use to mail out advertising flyers. AwesomeCo has an awesome marketing team making awesome ads and they are spending a lot of money to create and distribute these ads. But, AwesomeCo has a problem: it has no way to see how advertising is directly influencing sales, which customer segments are actually responding to the ads, and the general efficiency of its marketing process. Is everything truly awesome? This central problem led to the creation of data warehouses, databases specifically created to efficiently answer analytics questions. Data warehouses promised to solve the underlying and pervasive problem at the heart of companies like AwesomeCo: the data required to run a business was locked up in siloed applications and inaccessible to decision makers.
Fun fact #1: loyalty cards at supermarkets were created when stores first gained the ability to get answers to their analytic questions, and wanted to tie promotions and buying behavior directly to an individual or household.

As the need for analytics grew, the industry moved swiftly through a number of design paradigms before eventually settling on batch Extract, Transform, Load (ETL) from Online Transaction Processing (OLTP) databases (the databases that power business products) to data warehouses such as Redbrick, Netezza, Greenplum, and many others. By the 90s, most companies had an architecture that looked something like this:
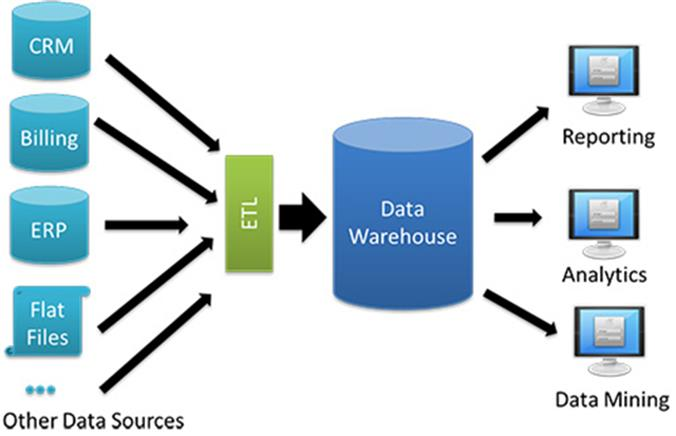
With CRM, ERP, and POS data available in a single location, decision makers could finally understand how the business as a whole was performing. The data warehouse gave corporations a way to unlock the data concealed within their many stovepipe applications.
For awhile, things were good, but not great. One big problem was because of that innocuous looking little step called ETL that I briefly mentioned before. The sad reality was that ETL was anything but innocuous or little. When I built a reporting database for Vail Resorts around the turn of the century, it took me 10 months to translate analytic reporting requirements and 32 separate data sources into a functional data mart for the marketing department. Although this tiny system stored only stored a few gigabytes of data, the intricacies are what made it ornery. But it could have been worse. My friends at other companies would tell me that it would routinely take 18 – 24 months to get an enterprise-wide data warehouse up and running.
The problem is obvious: you can’t make valid business decisions based on 18 month old data. Yet, that’s exactly what life was like a mere 15 years ago. Pull data from source systems (Extract), massage it just right (Transform), and deploy it into a data warehouse (Load). It was painful. The “T” part was especially intricate: data was stored in star or snowflake schemas and needed to be normalized into structures that were easier to report on.
Another problem was that as businesses grew to rely on their data warehouses, the warehouses faced increasing scale up challenges. The RDBMSs that formed the heart of data repositories of the time were architected to grow vertically on single machines, so more data meant more hardware, and more hardware meant bigger and costlier machines. Scaling up was extremely expensive and time consuming, so companies were forced to reduce the amount of data they were storing.
Fun Fact #2: Remember those loyalty programs? Do you also remember when some stores just stopped? It was because it was getting too expensive (I’m looking straight at you Oracle) and time consuming to store all the data, and it was taking too long to get meaningful information out of these systems.

As time went on, things didn’t get any better.
The web happened.
Social media happened.
Mobile happened.
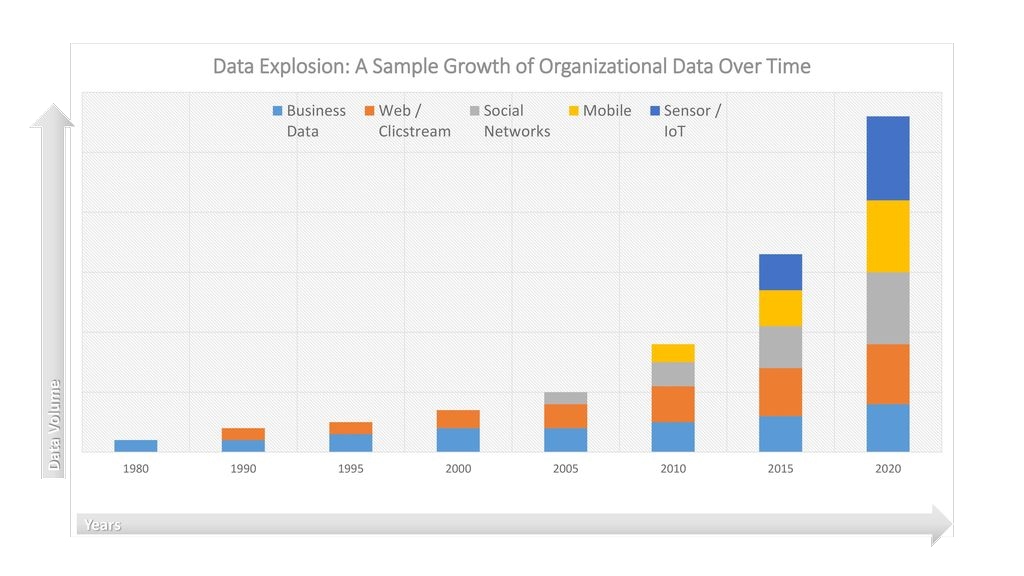
Image from Michael Fudge “Big Data And the Data Warehouse”
Legacy solutions struggled to process billions of transactions each minute. The problem magnified as volumes grew and the same number of transactions needed to be processed each second, and then each millisecond. There was simply too much data.

Companies searched for a cheap way to store this data on commodity hardware to reduce costs. They found a promising answer in an up and coming open source project called Hadoop. Hadoop consists of two main components, a distributed file system called HDFS, and batch data processing framework called MapReduce. Hadoop provided the foundation for Data Lake architectures.
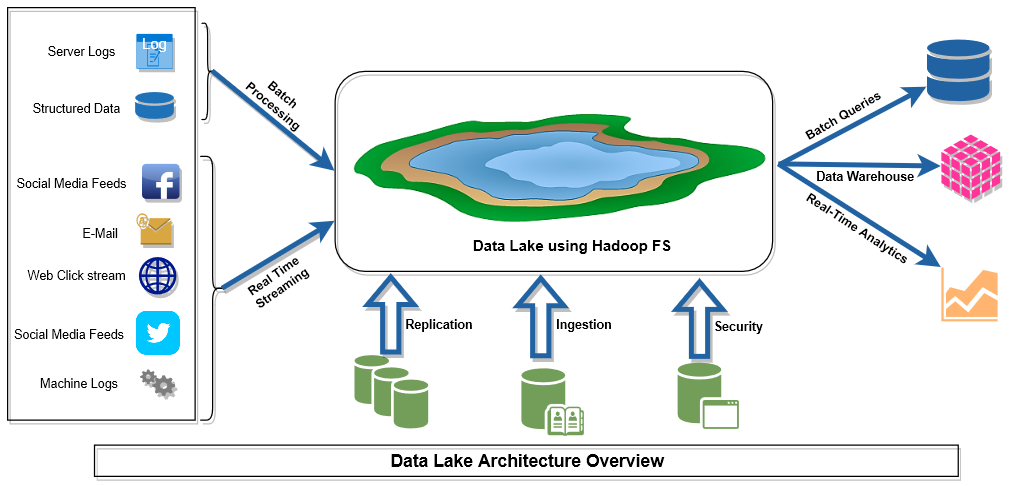
A data lake is a distributed file system that can store many different file types. Many modern query engines designed for data lakes embrace the idea that storage and compute are separate systems. The data lake acts as a central storage location for all of your structured, unstructured, and semi-structured data. In the most setups with data lakes, different query engines optimized for different workloads (warehousing, ML/AI, search, etc) connect to the data lake, pull data from it as needed for queries, and compute the answers to those queries.
The data lake gave us a relatively cheap place to store data, and removed the timeliness constraints presented by the data warehouse. We no longer had to structure data (or even use it right away), and that pesky T from ETL could take longer than our total load window for the day. The process shifted so that we can collect all the data, put it into Hadoop, and decide what to do with it later. ETL had given way to EL( and then eventually)T. Simply put, things got cheaper, faster, and more scalable.
Data lake architectures solved many of the scaling problems that plagued companies for years. Today, all of the public cloud providers offer a data lake and a variety of query systems that can pull data from the lake for queries. However, as with all great systems that see widespread adoption, people realized data lakes weren’t a panacea.
As data lakes became ubiquitous, people started naturally wondering, “hey, now we’ve made all these analytics systems work at scale, can we also make them way faster?” Although data lakes are scalable and cheap, they are not particularly fast at loading data, and there is a lot of performance overhead when downstream systems need to access data in lakes for queries. After all, Hadoop’s mascot is an elephant, not a jackrabbit. One of the biggest limitations of data lakes is that they fundamentally stored data in static files. For most businesses, especially ones that have invested heavily in digital products, data is not created as a static file, but as a continuous stream of discrete events.
At the same time data lakes gained momentum, a little known open source project spun out of LinkedIn called Apache Kafka started becoming popular as a way of collecting data from a system or application and delivering that data to the data lake. A part of the reason for Kafka’s popularity lay in the fact it could deliver events immediately after they occurred to downstream systems in real-time. Today, Kafka is one of the most widely adopted open source projects in the data space and has many similarities to the data lake: it is a storage and transfer system for real-time streams (as opposed to batch files). As Kafka has grown, some of the more forward-thinking businesses realized if query systems could connect to Kafka directly, and leverage Kafka as the central storage and delivery layer, they could build an entire end-to-end streaming analytics stack. This architecture could bypass writing to and reading from the data lake, thus providing end users with the ability to make much faster decisions on their data.
However, one last challenge remained to actualize the streaming vision: query systems, even modern ones, were built with static data in mind. To truly support streaming data and real-time workloads, they too would need to be reimagined.
I’ve given you a rundown of the evolution of data analytics technology and how business requirements drove us towards a more low-latency world. I want to now introduce the idea of the Data River, an end-to-end streaming analytics stack that will give us the ability to ingest real-time data, store it for the foreseeable future, and execute complex queries to access not just the stored historical data, but also brand new, freshly minted data, hot off the proverbial wire.
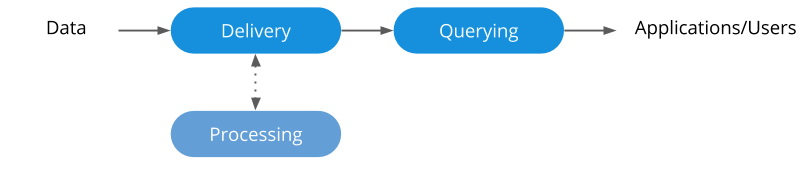
The data river architecture consists of 3 primary components:
In a data river, each piece of the stack works natively with streams and is designed to do a specific set of things very well. The combination of technologies is flexible enough to handle a wide variety of processing requirements and query loads.
You can read all about data rivers in detail here, the summarized ideas are as follows.
Data delivery systems are responsible for delivering events from one location to another. The most common open source data delivery system is Kafka. You can install Kafka producers on your servers that hold the data that needs to be analyzed, and deliver them directly to a Kafka cluster. Kafka will stream data from producers to downstream consumers, which in our proposed architecture, will be a data processing system.
Data processing systems that are designed for streams are known as stream processors. Well-known stream processors include Apache Flink, Spark Streaming, Kafka Streams, and there are many others. Although some of these systems can support simple analytic queries, stream processors typically do not store data in formats that are optimized for such queries. However, their core architectures are very well suited for data processing (ETL).
Data querying systems are primarily responsible for storing and analyzing data. While a traditional data warehouse can be considered to be a query system, data warehouses are a poor fit for streaming data. Data warehouses are not optimized for streaming ingestion, ad-hoc analysis, or workloads that require low-latency query response on real-time data. A more modern query system is Apache Druid, which has a reimagined architecture. Druid is built from the ground up for streaming ingestion and ad-hoc queries, for interactive exploration of real-time and historical data. Disclaimer: I work for Imply, the company behind Druid, so I naturally have a bias here.
The data river architecture is already starting to see plenty of adoption across a wide variety of industries. If one day in the future the data river becomes a buzzword you are sick of hearing, just remember you read it here first!
In the same way we have evolved from cassette tapes to Spotify, Duran Duran to Cardi B, and mullets to hipster beards, and Return of the Jedi to Solo, we have dramatically improved our ability to handle all data types over the past 3 decades. Whether it came as a sheer necessity from the changes to our digital lifestyle, or from the needs of corporations to monetize that digital data, architectures have evolved and the age of streaming data is very much here. If you are looking to empower your users with the ability to make decisions quickly across a wide spectrum of use cases, I hope I was able to convince you that the data river architecture is worth a look.
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn MoreThe Top Five Articles from the Imply Developer Center (Fall 2024 edition)
Build, troubleshoot, and learn—with the top five articles, lessons, and tutorials from Imply’s Developer Center for Fall 2024.
Learn More