Oct 17, 2024
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn More
One of the most important considerations when selecting an analytics platform is its suitability to conduct the required analyses over specific types of data within a given performance threshold. A helpful way to think about this is to utilize the concept of temperature-tiered analytics to align analytics needs with data architectures. Temperatures range from cold to hot, with hot representing data that must be collected and analyzed very quickly to yield maximal business value.
The temperature gradient concept comes into play when building data architectures around use cases and workflows.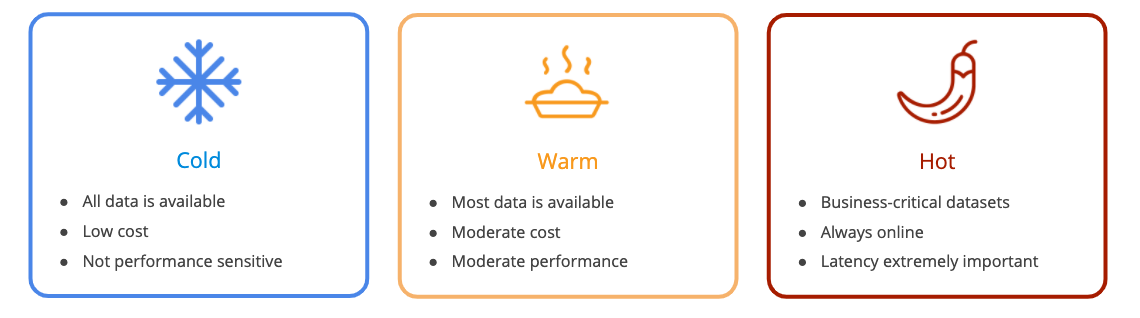
Cold data workloads are typically the default way that businesses think about data – collect it all and have it available to analyze later. Cold data is not sufficient to support performance-sensitive workflows, except as a historical baseline. Cold data is the stuff stored in a cloud or data lake. It has a low carrying cost; primarily the cost of storage. Cold data workloads are not very performance-sensitive, they’re price sensitive, and they support a wide variety of business activities.
Moving up the continuum, warm data workloads look to balance cost and performance to be good enough to answer most business questions in a timely manner, providing moderate performance at moderate cost. Warm is a level up from cold in that you know what you’re going to do with it and when you’re going to need it, you know what the value is when it is collected. You know it isn’t worth investing for true, real-time performance, but you also know that you can justify the investment over cold. In addition to storage, you might even dedicate some compute resources.
Hot analytics is the “new thing”, and where there is the most opportunity for companies to capitalize on the data coming out of digital transformation efforts. Think of hot analytics as fast and fresh. Many workflows require fast, sub-second query response times over fresh streaming, real-time data. Digital business processes – and it seems like every business is increasingly digital – thrive on fast analytics over fresh data, and they need a way to provide results with a level of performance and simplicity that empowers their employees.
Now, fast queries of non real-time or historical data are important too, but they don’t carry the same business urgency. Hot data consists of critical data sets that must always be online no matter the cost. Hot data typically requires dedicated resources, and latency is extremely important.
Workflows for hot data are oriented around real-time insights from monitoring and exploration. Monitoring tends to be dashboard driven, while exploration is driven by ad-hoc analytics tools that provide interactive slice-and-dice and drill down experiences. A hot data analytics platform can stream in fresh data for monitoring, and then also run very fast sub-second queries on historical data for comparison purposes, anomaly detection and alerting.
For example, clickstream analysis on a website or mobile app requires real-time streaming data ingestion to show what’s going on right now, coupled with sophisticated comparisons to historical data to measure and monitor changes over time. Application performance monitoring (APM) provides observability into current conditions by analyzing streaming data, and comparisons to the past by analyzing historical data. Both types of analyses require sub-second query performance for timely altering and to support iterative and exploratory workflows for root cause analysis.
Data sets are not inherently cold or warm or hot because that’s merely an artifact of how it’s used. This leads to a requirement for flexibility. It is very valuable to have a single system that can handle multiple temperatures because many times requirements change. Businesses align the temperature level with the value received from the data, and require a solution that allows them to transition between levels easily.
Hot analytics requires a different architectural approach across the entire stack. At the core is a real-time analytics database with the ability to do true streaming ingestion in addition to batching for historical reference data. Its compute and storage are more tightly coupled and enhanced by indexing to provide low-latency query response to business-critical apps and user-driven analyses. Also, hot analytics requires the UI layer not to interfere with the end-to-end performance so that user-driven exploration can occur.
The typical data warehouse relies on an architecture built for static reports and classic BI and analytics tools. They’re built around batches, and sometimes microbatches, and many can ingest every few seconds. They’re really good at batch ingestion, but it’s rare for them to have true streaming functionality, meaning the ability to connect to something like Apache Kafka with end-to-end millisecond latency, and this limits your ability to build a streaming data pipeline.
Their architectures also prevent you from leveraging the hot analytics on streaming data due to a lack of dedicated compute and storage resources. Some don’t co-locate resources and others don’t store data efficiently. Every architectural weakness adds up and queries start to take tens of seconds up to minutes rather than milliseconds. As data set size and user concurrency grow these times may extend.
It’s important to note that the newer cloud data warehouses have also decided to not use indexing to make performance more resource efficient by limiting what data is scanned, but rather to have decided to scan more data and then throw compute resources at the performance problem this creates. While additional compute will improve speed up to a point, it can also create a cost problem, since they tend to charge their customers based on compute usage. In short, the customer ends up paying for the resource inefficiency caused by this brute force approach. We will cover a recent benchmark below that quantifies this issue.
A real-time data platform must be cloud native, elastic, secure, self-healing, and upgradable without downtime. To be most effective at hot analytics, a real-time data platform must support pull-based streaming data ingestion and instant data visibility via vertically integrated storage, compute and visualization services. A real-time data platform must also leverage any and all performance optimizations, including secondary indexes.
There is a tendency for platform architects to separate storage and compute resources and scale them independently. However, there are deep implications of separate storage and compute resources on performance. A more sophisticated approach provides the benefits of both separation and unification through separate scaling for ingestion and querying to maintain performance.
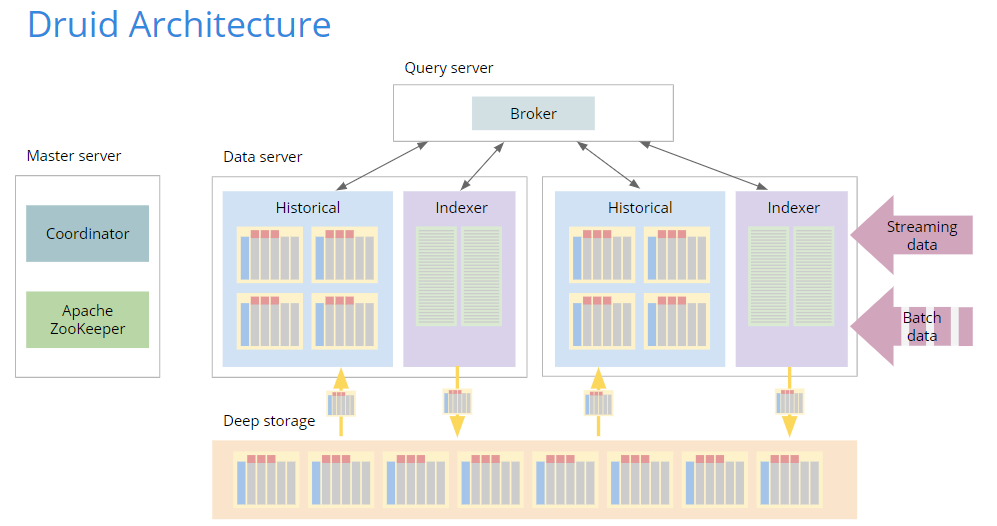
In an effort to address elastic scalability, today’s popular cloud data warehouses like Snowflake and Google BigQuery separate resources to an extreme. Apache Druid is different and unique in its approach. It doesn’t completely combine compute and storage like the classic enterprise data warehouses of yesteryear, nor does it completely separate them like Snowflake and BiqQuery. Instead, Druid takes a hybrid approach that integrates a cloud storage layer (an S3 or HDFS deep storage resource) and preloads data to keep query response snappy.
It’s the separate storage system that enables Druid to scale elastically without downtime while maintaining sub-second query response. Organizations can scale up, scale down, optimize data location, and all those other things DBAs love to do. By preloading data, Druid can leverage the cost advantage of cloud storage and the performance advantage of local data.
A real-time data platform must support pull-based ingestion in order to provide fresh data for hot analytics. Most popular cloud data warehouses don’t offer real-time ingestion, and if they do, they limit latency or throughput. In contrast, Druid offers massively scalable pull-based ingestion that enables tens of millions of inserts a second in true real-time.
A real-time data platform must support secondary indexes to enable lightning-fast and cost-effective scanning. Cloud data warehouses don’t offer indexes beyond the partition key. They boldly frame this as a strength by claiming in documentation that they don’t need secondary indexes because they’re so fast to begin with, but the logic here is pretty shaky. Regardless of how fast a system can scan, secondary indexes are faster. Think about it: Not scanning is always better than scanning. No surprise, Druid supports space efficient compressed secondary indexes.
What are the performance implications of these architectural choices? We recently performance tested Druid and BigQuery using the Star Schema Benchmark. We ran Druid on a very small 3-node cluster and outperformed BigQuery by 10 times or more. Druid’s usage of secondary indexes played a crucial role in performance optimization because those queries had a lot of filters in them.
Druid offers additional performance-boosting advantages for hot analytics:
Druid’s unique architectural approach to the organization, utilization, and management of storage and compute resources, combined with features such as intelligent resource management/dynamic laning, approximate algorithms, server tiering, real-time ingestion, enables it to serve as the foundation of a cost-effective high-performance real-time data platform for hot analytics.
Druid is not only fast, but can scale with growth in data set size, streaming speed and user concurrency. There are companies around the world like Netflix, Walmart and Twitter running hot analytics and enjoying sub-second responses to SQL queries on clusters of thousands of Druid servers.
As you embark on your journey to address hot analytics, I encourage you to consider Druid as an addition to your analytics architecture. Imply was founded by the creators of Druid and the Imply platform is a full-stack solution for hot analytics. Please sign up for a demo, download our distribution, or sign up for a trial of Imply Cloud.
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn MoreThe Top Five Articles from the Imply Developer Center (Fall 2024 edition)
Build, troubleshoot, and learn—with the top five articles, lessons, and tutorials from Imply’s Developer Center for Fall 2024.
Learn More