Our intention was to help Druid database users and provide guidance on how to control the TTL of their data within Druid (BTW, over time, we were happy to learn that it helped quite a few people…).
In the “Kill Tasks and the art of deep storage maintenance” section, we explained what are Kill Tasks and what are the benefits of using them (hint – it involves money, and potentially lots of it…).
We also mentioned that, as opposed to Load Rules and Drop Rules which are applied automatically, you need to execute Kill Tasks yourself.
However, that’s not entirely accurate, and that’s why I’m writing this second part. I hope it’ll help folks out there, using Druid, to further control and manage their data.
Kill Tasks – logical vs physical delete
As the documentation states, “Kill tasks delete all metadata about certain segments and remove them from deep storage”.
As Dana and I described in the previous post, Kill Tasks will only operate on segments that are marked as “unused” (i.e used=0) in the metadata store. Segments can be marked as “unused” for a few reasons, but usually it would be a result of a Drop Rule.
Once a segment has been marked as “unused”, it will be offloaded from the cluster (specifically, from the historical nodes).
However, marking a segment as “unused” is not enough, since Druid still retains an entry for that segment in the metadata store, and retains the segment file itself in the deep storage.
Only after a Kill Task has removed the segment file from the deep storage and removed the matching entry from the metadata store, can we treat that segment as deleted. One way to think about this is “logical delete” vs “physical delete” – marking a segment as “unused” is basically logically deleting it, while removing the segment file from the deep storage and removing the matching entry from the metadata store is essentially physically deleting it.
It’s very important to keep in mind that once unused segments are deleted from deep storage, they can’t be restored (unless you keep backups of your deep storage and matching backups of the metadata store).
Can Druid do that for me?
At the very basic level, Kill Tasks can be executed manually (see this tutorial), or scheduled periodically using workflow management tools like Apache Airflow.
But what if you don’t want to manage Kill Tasks on your own (even if it’s via a workflow management tool)? Can Druid manage that for you? The answer is: Yes! By using a few settings (which we’ll describe below), you can have Druid manage this work for you automatically!
Automatic Kill Tasks FTW!
So let’s go through the steps you need to take, to set-up automatic Kill Tasks.
First, you’ll need to set the following coordinator runtime properties (see the relevant docs):
druid.coordinator.kill.on – the coordinator will submit Kill Tasks only when this is set to true. The default is false. Naturally, all the following properties are relevant only if druid.coordinator.kill.on=true
druid.coordinator.kill.period – how often the coordinator will submit Kill Tasks. The default is P1D (=1 day), which is appropriate in most cases. Note that this value must be greater than druid.coordinator.period.indexingPeriod, which defaults to PT1800S (=30 minutes).
druid.coordinator.kill.durationToRetain – do not kill unused segments in last durationToRetain. Essentially, kill only unused segments older than durationToRetain (e.g 1 day). The default is PT-1S (=1 second), which is invalid – it must be greater or equal to 0.
druid.coordinator.kill.maxSegments – the maximum number of unused segments to kill per Kill Task submissions. The default is 0, which is invalid – it must be greater than 0.
Note that these settings require restarting the coordinators in order to take effect.
Next, you’ll need set the following coordinator dynamic properties (see here):
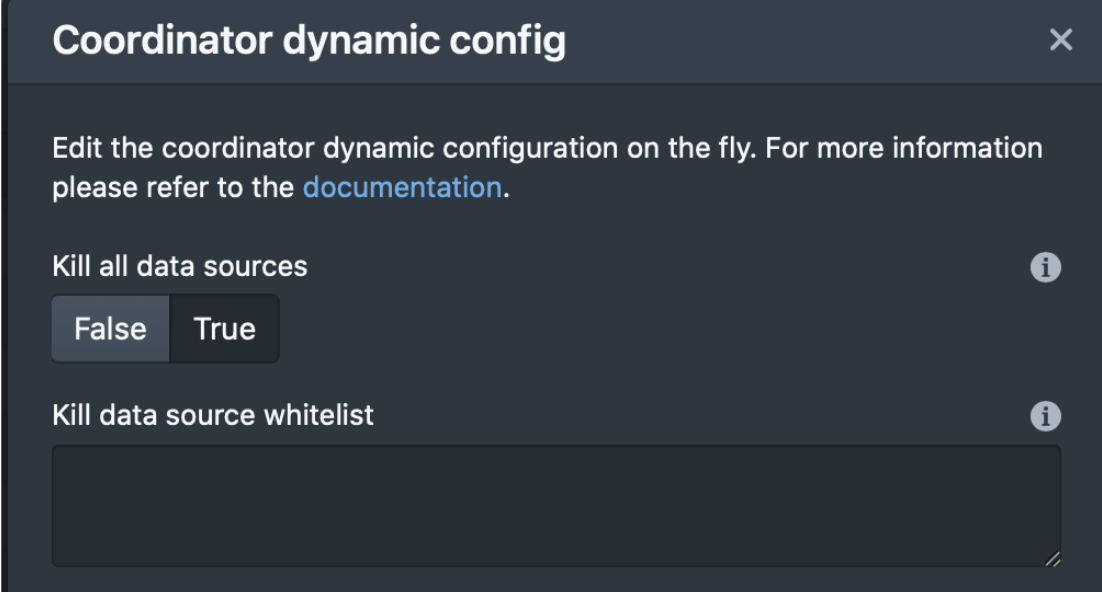
killAllDataSources – send Kill Tasks for all data sources. The default is false. If you set this to true, you must not specify killDataSourceWhitelist (or provide an empty list).
killDataSourceWhitelist – send Kill Tasks only for a specific list of data sources. There is no default. This can be a list of comma-separated data source names or a JSON array.
Similarly to the coordinator runtime properties above, these dynamic properties are relevant only if druid.coordinator.kill.on=true.
The easiest way to set these dynamic properties is through the Coordinator dynamic config screen on Druid’s web console (as shown below), but one could potentially do that via an API request (see here).
As Dana and I mentioned in the previous post, not setting-up Kill Tasks can result in storing a lot of redundant data in deep storage, which in turn can significantly increase costs. Since Kill Tasks only delete unused segments, you’d want to delete as much redundant data as possible, so you’d probably want to run Kill Tasks for all data sources, and you’d want to set druid.coordinator.kill.durationToRetain to a relatively low value (e.g a couple of days).
Final notes
Similarly to ingestion tasks or compaction tasks, Kill Tasks require MiddleManager worker capacity (or “slots”) to complete a run (one slot per task), see here. To get some better understanding on worker capacity, check out the great blog post my colleague, Venkatraman Poornalingam, wrote, on best practices for Druid auto-compaction. I also encourage you to view the recordingYakir Buskilla and I gave at the Virtual Druid Summit last year, where we discussed various guidelines and tips around using Druid in production (including data retention and deletion). We’ll be giving an adjusted version of this talk at the upcoming Berlin Buzzwords on June 17th (https://2021.berlinbuzzwords.de/session/casting-spell-druid-practice).
I hope this post will help you to better control and manage the data stored in your Druid cluster, and I’ll be happy to hear your feedback, so feel free to reach out to me over LinkedIn or Twitter.
Happy Druiding 🙂
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...