Column stores such as Druid have the ability to store data in individual columns instead of rows, and can apply different compression algorithms to different types of columns. With the Druid 0.9.2 release, Druid has added additional column compression methods for longs to significantly improve query performance in certain use cases. In this blog post, we’ll highlight how these various compression methods impact data storage size and query performance.
To illustrate these new methods, let’s first consider the example event data set shown below:
Timestamp
User
Country
Added
Deleted
Delta
1471904529
A
C
1274
0
1274
1471904530
A
O
27
0
27
1471904531
B
U
1186
1977
-791
1471904532
C
N
4
557
-553
1471904533
D
T
7
0
7
1471904534
E
R
9956
412
9544
This data set consists of a timestamp column, a set of string columns (User,Country) that queries frequently group and filter on called “dimensions”, and a set of numeric columns (Added, Deleted, and Delta) that queries often scan and aggregate called “metrics”. In previous literature, we’ve covered what compression and indexing algorithms we apply to dimensions. In this blog post, we’ll focus on our recent improvements for long columns.
Existing Compression Strategies
In our example above, each long takes 8 bytes to store. For a 5,000,000 row table, an uncompressed column would require roughly 40MB of space. Prior to 0.9.2, Druid only leveraged lz4 and lzf compression for longs.
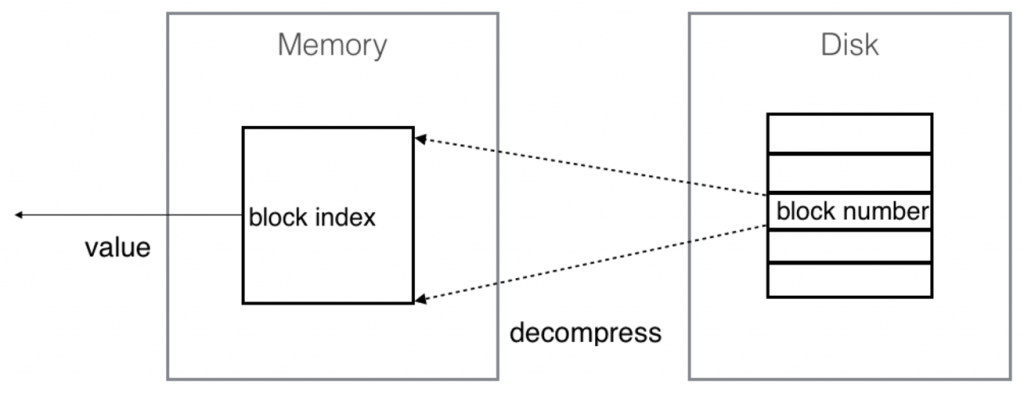
Compression is done by dividing a column into blocks of a given size (currently 0x10000 bytes, or 8192 longs). Each block is compressed and persisted to disk.These compressed columns are memory-mapped, so to read a value in a column, the block that contains the value must be loaded into memory and decompressed.
An inefficiency arises in that we must decompress the entire block even if we only need to read a small number of values within a block, for example, if we are filtering the data. The overhead for decompressing and copying a block from disk to memory is the same as if you were to read all the values in the block.
A natural improvement here is to use a compression technique that allows for direct access from file so we don’t need to do unnecessary block decompression and byte copying to access sparse data.
Direct Access Strategies
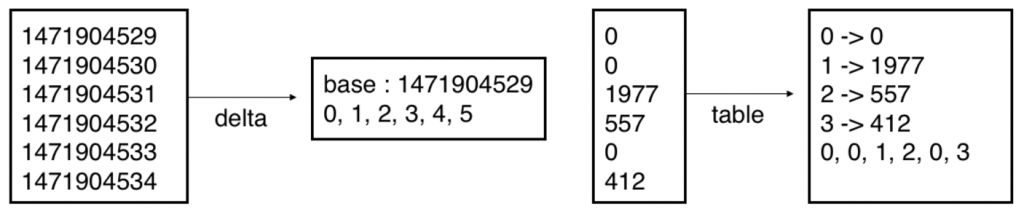
To allow direct data access, an important feature we must have is the ability to quickly access the block of data that contains the values we seek, or otherwise known as an index into our data. A simple way to achieve this requirement is to ensure all blocks, and hence, all values in the blocks, are the same length. However, long values don’t always require 8 bytes for storage.Using 8 bytes to store a value such as 0x1 is waste. Thus, to efficiently store values, we’ve adopted two strategies from Apache Lucene: delta and table compression. Delta compression finds the smallest value in a set of longs and stores every other value as offset to the smallest value, while table compression maps all unique values to an index and stores the index. These compression algorithms are shown below:
Both strategies have their limitations. Delta compression cannot handle data with offsets that exceed the maximum long value, and table compression cannot handle high cardinality data as storing the lookup would be costly. Given that choosing a format is conditional, we’ve introduced an auto strategy that scans the data for its maximum offset and cardinality, and determines whether to use delta, table, or none compression.
Trade offs
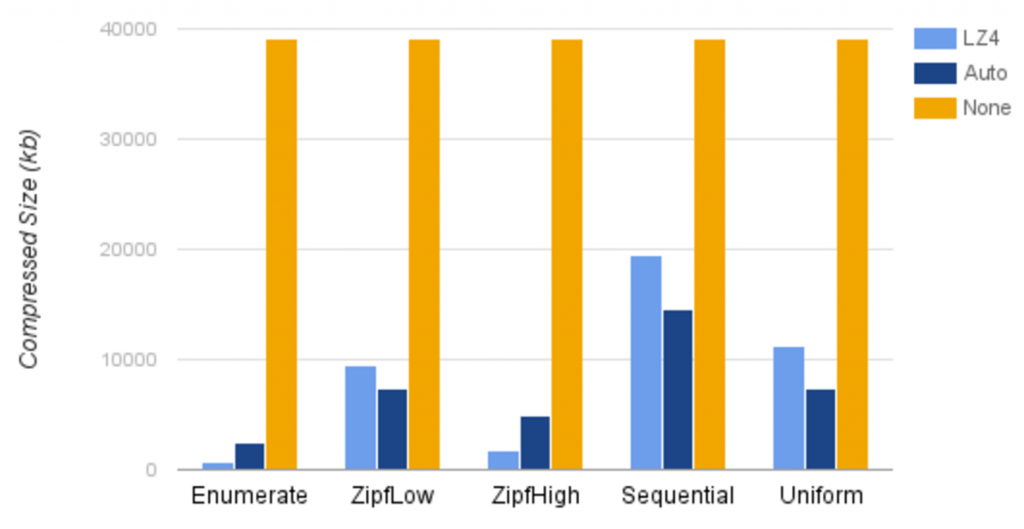
The graph below compares the auto, lz4, and none compression strategies using generated data sets with 5,000,000 values each.
Data Distributions
enumerated : values are from only a few selections, with probability heavily skewed towards one value
zipfLow : zipf distribution between 0 to 1000 with low exponent
zipfHigh : zipf distribution between 0 to 1000 with high exponent
uniform : uniform distribution between 0 to 1000
sequential : sequential values starting from a timestamp
The table below shows the bits per value for the auto strategy:
Enumerate
ZipfLow
ZipfHigh
Sequential
Uniform
4
12
8
24
12
Please note that since the none strategy doesn’t perform any compression, its size is the same for all data distributions. The auto size is directly proportional to the bits per value. lz4 performs very well for the enumerate and zipfHigh data distributions, since these distributions contain the most repeating values.
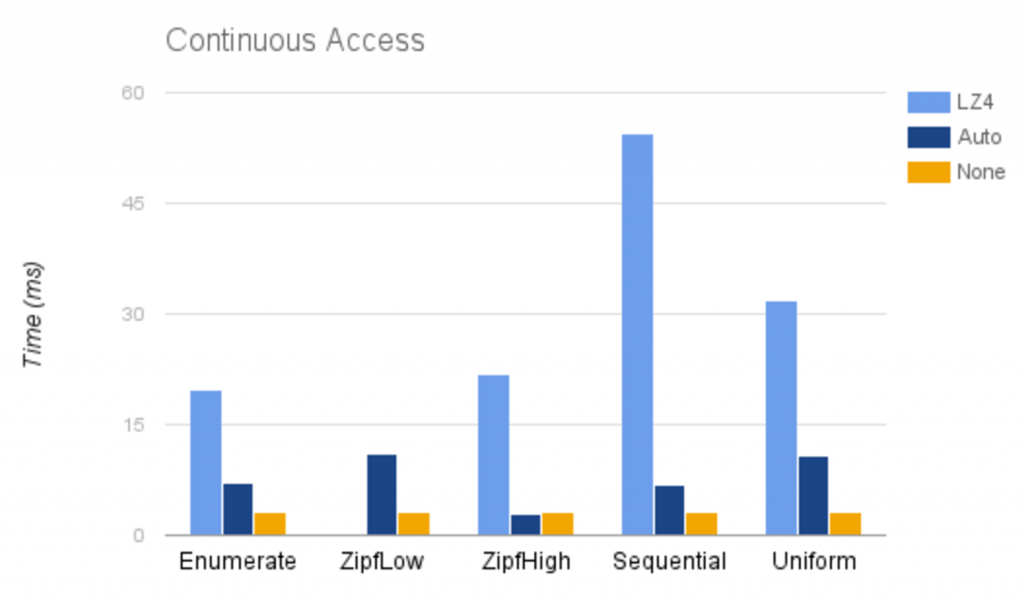
Below we illustrate performance results for sequentially accessing all values once:
Again, the none strategy has the same performance across all distributions, since it always reads 8 byte long values. The auto strategy performance is directly proportional to the performance of the corresponding bits per value on the graph above. lz4 performance is mostly dependent on the decompression speed for the data set, since the reading is always done on the 8 byte values.
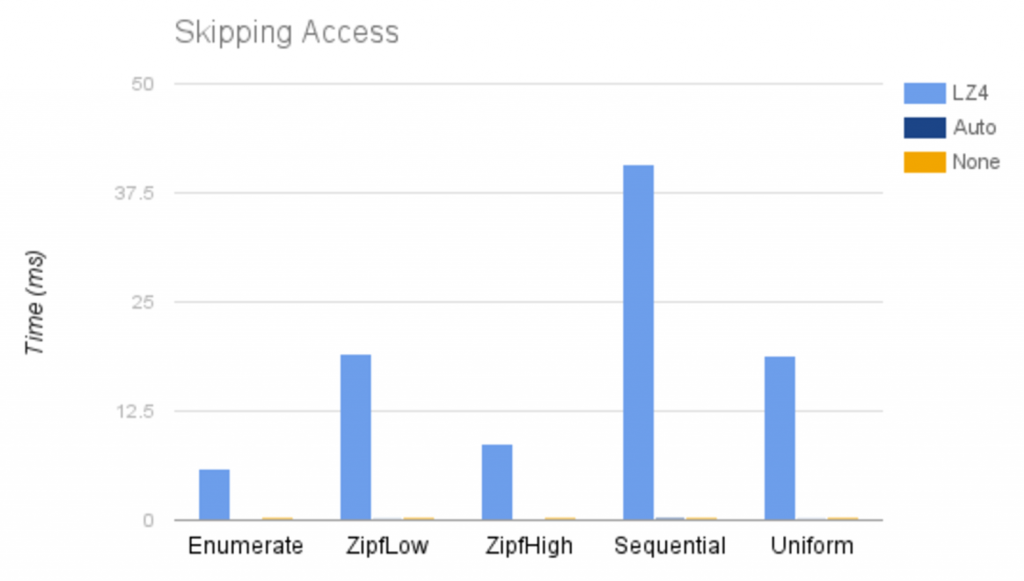
Below are the performance results for sequentially accessing values while skipping randomly between 0 to 2000 values on each read:
Here we can see how direct access strategies (barely visible) greatly outperform block based strategies for sparse reads.
Combining Strategies
When comparing compression techniques such as lz4 to delta and table, it is important to distinguish that lz4 can operates on blocks of bytes without any insight on the context, while delta/table compression (with variable size values) requires knowledge of the data.
We can integrate these different compression together and leverage multi-stage compression, where we can perform a byte level compression such as lz4 first, and then use a type specific compression such as auto after.
In Druid, we’ve decided to name byte level compressions such as lz4 “compression”, and data level compressions such as delta/table “encoding”.Compression strategies include lz4, lzF, and none. Encoding strategies include auto, which chooses between delta and table encoding formats, and longs, which always store a long as 8 bytes.
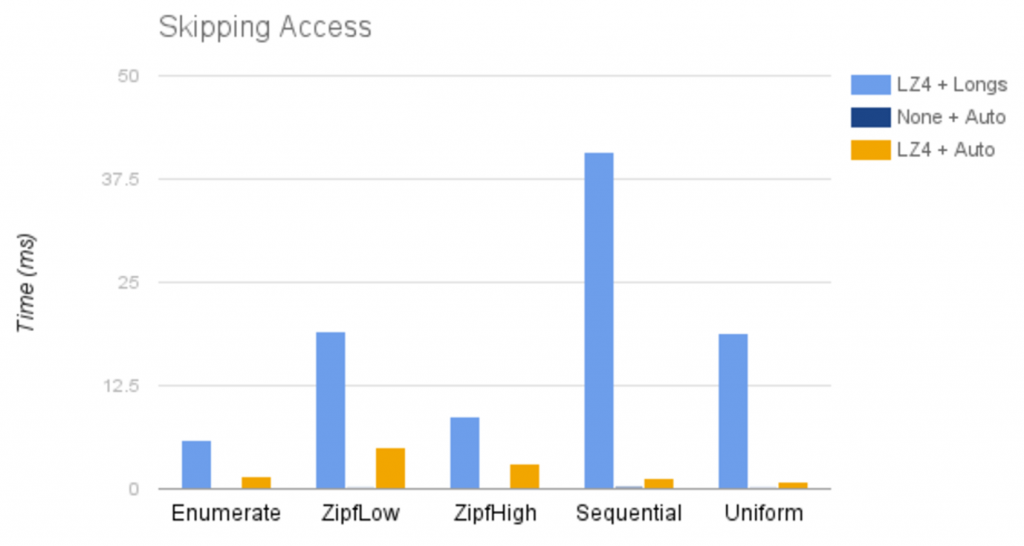
Our results with lz4 compression and auto encoding is shown below:
Looking at the results, it might seem strange that lz4 + auto performs so much better than lz4 + longs for skipping data, as the file size and performance for continuous data is comparable. This can be explained by breaking down the total reading time in the block layout strategy, which consist of lz4 decompression + Byte Buffer copying + reading decompressed values. lz4 + auto has better performance for decompression, while lz4 + longs is faster at accessing data.When reading continuous data, these differences more or less cancel out, causing performance between the two strategies to be similar. When reading sparse data, the accessing data portion is basically gone, and the decompression time difference is shown.
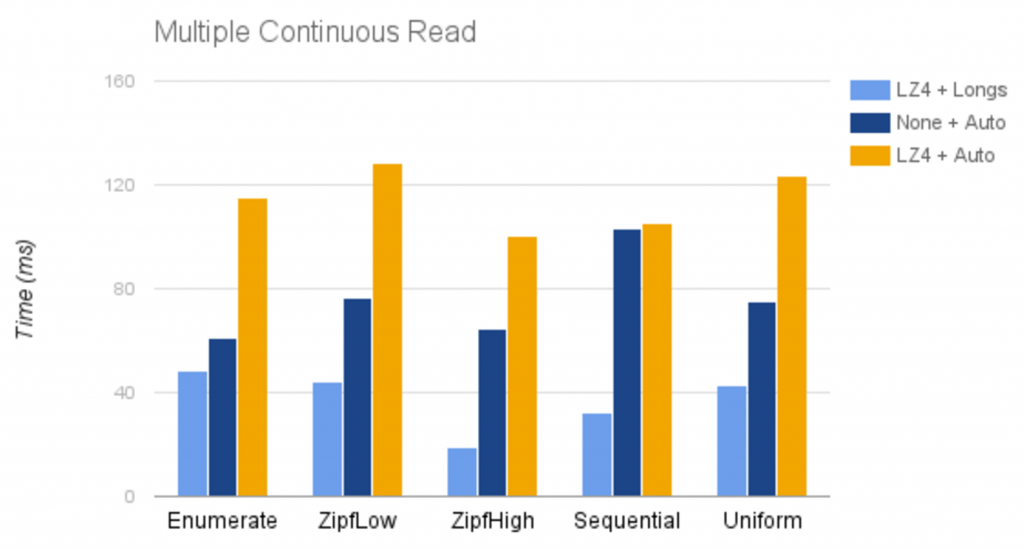
One interesting thing to note is what would happen if each value were read multiple times, for example if a query required multiple aggregations on the same column. In such a case, the reading performance would be much more significant, and lz4 + longs would have better performance than lz4 + auto, as shown below:
Recommendations
Unfortunately, there is no one compression and encoding combination that performs the best in all scenarios. The choice is highly dependant on the value distribution of ingested data, storage vs. performance requirements, and issued queries. However, we do recommend four combinations depending on the use case:
lz4 + longs (default) : good compression size for most cases, worst performance for heavily filtered query, good performance if the column is used by multiple aggregators that fully scan the data
lz4 + auto : average between lz4 + longs and none + auto. Occasionally offers better compression than lz4 + longs, and usually better compression than none + auto. This choice is better for filtered queries compared to lz4 + longs, and worse for queries that have multiple aggregators for the same column.
none + auto : offers better compression compared to none + longs, but much worse compression compared to lz4 for highly repetitive data. Good performance for reading in general.
none + longs : requires the most storage space (sometimes magnitudes higher than choices for highly repetitive data), but almost always performs better for all queries.
Finally, as part of this work, we’ve created a Druid tool that can scan segments and benchmark different compression options. You can use it via:
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...