Why Vertica Customers Adopt Apache Druid for Real-Time Analytics
Jan 13, 2020
Rob Meyer
If you are a Vertica customer, you probably already know this. Vertica is not built for real-time operational analytics at scale.
If you do not know Vertica very well, you might be surprised. This statement may seem controversial. It’s not. Nearly ¼ of Imply customers were existing Vertica customers who purchased Imply, a commercially supported version of Apache Druid, because they were trying to implement operational analytics and hit limitations with Vertica. Other Vertica customers also use open source Druid and self-support.
Do not misunderstand me. Vertica is definitely one of the better enterprise data warehouses (EDW) on the market. It was one of the first horizontally scalable columnar databases. We have happy joint customers with petabytes in Vertica. But Vertica was built for specialized analytics teams who focus more on historical analytics and load the data via batch-based data ingestion. It was not built for real-time intelligence.
Real-time intelligence involves delivering real-time alerts and information to workers or customers, and giving them the tools to monitor, interactively analyze and act on events as they happen. It requires real-time monitoring combined with ad hoc, time-based, and search-based analytics in a single user interface (UI) that sits on top of live, streaming data.
The Vertica Challenge – Performance and Scalability for Real-Time Analytics
When I have talked to architects in some of our joint customers about Vertica, they consistently brought up two sets of challenges. First, Vertica can be challenging to manage at scale. Specifically, they mentioned that Vertica:
Is very hard to reconfigure to change data retention policies
Is very hard to prioritize multiple workloads on a shared instance
Requires a lot of specialized expertise
Generally, these are acceptable challenges, in part because most EDW products have similar challenges, regardless of whether they are deployed on premises or in the cloud. These companies solved the problems by spending more money to staff a specialized team to manage Vertica for their users. Many of the analytics Vertica delivers are worth a lot of money.
The second set of challenges they mentioned are what make Vertica unusable for real-time analytics at modern scale. The top issues they mentioned were that Vertica:
Has scalability limits on real-time streaming data ingestion
Is hard to tune via partitioning and other techniques to improve query performance and scalability
Does not support a large number of simultaneous users or queries well
Let’s dig into each issue.
Vertica (Micro-)Batch Streaming Data Ingestion
When Vertica was created in 2005, it was designed for handling batch workloads at scale, not real-time ingestion. Back then, most analytics architectures were not built on streaming data architectures. Today’s streaming technologies that are used for analytics, such as Apache Kafka, or Amazon Kinesis, had yet to be invented. Vertica has not been re-architected to support real-time streaming data at scale, and has known limitations in this regard. One joint customer in the advertising and media industry needed to load 20 terabytes per day from Kafka, and the Vertica Avro driver just couldn’t keep up. One way Vertica tried to add scalability to streaming ingestion was by releasing the Parallel Streaming Transformation Loader (PSTL), which is a separate Spark-based application for Kafka ingestion. The challenge is that PSTL, like other (micro) batch-based solutions, does not address latency. You do not get real-time visibility because there’s a delay between ingesting the message and having it appear in queries in Vertica.
Druid Real-Time Streaming Data Ingestion
Druid was originally designed for use by large digital advertising exchanges, which place some of the world’s most extreme performance demands on streaming ingestion speed and query speed at high concurrency. Druid ingests millions of events per second in production at companies like Snap, Twitter and Pinterest. With Druid, each message is written separately and is immediately visible in memory for analytics.
Vertica Performance and Scalability for Real-Time Analytics
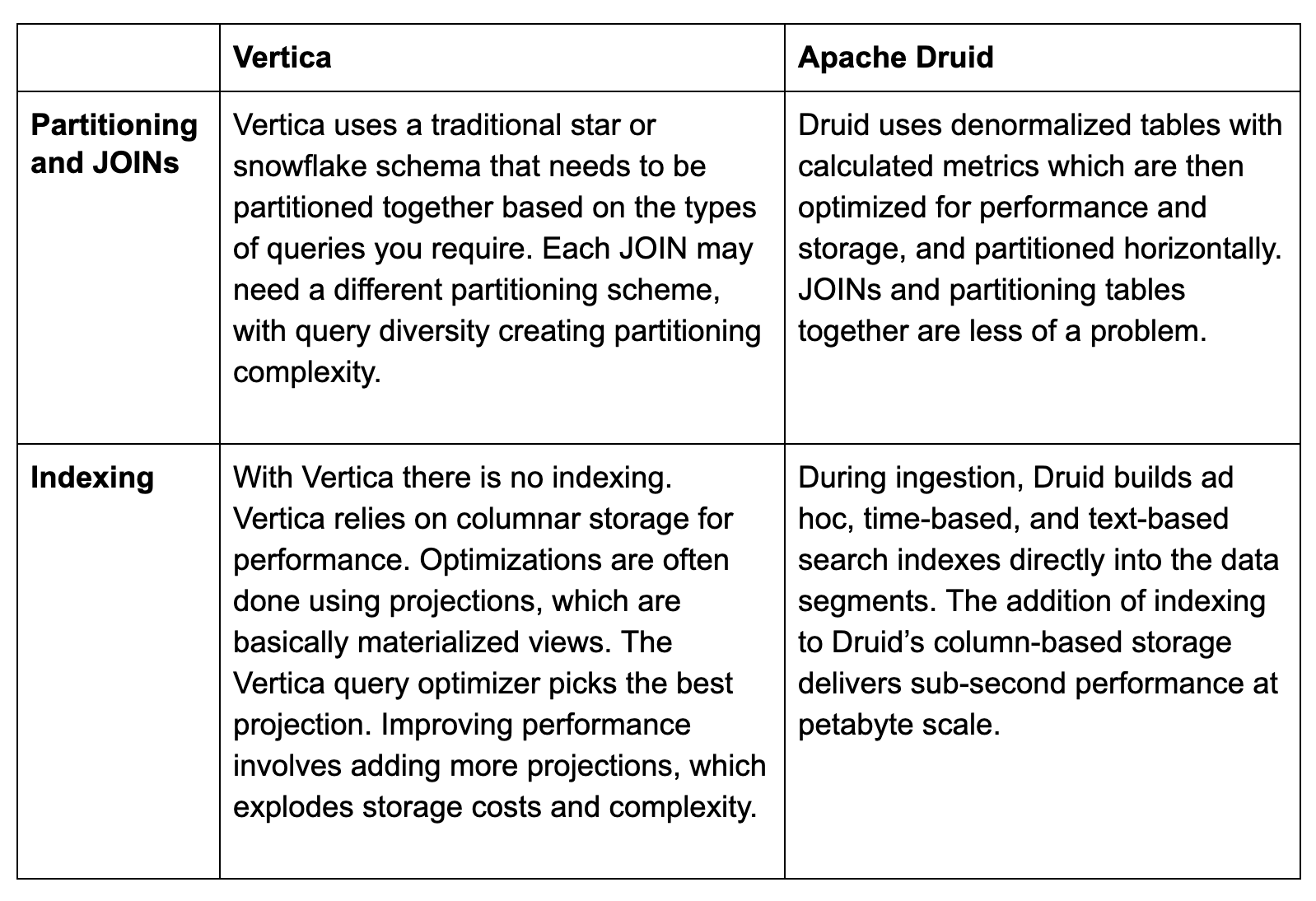
At first glance, Vertica seems to have a good architecture for low-latency analytics. It ingests data initially into (row-based) segments in memory, and eventually onto columnar segments on disk. But Vertica relies on a star or snowflake schema, as do all data warehouses. Partitioning tables to scale storage horizontally requires complex partitioning to make JOINs work across tables without creating a lot of network traffic.
Also, Vertica does not index. It relies on columnar storage for speed, and creates projections, which are basically materialized views, to create a faster columnar storage format. For most of our joint customers, the combination of partitioning complexity, network traffic and columnar storage without indexes prevented them from delivering sub-second performance long before they reached petabyte scale.
Druid Performance and Scalability for Real-Time Analytics
Druid is designed for really fast, structured operational analytics, including alerting, ad hoc, search and time-based analytics. It is not designed to be a general purpose data warehouse; it’s more like an OLAP data cube for streaming big data. What was true with traditional analytics with EDWs and OLAP cubes is still true today. You need both types of data stores and analytics to support the needs of operations and BI teams.
As Druid ingests streaming or batch data, it creates a denormalized table with all the data needed, and all the metrics as columns. It also creates all the relevant indexes and stores them directly with the data. It then partitions the data, metrics and indexes together horizontally in such a way to minimize the number of partitions that must be accessed to perform the query, and minimize network traffic. You simply aggregate results. This is how it achieves sub-second query performance against petabytes of data streaming in at millions of events per second.
The approaches Vertica and Druid take to partition, index and JOIN data highlight how their architectures differ.
Vertica User and Query Scalability
The third major issue with Vertica is how many users and queries it can handle concurrently. Quite a few architects within our customer base pointed at high concurrency as a major issue with Vertica. At scales of fewer than 20 users, Vertica worked well. But by the time they reached 100 users, running either predefined or ad hoc queries, Vertica would slow down, especially for complex queries.
One of the reasons was the use of projections or transient tables to optimize performance. In addition to projections, companies often create temporary tables to store data differently for query optimization. This table gets entered into the data dictionary. At high concurrency, data dictionary lookups create contention and a lot of queuing. As much as 50% of resources might be used for data dictionary and cause the machine to max out.
Druid User and Query Scalability
Druid is widely deployed for many employee- and customer-facing analytics, and has scaled to support thousands of concurrent queries or users in production. Any issues with resource contention or scalability were resolved a long time ago as its first deployments within adtech required support for large numbers of concurrent queries. Implementing Real-Time Analytics Alongside Vertica
If you are struggling with real-time operational analytics as a Vertica customer, some of the reasons above may be the cause.
Learn more from other companies about their Druid deployments, and how they use Vertica and Druid within the same company. Advertising leader Outbrain recently discussed a project where they replaced Vertica with Druid for real-time analytics, and how they operate both together.
Attend the First Druid Summit
Attend the first ever Druid Summit April 13-15, 2020 in San Francisco, where other companies will present their experiences implementing real-time analytics. If you’d like to give your own talk at Druid Summit, you can submit a proposal here.
Or just contact Imply for examples similar to your specific project.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...