Community Spotlight: Apache Pulsar and Apache Druid get close…
Sep 28, 2021
Peter Marshall
The open source community has a heritage of wide and deep collaboration to effect change. Despite a worldwide pandemic, it’s proven that people don’t have to come together physically to make a difference. The community team at Imply spoke with an Apache Pulsar community member, Giannis Polyzos, about how collaboration between open source communities generates great things, and more specifically, about how Pulsar and Druid can be used together to power real-time data insights.
My name is Peter Marshall and I am a Technology Evangelist working in the open source Druid community at Imply. In this blog I talk with Giannis Polyzos, a Solutions Engineer at Streamnative, who helps organisations deploy and run Apache Pulsar. Having once been a Solutions Engineer myself (even if only fleetingly!) I was very excited to speak with Giannis.
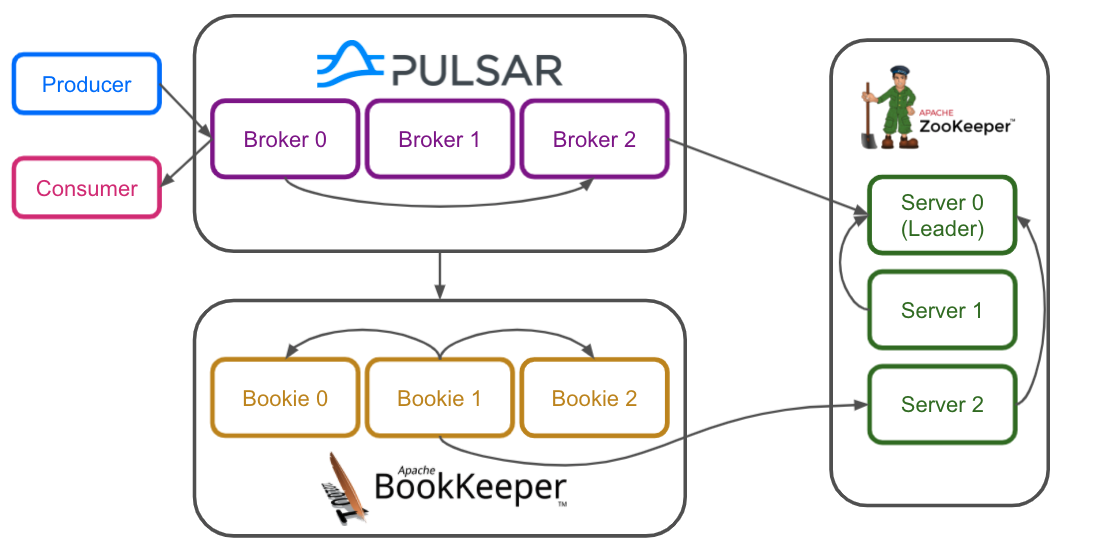
Let’s get started… “what is Apache Pulsar, Giannis?”
“Apache Pulsar is a cloud native, distributed messaging and streaming platform for building highly scalable event driven microservices.”
If you’re not familiar with Apache Druid and Apache Pulsar, you should note that there are a lot of synergies between these two technologies.
Apache Druid, a distributed OLAP database built for real-time, time-based analytics at speed, needs a real-time streaming platform to feed it so that it can power applications that deliver real-time insight and that reduce the latency between something happening and something being done about it by a decision maker. Together, Apache Pulsar and Apache Druid can power that real-time decision-making.
Pulsar has a lightweight, serverless compute framework for processing data in motion. Pulsar Functions allow engineers to spin up microservices and carry out enrichment, correlate streams, encrypt data, and so on. In a Druid pipeline, for example, it could handle sessionization, bifurcate data, or do multi-source enrichment. And as Giannis said:
“Companies that want to provide real-time dashboards, real-time insights, real-time queries, this is a way for them to achieve that. A unified delivery, processing, and analytics pipeline.”
Cloud-native architectures with building blocks that scale independently are of ultimate importance to architects and engineers. It’s a design principle for both Pulsar and Druid. In a Pulsar-Druid pipeline, you can imagine how collection, stream processing, delivery, analytics ingestion, database storage, and query processing can each be scaled in a focused way, maximising cost benefit and reliability. And to allow the pipeline to be applied in a range of use cases. The whole pipeline flexes naturally. According to Giannis:
“I saw that with Pulsar and Druid, analytics are lightning fast. This is what first caught my attention with Druid. So now I’m involved in the conversation about how to get closer integration, directly, natively.
“Instead of writing boilerplate code and so on to make Pulsar work with Druid, it would be wonderful if, with a click of a button in the Druid console, users could get data in and let Druid go on and ingest the data, to allow them to perform ad-hoc queries in minutes on real-time data direct from Pulsar.”
Giannis is not the only one, I’d love a closer connection, too. And not just me: it comes up in the Druid community channels as well.
“I was going through the Druid open source project on GitHub, and there were quite a few requests around Pulsar and Druid integration. There is an open PR that project members on both sides are actively reviewing. It looks like there is a way to go: it’s still a work in progress.
“PRs are a great way to continue working together, to build this better interface. Let’s not forget, we are an open source community here!”
Giannis and I are strong believers in the Apache Way. Apache Druid and Apache Pulsar are ours to make individual contributions to. And while we may work with different companies and have different job titles, it’s the Apache Way that brings us together.
Thank you, Giannis, for shaking virtual hands with us across Apache projects. It reminded us that open source tooling is made forever better through our shared community values. I know we both look forward to that magical Apache Pulsar input source!
If you’re reading this and you want to get involved, here are the all important issues and PRs:
The community would love to hear your story! Email community@imply.io to sign up for a 5-minute interview for your own Community Spotlight, and to discuss opportunities for blog posts and speaking slots, as well as to get the latest information about community activities across the world. And we’re also here to help you get your name in lights on Apache Druid’s Powered By page.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....