For years, fraud was primarily a game of strategy. Fraudsters sought to disguise their true intentions, and fraud prevention was an art of detection. Today, fraud is still a game of wits but it has also evolved into a game of speed and volume. The advancement of technology and explosion of e-commerce has had a compounding effect. No longer are fraudsters shackled by the need to physically steal a credit card and visit a store or meticulously forge a check they bring to a bank. In the digital realm they can easily disguise themselves, move faster and exist in several places at once.
Conversely, for fraud prevention teams, these advancements and the nature of online transactions means the window for detecting and stopping fraud has shrunk to sub-seconds. It isn’t enough to see through the disguise, you have to see through it in time.
For fraud prevention teams, the window for detecting and stopping fraud has shrunk to sub-seconds.
Ibotta, a free cash back rewards platform, is no exception to this phenomenon. As the success of the business and surface area of our system grow, the introduction of new and compelling features in the app also create space for bad actors to find holes in our armor. But as fraudsters have become more sophisticated, so have we. Our commitment to the integrity of our system has led to the creation of a best-in-class fraud prevention analytics program known internally as Cyberfraud Intelligence & Analytics (C.I.A. – because obviously).
To address the element of time, Ibotta’s fraud prevention strategy is multifaceted. The fact is, you can only combat automation with automation, and so we rely on a combination of 3rd party vendors and home-grown systems to make decisions about fraud in real-time. Those systems work around the clock to keep both our end users, whom we call our Savers, and our Brand and Retail partners safe. But fraud is constantly evolving. It is a moving target and inevitably fraudsters find a way to slip through. When that happens we turn to our on-call analysts and investigators and this is where our new partnership with Imply has significantly enhanced our capabilities.
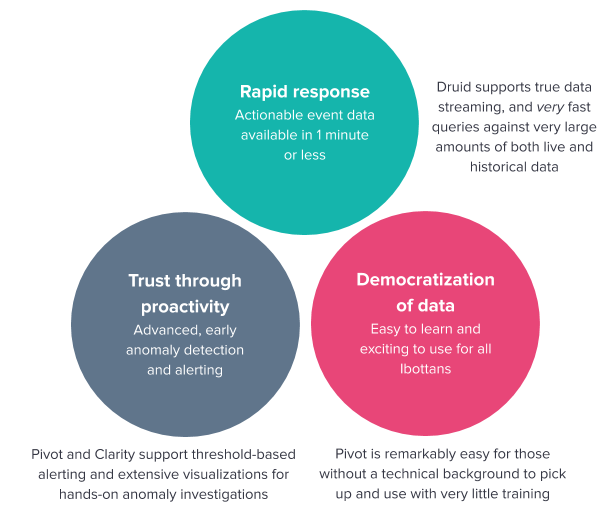
Using the unique and highly specialized tools that the Imply team has built into their product, we have already delivered remarkable results that are bolstering our resilience against fraud; moreover, we have successfully introduced and clearly proven the value of real-time analytics as a paradigm to the larger organization.
Challenges with our previous state
For those who have experienced a fraud on-call shift, you know initial detection is key, but equally important is the ability to quickly dissect and address the problem to minimize losses. This means access to real-time data is paramount.
Architecturally, Ibotta has walked a path familiar to many modern applications: we started with a monolith, and over time grew into a network of carefully orchestrated, message-driven microservices, facilitating greater resiliency, responsiveness, elasticity, and maintainability (these characteristics, with their powers combined, make up the Reactive Architecture paradigm). As a result, we have achieved a robust and growing ecosystem powered by event data.
That event-driven architecture gives our applications the ability to respond to changes in the environment in real-time, and it powers our fraud prevention services. Prior to our implementation of Imply, our analysts did not yet have the ability to unlock that data until hours later due to the mechanics of the pipeline into our data lake. And without a platform specialized for ingesting and exposing real-time data to analysts, our on-call team faced several high-impact roadblocks:
Dispersed Data Each of our 3rd party vendors includes their own real-time portal to review transactions and other flagged events. In isolation, the data provided by each vendor tells a powerful but incomplete story and analysts lose valuable time with each portal they had to visit.
Obsolete Dashboards Visualization is a powerful ally to an analyst looking to quickly understand the latest fraud trends. But fraud never stands still. The tools we had for visualizing our fraud landscape were ill-equipped to ingest real-time data and weren’t agile enough for the pace of change. Our classic BI dashboards would too quickly become obsolete as fraud tactics shifted.
Slow Queries In order to have a holistic view of our ecosystem and successfully monitor for fraud or other anomalies, we needed to be able to quickly query and visualize very large datasets. Our existing analytics stack had served us well for historical reporting and batch jobs but wasn’t designed for investigative analytics, where the issues are time-critical and response times are key to minimizing losses.
Technical Barriers Any options within our existing infrastructure for accessing real-time data required learning to use a custom query language for the platform. The technical barriers meant analysts would spend their time fighting with syntax and optimization, rather than doing what they do best: identifying patterns and driving value with our data. As we entered 2020, we knew our ecosystem and event architecture had reached a level of maturity that would allow us to resolve these pain points, not only for fraud but for use cases across the company.
As we entered 2020, we knew our ecosystem and event architecture had reached a level of maturity that would allow us to resolve these pain points, not only for fraud but for use cases across the company.
Evaluating and choosing Imply
Before selecting Imply, Ibotta evaluated several alternatives spanning categories such as log management, cloud monitoring, distributed search, and cloud BI. As with most things in life, there was no silver bullet – each one included the capability to access our event data in real-time, albeit through very different implementations with both assets and drawbacks.
After careful consideration, we found Imply to be clearly the most robust solution out of all of the platforms we were considering, that would allow us to meet three overarching business goals: supporting rapid incident response, building trust with our Savers and partners through proactive fraud prevention, and enabling more of our team to easily make use of our data.
Moreover, Imply met key specs around things like maintainability, workflows, cost, and security:
Managed cloud offering reduces maintenance time and risk
Full cluster transparency, monitoring, and alerting with Imply Clarity
Highly configurable and therefore extensible for a broad set of potential use cases
SQL support as well as drag-and-drop functionality
“Everything is clickable” Imply Pivot interface with robust, real-time visualizations
Optimized for numerical aggregations rather than text analysis or search functions
Cost-effective at the scale we expect for our roadmap
Role-based access at all levels, including individual aggregates and fields that may contain sensitive user or vendor data
Tools for masking and removing data in compliance with CCPA regulations
Filling in the gaps with a three-tier architecture
At Ibotta we separate our use cases into three storage layers: a data lake, data warehouse, and data river. Imply is now the foundation of our data river and serves as a key component in a broader analytical architecture at Ibotta, called Data Access in Real-Time (DART – anyone else a Stranger Things fan?). Various services within our system emit events, which we collect with an Event Observer implementation and pass through a series of Kinesis Streams and transformative AWS Lambda Functions. The results are then fanned out to Imply and other specialized consumers, which we use for custom anomaly detection and alerting workflows.
With the implementation of the data river, we have filled a major gap in our data ecosystem which up until now was preventing us from effectively conducting time-critical analytics. The data river runs in parallel with our existing pipelines to our data lake and warehousing solutions, but is completely decoupled, and designed to be extremely flexible. They are fed from the same source of truth but operate separately, with built-in resiliency to changes in one system or the other. This flexibility is particularly important for fraud data, as it allows us to limit sensitive data to the appropriate engineering teams as needed to comply with privacy rules.
The data river runs in parallel with our existing pipelines to our data lake and warehousing solutions, but is completely decoupled.
Combating fraud with Imply
With the DART architecture in place, the fraud team started to experience the benefits of Imply immediately. The previously mentioned roadblocks disintegrated. Now, for the first time, our analysts have immediate access to the same data our applications have been capitalizing on. They can see fraud as it’s happening.
In Imply, slow queries and syntax struggles have been replaced by Pivot’s Data Cubes offering slice and dice functionality with sub-second response times. Instead of obsolete reports and dispersed data, we now have a highly interactive real-time dashboard that incorporates both internal customer interaction events and data from each of our vendors. With this powerful tool, the team is armed with a holistic view of both fraud and our application ecosystem.
All of this is empowering our on-call team like never before, resulting in very tangible time and thus cost savings.
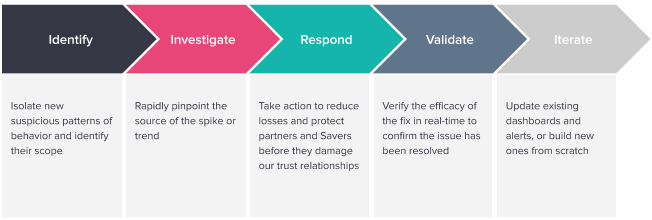
Pivot’s dashboards have made it much easier to isolate new fraud trends and identify their scope. By having all our data in one location and updated in real-time, suspicious patterns jump off the page with new clarity.
Once a trend is discovered, the agility of Pivot’s visualizations and Data Cubes substantially shortens investigations, and the time needed to pinpoint the source of the spike or trend. What may have taken hours previously (especially with the inherent latency of our data lake pipeline) now takes only minutes.
By swiftly spotting trends and better understanding their source and scope, the on-call team can take action quickly and with more confidence. Reducing the interval between fraud incident awareness and mitigation is crucial to our business in many ways, more of which are emerging as we expand our use of real-time data. In addition to the obvious savings from reducing the window in which a fraudster is active on our platform, it also helps us protect our relationships with our clients by instilling trust, with our payment networks by proactively reducing disputes, and with our Savers by protecting their accounts.
Once mitigating action is taken we can track the efficacy in real-time to confirm the issue has been resolved without negatively impacting our legitimate users.
Finally, as fraud patterns shift or new data becomes available, the fraud team can easily update existing dashboards or build new ones from scratch without needing to engage an engineer. Since development is quick and GUI-based, the time to value has been greatly accelerated, creating substantial cost savings in both engineering time and loss prevention after an attack.
Designing for rapid response
With each new technology we integrate into our system and workflows, we grow and mature as an engineering organization. They force us to rethink old assumptions and develop new patterns. Imply has been no different. From the completed implementation of our first project we have come away with many valuable pro-tips about ways to shift mindsets from traditional analytics to make the best use of a real-time system. But at the end of the day, it all really boils down to this: focus on the experience of your stakeholders.
It all really boils down to this: focus on the experience of your stakeholders.
The whole point of a data river is to make the information within it available and actionable as fast as possible. This means that it should take very little effort for end users – who may or may not have the technical know-how to execute complex SQL queries or build reports from scratch – to digest the data in front of them.
As system designers, then, it’s our responsibility to remove complexity upfront. We need to narrow our focus to their task at hand when modeling how to format and aggregate incoming data, so that it’s highly optimized in terms of speed, completeness, and relevance to what the end user is trying to accomplish. In other words: congratulations! You are now a UX designer (don’t panic if you live in the backend – it’s fun, we promise).
Now, this is not to say that reusability and consistency with the rest of the organization isn’t important. It is, for all kinds of reasons, not least of which is the cost of resources needed to store, process, and analyze high-volume datasets. But the nature of this particular flavor of analytics – especially in high-risk and time-sensitive domains like fraud – means that in this case, balancing ease-of-use with cost optimization and other organizational practices becomes mission-critical.
So, to design a data river which minimizes your stakeholders’ cognitive load, we suggest asking questions like these during the data modeling process:
What is the right amount and type of data needed for users to accomplish at least most of their goal in one place, rather than context-switching between multiple tools?
What information is needed to quickly identify patterns across windowed data, rather than long-term or lifetime trends like we’d look at in a data lake? Do any fields need to be renamed or reformatted to fit the operational context of the end user?
What fact data needs to be appended to real-time events in order to give context to the human users looking at the dashboard? Is it point-in-time or current-state? What could happen if it goes stale?
What is the investigative workflow for this use case? What common fields need to be present across data sources for analysts to be able to pivot and drill down effectively?
How do you structure sensitive user and vendor data in a way that gives your team the tools they need to do their work, while also protecting user privacy and contractual confidentiality agreements?
Are any of the events closely related, either structurally or contextually? If so, should they be unioned or joined into a single result set, versus overlaid or analyzed side-by-side?
Data lakes and warehouses exist to provide broad accessibility to the data ecosystem for a wide set of use cases, usually at the cost of speed and technical barriers to entry. But by taking these questions under consideration when we’re building a data river, we can fine-tune the tool to work extremely well for specific use cases where the goal is enabling rapid response.
Imply and Ibotta’s Core Values
While fraud prevention was the impetus for investing in Imply, the benefits extend far beyond it. At Ibotta, one of our Core Values is that “a good idea can come from anywhere.” We firmly believe that our most valuable assets are the creativity and vision of our team. Our partnership with Imply supports this value by giving more of our people more access to our data, empowering them to innovate, iterate, and further our mission to “Make every purchase rewarding.”
Due to the highly technical nature of real-time data systems, many companies rely on a small set of skilled and specialized technicians to work with data and provide answers to the business. But that small set of specialists does not scale to a large user base, especially when organizations are trying to push decision-making down to front-line business users who need to react quickly as events are unfolding.
Instead, Imply is helping us lower the technical barriers to entry and enable need-to-know employees without an engineering or data science background to add value to the data in a way that makes sense to them, and is unique to their area of expertise. Democratizing our data has made it available to a larger community of team members to leverage for improving the business.
This empowerment is allowing us to expand our real-time use cases beyond fraud detection into several business domains, including:
Ad ops processes
Campaign pacing and budget monitoring
Saver rewards and receipt processing
Product analytics and feature testing with clickstream analysis
With that said, we are already immensely pleased with our experience and results. We look forward to opening up the system to a broader user base and watching the inevitable transformation as teams across the company gain access to real-time data.
TL;DR:
Build yourself a data river and combat fraud with Imply.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....