Oct 17, 2024
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreIn Apache Druid, Compaction basically helps with managing the segments for a given datasource. Using compaction, we can either merge smaller segments or split large segments to optimize segment size.
One of the first options to consider would be to determine, if the segments could be generated optimally. If that isn’t possible, compaction would be required. Compaction for a given datasource can be done either manually using a compaction task or by scheduling automatic compaction through co-ordinator API / Datasources tab in Druid Web Console.
Automatic compaction is the recommended method to compact segments generated by Streaming datasources.
Compaction runs as a task and hence it would need middlemanager worker capacity (hereafter termed as slot) to complete a run. If the number of slots assigned is insufficient, automatic compaction might never catch up with the pace of segment generation. This might lead to query performance issues.
In a cluster with several datasources and supervisor jobs, it is necessary to do a good analysis of the number of slots required for automatic compaction.
This article discusses the slot requirement for automatic compaction of datasources. Also any references further in this article on compaction would be for automatic compaction.
The number of compaction slots available is determined by the following formula:
min(totalWorkerCapacity * compactionTaskSlotRatio, maxCompactionTaskSlots)
Compaction gets its slots based on compactionTaskSlotRatio and maxCompactionTaskSlots determined at the global level. Default value for compactionTaskSlotRatio is 10% and that of maxCompactionTaskSlots is 2^32-1.
The default value has to be adjusted on the following factors:
segmentGranularity of the datasourcetaskCount definedTo find the total number of worker capacity (slots) avaliable in the cluster, either visit the Services tab in Druid WebConsole and prune by Type= ‘middle_manager’ or use an API similar to the following and add up the capacity:
curl -X GET -H ‘Content-Type: application/json’-u admin:password -k https://druid-router-ip:8888/druid/indexer/v1/workers
Note: While running the above curl command, replace druid-router-ip with the cluster’s router node ip address or fully qualified domain name.
To get the current compaction configurations, run an API call similar to the following example:
curl -ivL -X GET -H ‘Content-Type: application/json’ -u admin:Password -k https://coordinator-ip:8081/druid/coordinator/v1/config/compaction/
{ "compactionConfigs": [
{
"dataSource": "parking-citations", "taskPriority": 25,
"inputSegmentSizeBytes": 419430400, "maxRowsPerSegment": null,
"skipOffsetFromLatest": "P1D", "tuningConfig": null, "taskContext": null
}
],
"compactionTaskSlotRatio": 0.1,
"maxCompactionTaskSlots": 2147483647
}Note: While running the above curl command, replace coordinator-ip with the cluster’s coordinator node ip address or fully qualified domain name.
In the above example compactionTaskSlotRatio is 0.1 or 10% and maxCompactionTaskSlots is 2147483647.
Based on the formula defined above, if the worker capacity in the cluster is 100, the available compaction slots would be 10.
To increase the available slots, compactionTaskSlotRatio and maxCompactionTaskSlots needs to be adjusted using an API like the following example:
curl -ivL -X POST -H ‘Content-Type: application/json’ -u admin:Password -khttps://coordinator-ip:8081/druid/coordinator/v1/config/compaction/taskslots?ratio=0.35&max=25
Above command would increase the compactionSlotRatio to 35% and change maxCompactionTaskSlots to 25.
Going by the compaction slots formula, the coordinator takes the minimum value between maxCompactionTaskSlots and (totalWorkerCapacity*compactionSlotRatio) as the actual limit for compaction task slots. For example let us consider a cluster with 100 slots and the following compaction configurations:
compactionTaskSlotRatio=0.35
maxCompactionTaskSlots=25
If the total worker capacity is 100, above would translate to 35 slots based on compactionTaskSlotRatio and 25 based on maxCompactionTaskSlots. In this scenario, compaction can only get a maximum of 25 slots at any time.
By default, the cluster would get a bare minimum of 1 slot if the total available slots are fewer than 10.
Make a table of datasource name, segmentGranularity, for example,
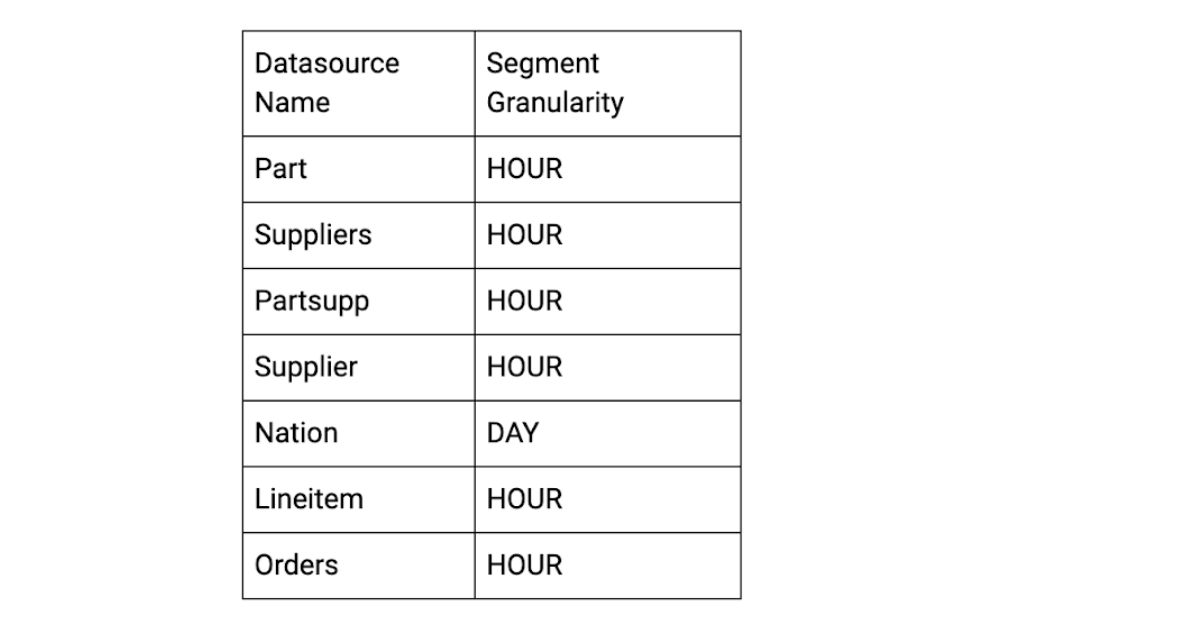
In the table above, 6 datasources have segmentGranularity as HOUR and one has segmentGranularity as DAY.
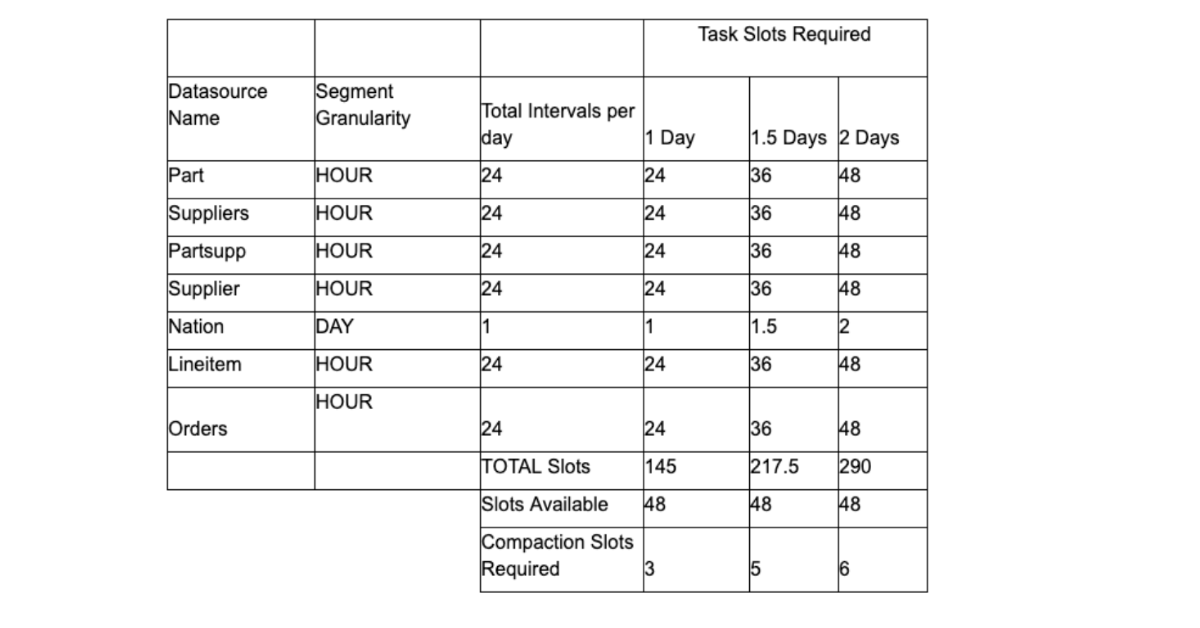
So we will have (6*24)+1=145 intervals to be compacted every day.
By default, the coordinator would wake up every 30 minutes to check/perform compaction meaning that we have 48 opportunities in a given day to start compaction. This can be controlled by coordinator runtime property, druid.coordinator.period.indexingPeriod.
Since we have determined the number of compaction tasks to be done per day is 145, and considering we have 48 attempts to compact, we would need a minimum of (145/48)~=3 slots to complete the compaction task each day. Since there could be delays in data generation and other issues, we need to give ourselves a buffer by considering the slots required for compacting 1.5 to 2 days of intervals.
This would evaluate to a minimum of 3×1.5~=4 or 3×2=6 slots.
Summarizing,
As an example, if the cluster has 5 datanodes (historical+middlemanager) with 5 worker capacity each, this would total up to 25 available slots in the middlemanagers.
By default , compactionTaskSlotRatio=0.1, which would translate to 25*10%~=2 slots available for compaction.
As can be seen above, we need at least 3 slots and a maximum of 6 slots. But, what is available is just 2. Hence to have compaction catch up, we can increase the compactionTaskSlotRatio to 0.2, which would translate to 25*20% ~=5 slots. This can be a comfortable value to start with.
From Imply 3.2, compaction tasks can be run in parallel for a given datasource, and hence, can be completed faster. This can be done by setting maxNumConcurrentSubTasks to a value higher than 1 in the tuningConfig
Running compaction tasks in parallel for a given datasource would need more slots. The tasks would need 1 slot for the compaction supervisor task and as many slots as maxNumConcurrentSubTasks.
For example, if compaction all of the datasources in the previous example are to run with maxNumConcurrentSubTasks=2, then, we would approximately need 3 times the slots when compared to executing the compaction serially (i.e. setting maxNumConcurrentSubTasks=1, which is the default)
Hence the compactionSlotRatio needs to be 0.6, i.e., 25*60%~=15 slots.
Carefully evaluate the minimum number of slots required by the tasks to be started by Streaming ingestion jobs (Kafka or Kinesis) and that of other batch ingestions.
Considering the above example, if 5 out of 7 datasources are using streaming ingestion, with taskDuration= PT1H and taskCount=1, then we would need a maximum of 10 tasks (5 reading and 5 publishing tasks) only for the Streaming ingestion.
If the remaining 2 datasources use native batch ingestion with maxNumConcurrentSubtasks=4, then it would need 5 slots (1 batch ingestion supervisor and 4 ingestion slots) per datasource, totalling to 10 slots.
Hence Streaming and other batch ingestion would need a total of 20 slots.
If we are running compaction tasks with maxNumConcurrentSubtasks=2, then we need 15 slots for compaction. Hence, overall we will need 35 slots including Streaming and batch ingestion jobs.
But we have only a total of 25 slots in the cluster. This might lead to tasks in WAITING status. To resolve this, the number of worker capacity in the system has to be increased.
If the compaction tasks are to be completed within druid.coordinator.period.indexingPeriod, then at the next interval coordinator would have enough slots to schedule the next set of compaction tasks. Otherwise, it would have less than the predetermined value. So the compaction task run time needs to be analyzed as well to arrive at the optimal number of slots for Compaction.
If the compaction jobs are faster, for example it completes in 15 minutes, then there is no harm in setting the slot ratio to be higher than what is calculated. The slots would be used only if there is a requirement.
By having an appropriate number of slots for automatic compaction, we ensure that the segments generated are appropriately optimized on time. This helps in improving query performance, reduced space usage and leads to cost saving.
Apache Druid Documentation: Compaction & Re-indexing
Apache Druid Documentation: API Reference
An Overview to Data Tiering in Imply and Apache Druid
Learn all about tiering for Imply and Apache Druid—when it makes sense, how it works, and its opportunities and limitations.
Learn MoreLast Call—and Know Before You Go—For Druid Summit 2024
Druid Summit 2024 is almost here! Learn what to expect—so you can block off your schedule and make the most of this event.
Learn MoreThe Top Five Articles from the Imply Developer Center (Fall 2024 edition)
Build, troubleshoot, and learn—with the top five articles, lessons, and tutorials from Imply’s Developer Center for Fall 2024.
Learn More