This feature-packed release includes Apache Druid 0.13.0, which has over 400 new features, performance improvements, and bug fixes from over 80 contributors It’s also the first release of Druid as an Apache project, under the umbrella of the Apache Incubator — an exciting milestone! (Check out the “Druid’s migration to Apache” section below for details about the process.)
There are too many new features in Imply 2.8 and Druid 0.13 to talk about in just one post, so I’ve chosen a selection of features to highlight in this blog post For the full list, check out the Imply and Druid community release notes.
Better Kafka ingestion through automatic compaction
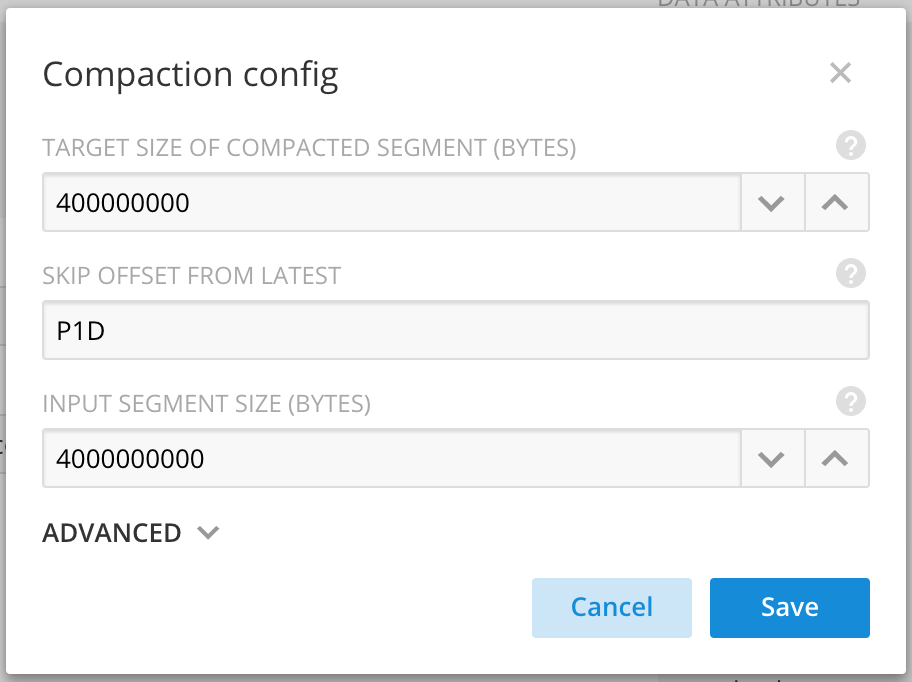
Merging small data segments into larger, optimally-sized ones is important for achieving optimal Druid performance on data ingested from streams, especially when late data is in the mix Up until now, this required submitting and running compaction or re-indexing tasks This required a manual process or an external scheduler to handle the periodic submission of tasks Imply 2.8, with Druid 0.13, includes a feature to automatically schedule compactions whenever they are needed It works by analyzing each time chunk for sub-optimally-sized segments, and kicking off tasks to merge them into optimally sized segments This makes operating an efficient cluster much more hands-off when using streaming data sources like Kafka and Kinesis.
This feature as it’s shipped in Imply 2.8 is helpful in lots of cases, but has two potential drawbacks to be aware of: first, an automatic compaction for a given time chunk runs in a single-threaded task, so for very large datasources, this will be unwieldy and you may want to continue doing compaction through other means Second, it cannot run for time chunks that are currently receiving data (when new data comes in, any compaction in progress will be canceled) This means that you’ll want to use the “skip offset from latest” option to avoid recent time chunks where late data might still be coming in We’re hard at work on both of these points, so if they affect you, keep an eye out here for news about future releases!
Druid SQL system tables
Last year, Druid 0.10.0 introduced Druid SQL, a way to query Druid datasources using the familiar SQL language instead of Druid’s native JSON API We have been thrilled by the adoption of Druid SQL in the community, and are now introducing a major new feature in 0.13: system tables!
Druid’s system tables are “virtual” tables that you can query with SQL and that provide insight into the inner workings of the system.
There are four tables:
sys.segments containing information about every data segment in the system
sys.servers containing information about all data servers
sys.server_segments containing information about which data servers hold which segments
sys.tasks containing information about all running and recently-completed ingestion tasks
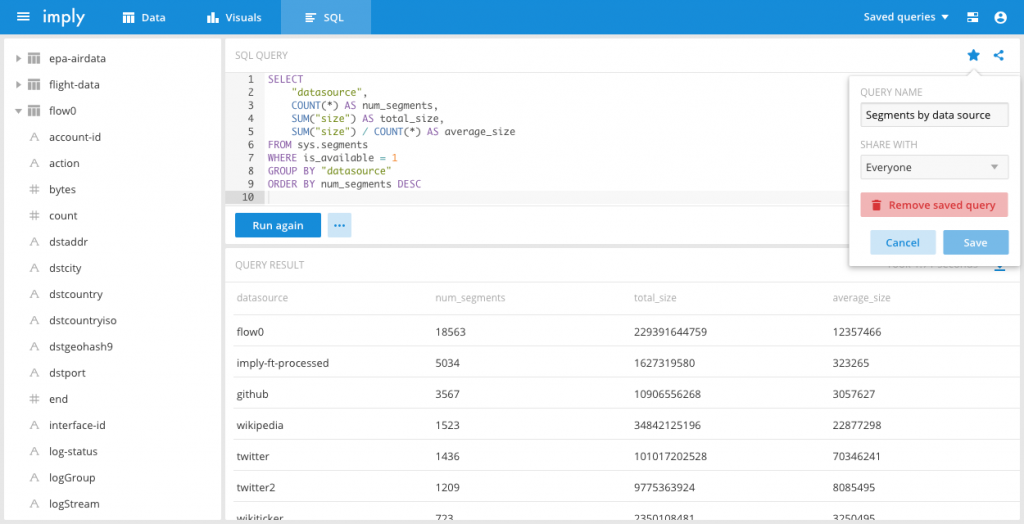
These have the same information currently available through Druid’s JSON cluster-status APIs, but the flexibility of SQL makes them much more powerful and easy to use Interested in checking how many segments you have published in each datasource, and what their average size is? Just run:
SELECT
"datasource",
COUNT(*) AS num_segments,
SUM("size") AS total_size,
SUM("size") / COUNT(*) AS average_size
FROM sys.segments
WHERE is_published = 1
GROUP BY "datasource"
One of Druid’s most important tuning parameters is maxRowsInMemory, which controls the threshold for spilling the contents of its in-memory ingestion row buffer to disk This can be difficult to properly configure, since the memory footprint of a row is based on multiple factors that can be difficult to predict Imply 2.8, with Druid 0.13, defaults to a fully-automatic mode where the ingestion row buffer will be limited by available JVM heap memory, not by number of rows To activate this behavior on previously-existing datasources, make sure to remove any maxRowsInMemory parameters you already have set If this parameter is not specified, Druid will switch to automatic limiting.
Parquet extension revamp
Imply 2.8 includes a revamped Parquet extension that is not part of the Druid 0.13 community release (It will be part of a later Druid release, though!) The new extension has been juiced-up to support flattening of nested data, correct handling of arrays, and correct handling of int96-based timestamp types.
Tableau integration through JDBC
Imply 2.8 includes support for the new JDBC connectivity option introduced in Tableau 2018.3 This offers improved compatibility and more robust integration versus the previously-recommended PostgreSQL emulation method Please contact us for more information about this new method of connecting Imply and Tableau! (Or contact your Imply representative if you’re already a customer.)
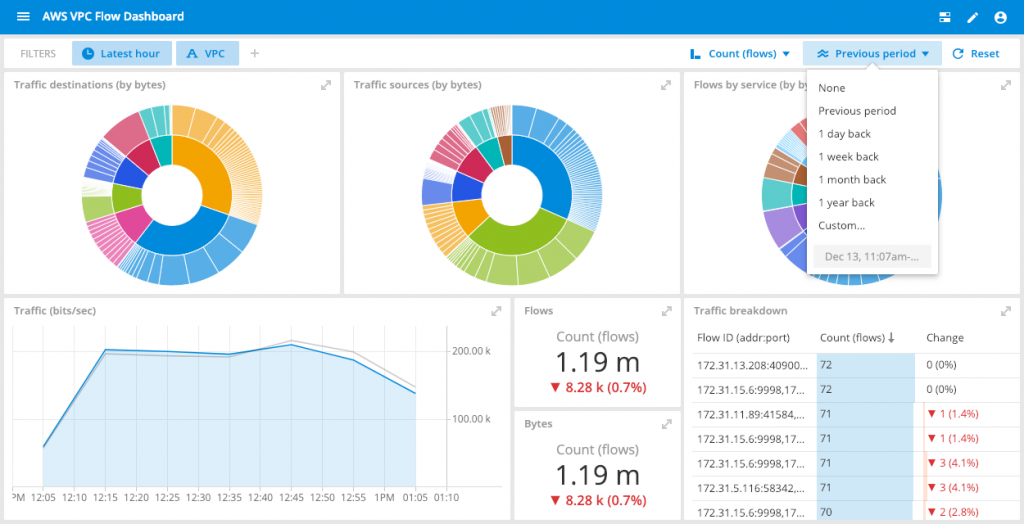
Dashboard control bar
In this release we are taking dashboards to the next level by introducing a global control bar that can be configured to manipulate the measures and compares available on each dashboard It is also possible to define certain dimensions as mandatory filters This feature lets you build more powerful dashboards with rich exploratory capabilities.
Saved SQL queries
The SQL IDE is getting a well deserved upgrade with shortened URLs and saved query support The shortened URLs make it easier than ever to share queries over chat or email It is also possible to save queries and reports, you can save queries privately or share them with your team.
Dark mode
Pivot is proud to join the manyawesomeproducts offering a dark mode Choosing a light background vs the dark side is a deeply personal choice, and as such, is stored as part of the user preferences which are editable via the new user profile dialog.
Druid’s migration to Apache
Before closing, I’d like to talk about Druid’s journey towards becoming an Apache project Druid began incubation at the Apache Foundation in early 2018 after years of prior development as an independent project and deployment at hundreds of sites The Druid community decided to take this step in recognition of Druid’s close integration with many other Apache projects (like Kafka and Hadoop), Druid’s pre-existing Apache-inspired governance structure, and the Apache Foundation’s status as a leading home for projects with strong communities and diverse contributor bases We’re excited about this move and expect it to be a very positive development for the Druid community!
Like all projects new to the Apache Foundation, this release was done under the umbrella of the Apache Incubator Don’t fret about the “incubating” tag on this release: it is a reflection on the stage we are at with the migration to Apache, not a reflection on quality This Druid release has gone out with the same high quality standards to which all previous community releases have been held As always, the Imply platform includes the most up-to-date version of Druid, along with any patches or hotfixes required by our customers.
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...