Imply 2.4 is now generally available and includes Druid 0.11, along with numerous new features.
End-to-end security
Imply 2.4 includes TLS support, built in basic authentication, Kerberos integration, and plugin support for new authentication integrations.
You can read more about all the new security features.
New home screen
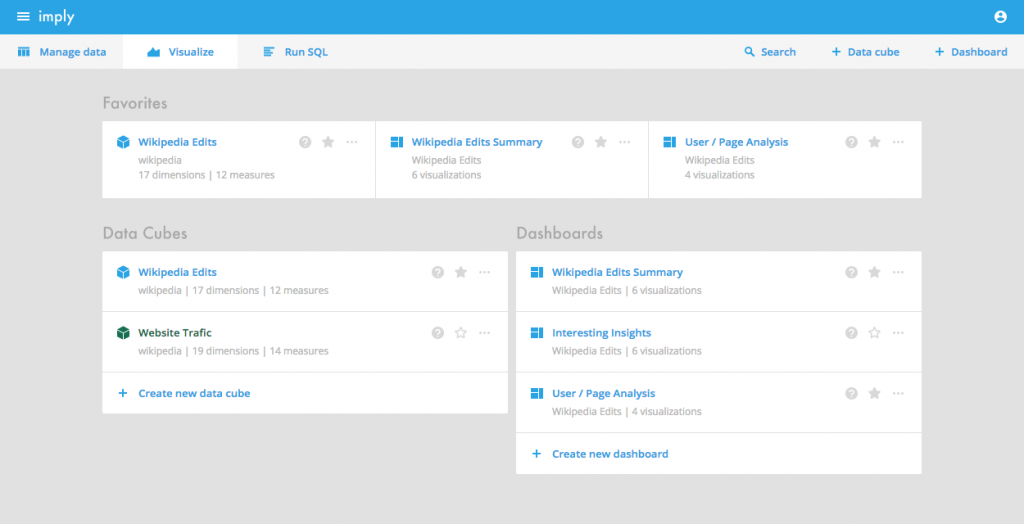
We’ve completely re-imagined the home screen in Imply.
When you first log into Imply, you’ll be presented with your data cubes and dashboards so you can begin interacting with them right away.Furthermore, we’ve added a top level navigation menu to make it easier to access all of Imply’s functionality.The navigation bar also includes direct access to our new datasets feature.
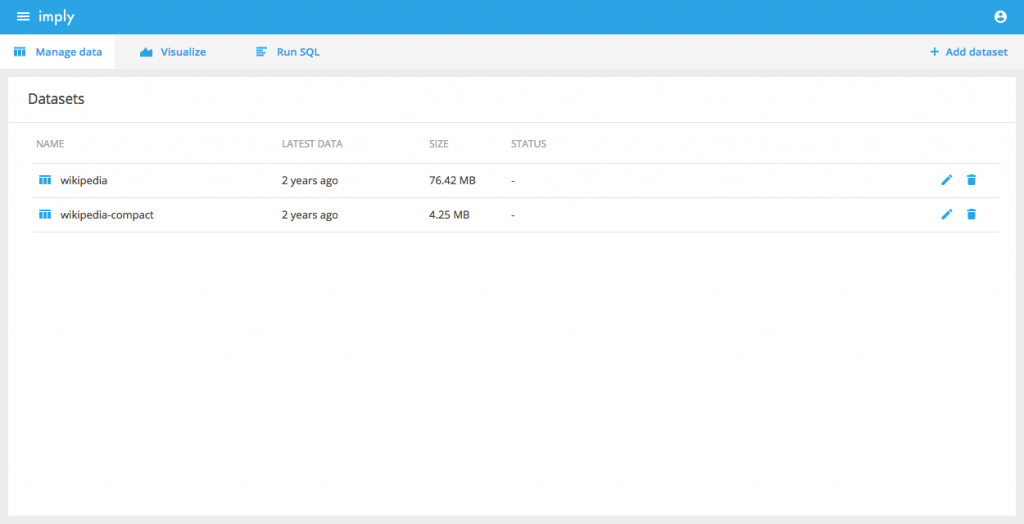
Datasets
We’ve been working hard on making raw data ingestion from different sources easier in Druid, and the new datasets view is an extension of this work in Imply.
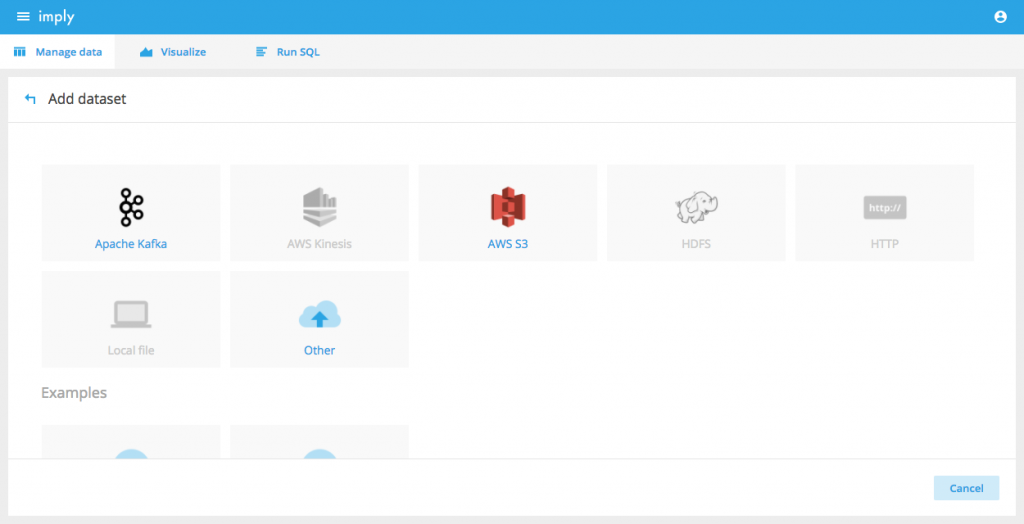
Our goal with datasets is for anyone to be able to click through an UI to load their data in Druid.In 2.4.0, the datasets view allows you to view and edit all of your ingestion tasks.Furthermore, it provides a data wizard for loading raw data from several different sources.
In future releases, we’ll be adding UI features to load data from all popular sources.
What’s new in the app?
Along with all the new security features available in Druid 0.11, Imply has also added support for customizable user roles and permissions.We’ve added authentication improvements for LDAP and the ability to consume roles from LDAP.
Dashboards have also gotten several improvements.There is now a custom text tile that supports markdowns, and additional measure formatting options including bytes per second and time duration.
Finally, our SQL viewer has added an explain interface so you can better understand how SQL maps to native Druid JSON-over-HTTP queries.
Do try this at home
Imply 2.4 is available for download today.Stay tuned for even more features for Druid and Imply.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...