This Imply release is based on Druid 0.16.0, a release so feature-rich and magnificent that it deserves a post of its own. At a glance, Druid 0.16.0 contains major performance, ingestion, and web console improvements:
Query vectorization, speeding up many queries by 1.3–3x
Shuffle for native parallel batch ingestion, boosting the power and flexibility of native (non-Hadoop-based) batch ingestion
An Indexer process, simplifying deployment configuration and architecture
Point-and-click stream ingestion and SQL workbench in Druid’s web console
Material refresh
In this release we have done a number of UI tweaks to make the interface feel smoother and more user friendly.
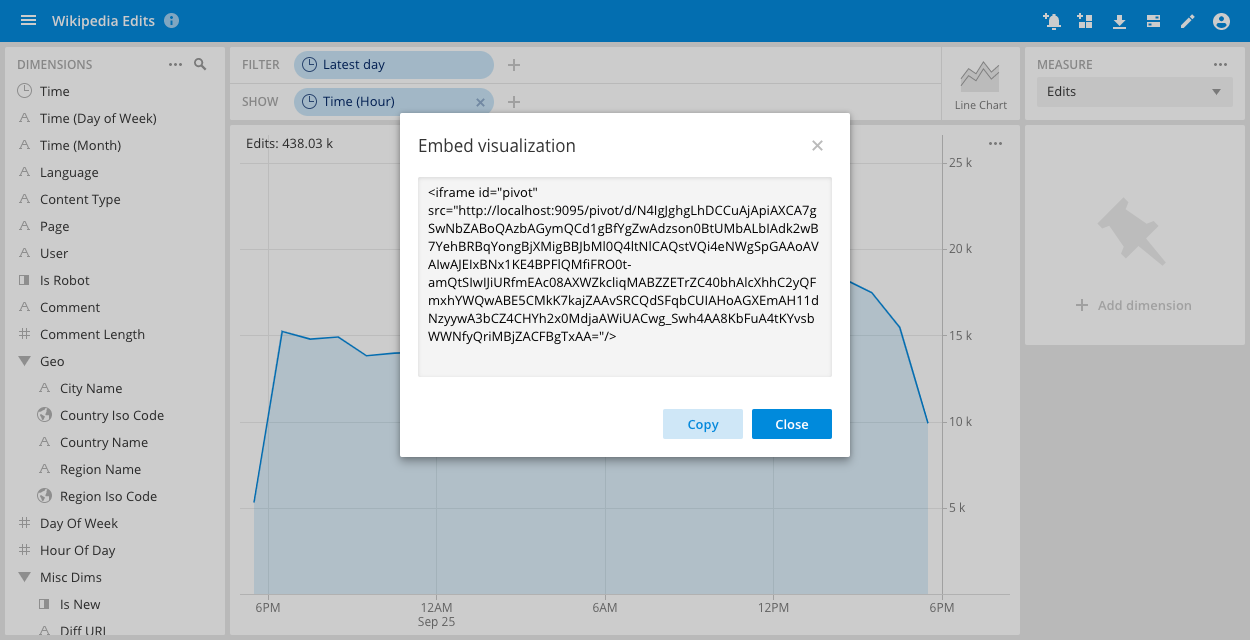
Embeddable visualizations
It is now possible to embed any visualization within your own application. With the embedding mode enabled simply grab the code for the visualization iframe and paste it wherever you want.
It is now possible to control an embedded Pivot iframe completely via the HTML5 postMessage API
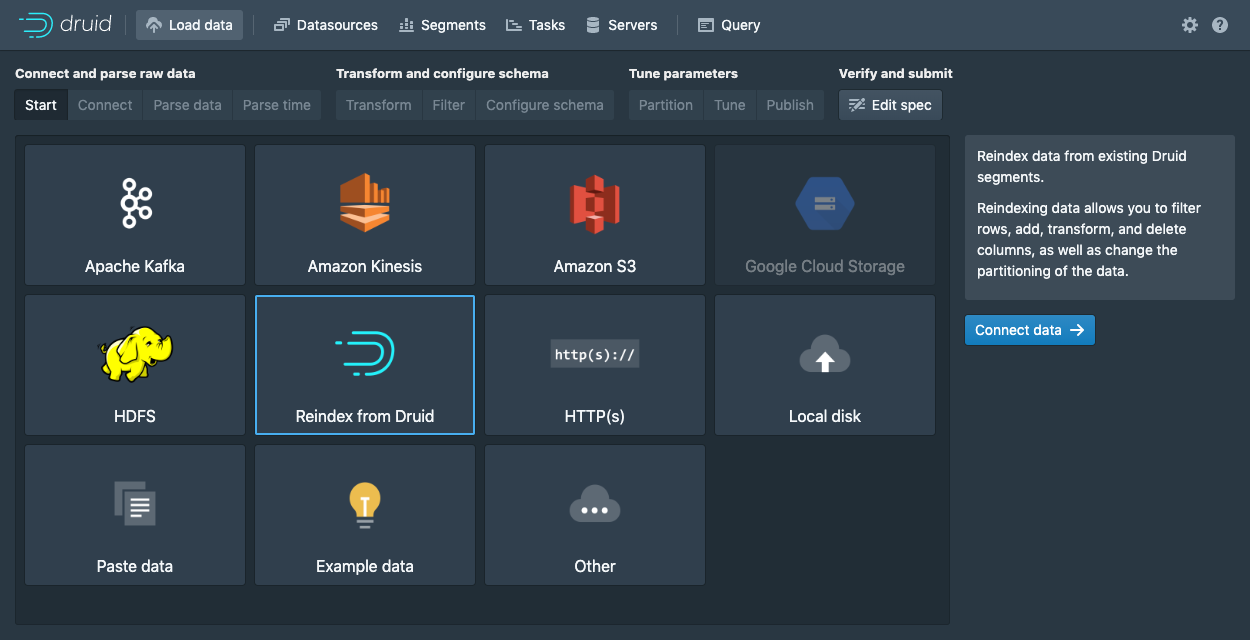
Point-and-click data reindexing
In this release we are adding the ability to reindex data in Druid using the point-and-click data loading wizard, allowing you to modify your data in Druid with ease.
Reindexing can be used to ‘drop’ sensitive rows from the data or to adjust the columns to manipulate the data footprint. This can all be done now without writing any JSON by hand.
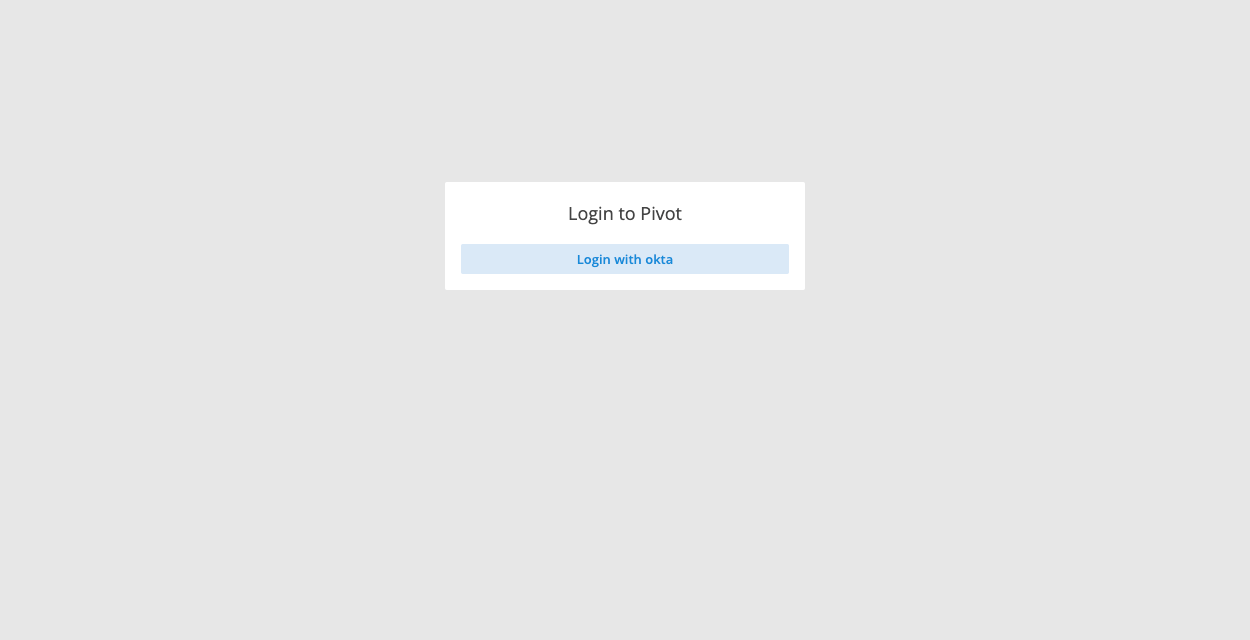
OIDC integration
This release greatly expands Pivot’s SSO support beyond just Okta to fully support any custom OIDC provider. It is now also possible to map OIDC groups to Imply roles.
Improved access control
This release also adds new features for managing how users can share and edit content in Pivot. User and role admins can now limit sharing by role, and it is now possible to grant limited, fine-grained edit privileges on data cubes.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...