Today, the Apache Druid community released Druid 0.15.0-incubating.
Druid is known as an extremely high-performance database and much of the early design work has been focused on providing speed at scale. Lately we have made a pivot towards those “ease of” factors that help users get productive with Druid quickly.
In this release there are 3 key enhancements to simplify Druid implementations:
The new Data Loader, which greatly simplifies building data ingestion pipelines by providing a point-and-click UI and automated previews.
We continue to advance our SQL functionality (literally, more functions) to simplify querying, plus SQL has graduated to fully supported status.
We created configurations and scripts to simplify execution of single-server proofs-of-concept.
Other Druid improvements were made in the areas of ORC, Google Cloud and the Scan query type. You can read about each below.
The 0.15.0 release has over 250 new features and performance/stability/documentation enhancements. As always, visit the Apache Druid download page for the software and release notes.
For Imply customers, these features and more will be available in the imminent release of Imply 3.0, so stay tuned for our notification.
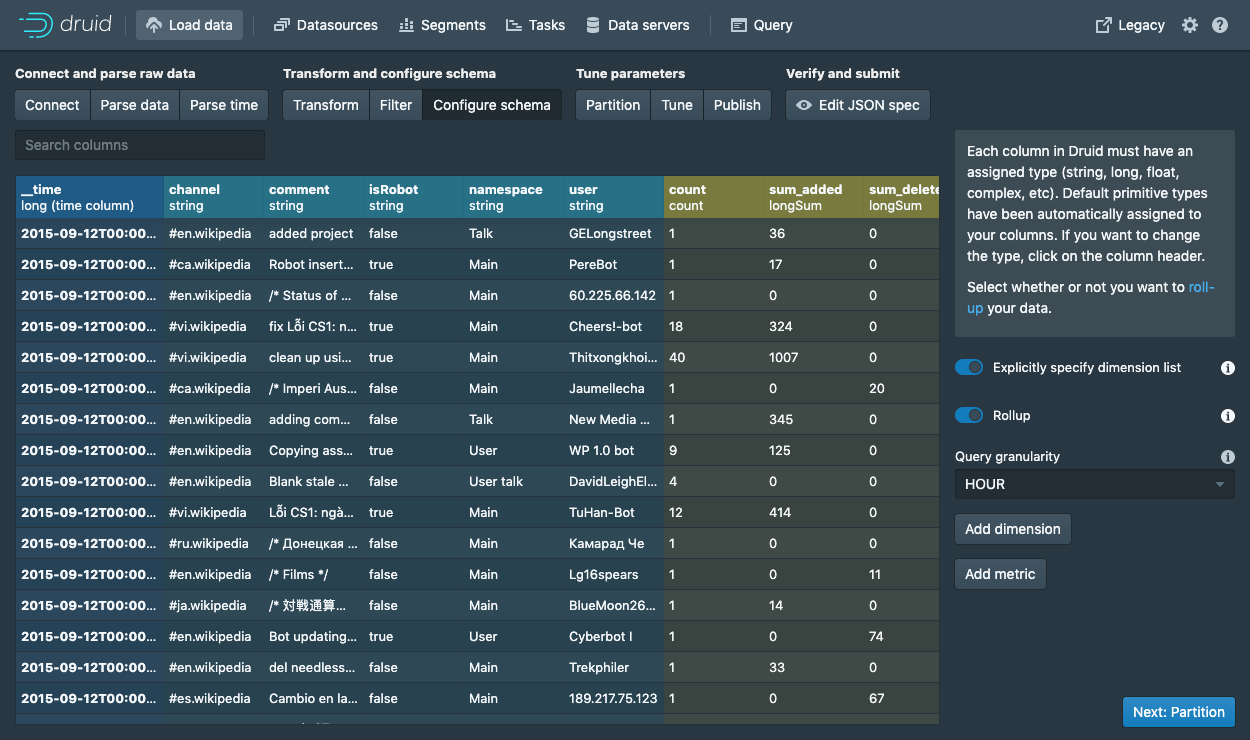
Data Loader for Apache Druid
A common request from the community has been to simplify the process of data ingestion, which to date has been a manual effort. To make ingestion much easier, we have added a point-and-click UI we call the Data Loader.
Data Loader takes you through the steps needed to build out your data pipeline and partition your data in Druid. As you progress through each step, Data Loader constructs the ingestion spec in the background. With each change, it sends an intermediate spec to Druid, which returns a preview of how the data will look once it is ingested. This allows you to debug your pipeline easily by finding and fixing errors interactively. All the relevant partitioning and tuning steps are annotated with inline documentation and defaults.
The Data Loader in Druid 0.15.0 currently can only load text-based batch data, but to quickly get to “full awesome” with this feature we have support for streaming data from Kafka, Kinesis and other sources already in development.
Watch this video walk-through to see where Data Loader is headed, and visit the docs to see how to access the web console.
Single-machine deployment example configurations and scripts
One common piece of feedback from Druid users is that initial setup and configuration, especially for a simple evaluation, can be time consuming due to the large number of options and possible deployment architectures. To simplify this, starting in Druid 0.15.0 we’ve provided tools and sample configurations — designed to work out of the box for a range of common server types and sizes — to make proof-of-concept evaluations and single-server deployments super easy. Read about them here.
SQL enhancements
Starting with this release, Druid SQL, which was originally released in Druid 0.10.0, has graduated out of experimental status. It is now a powerful standards-based alternative to Druid’s classic, native query language. It has been used to power integrations with Looker, Tableau, and countless custom internal apps. Druid SQL has been incredibly popular with the community and we are proud that it is now on an equal footing with Druid’s native query language.
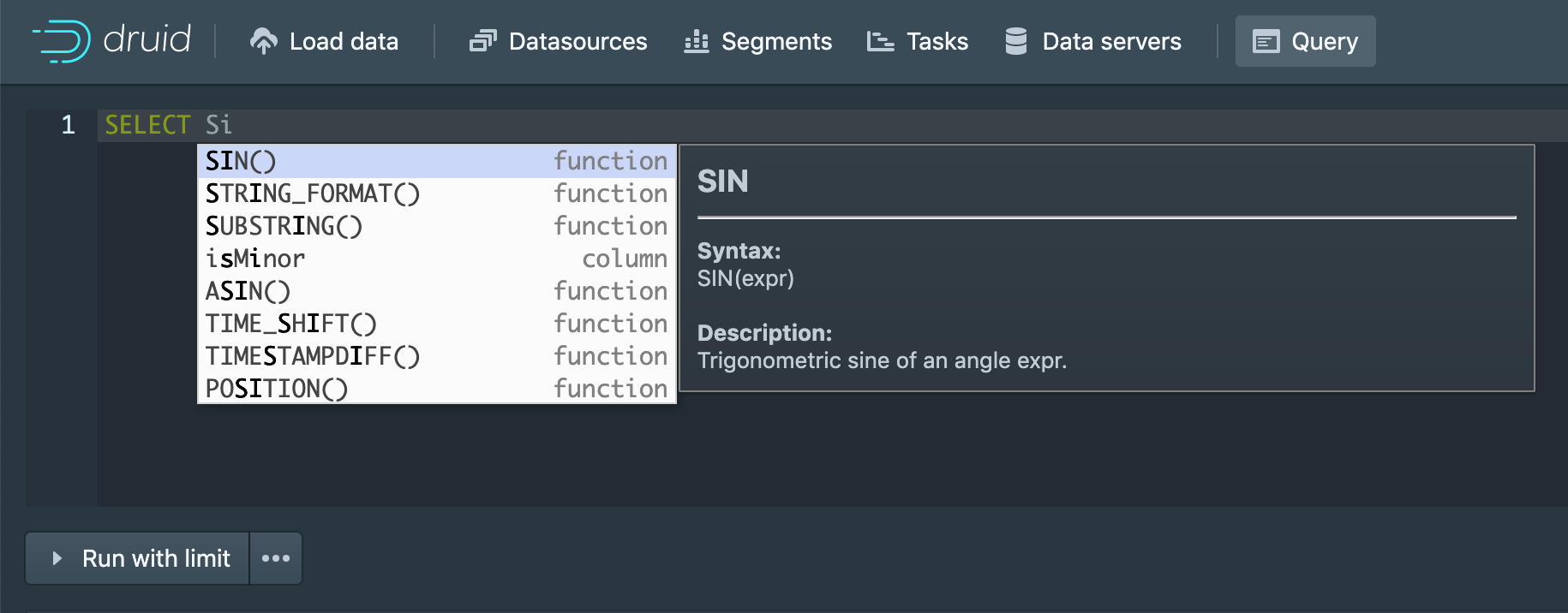
Nearly every release since Druid 0.10.0 has added new SQL features, and Druid 0.15.0 is no different. In this release, new functions have been added, including LPAD, RPAD, DEGREES, RADIANS, STRING_FORMAT, PARSE_LONG, ROUND, SIN, COS, TAN, and a variety of other trigonometric functions.
To help you compose your queries faster, SQL autocomplete has also been added to the Druid web console, as you can see here.
Future releases have even more exciting things in store for SQL, including full support for multi-valued dimensions, theta sketch intersection and differences, and support for even more aspects of the SQL standard.
Other items
In addition to the major items mentioned above, a small selection of other notable items in this release include:
The ORC file format is now officially supported as a core extension. It also now supports flattening nested data through the new orc parseSpec and flattenSpec. Documentation can be found here.
Google Cloud Storage is now officially supported as a core extension, both for deep storage and native batch ingestion. Documentation is available here.
Thanks to the hard work of Justin Borromeo, an intern at Imply, the Scan query type now supports time ordering and makes Scan the default method used by SQL. This upgrade avoids the memory use and performance issues associated with using the legacy Select query. Anyone using Select is encouraged to migrate to Scan. Druid SQL users will see this migration happen automatically due to a planner update, whereas native query language users can switch to the Scan query type. Read more here.
For a full list of all the new functionality in Druid 0.15.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...