Today the Apache Druid community released Druid 0.14.0 (incubating), our second release under the Apache umbrella and the first major release of 2019.I thought I’d take this opportunity to talk about what’s new in this release and what’s coming in the future.I also encourage you to try out this new version of Druid by downloading Imply 2.9, which includes Druid 0.14.0 as well as Imply Pivot, or by heading over to the Apache Druid download page for the community release.
New in Druid 0.14.0
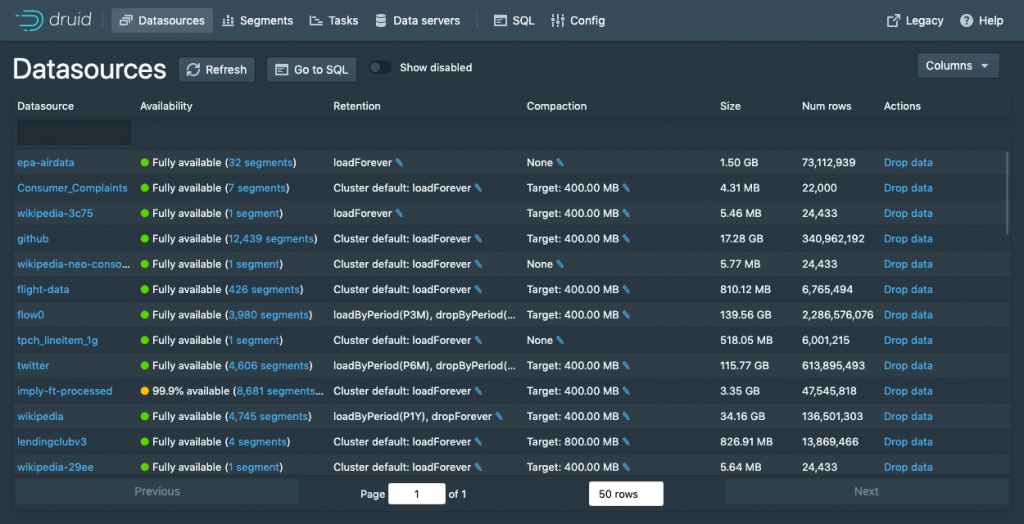
One of the most exciting features in this release is a very visible one. We’ve contributed a brand-new web console for Druid, built on top of Druid SQL system tables, that gives you one-stop-shop visibility into the datasources, segments, data servers, and ingestion activities on your cluster.It also lets you submit tasks, kick off supervised ingestion (from Kafka or Kinesis), and issue Druid SQL queries.In this release it lives on the Druid Router process, and you can turn it on by starting up a Router with the management proxy enabled (druid.router.managementProxy.enabled=true). It’s enabled by default in the quickstart config, and I encourage you to try it out and provide your feedback on Druid’s GitHub. We’ll be continuing to improve the console in future releases, and intend to make it available on the Druid Coordinator as well.
Other than the new console, this release also brings a number of ingestion improvements.These are particularly important, since when we ask Druid users what features they’re looking for, the top requests are to support ingestion of more data sources and data formats, and to improve ingestion robustness. Druid 0.14.0 has three important developments here.
First, a Kinesis indexing extension, contributed by Imply, and based on an extension that used to be part of our proprietary offering. (More on this later.)
Second, a revamped Parquet extension. It’s been moved from the community-contrib list to a core extension, meaning there’s now a commitment from the Druid community to adopt and maintain it.And it’s been updated to support flattening nested data structures and to support more data types (especially INT96, a common request, since it’s often used for timestamps).
Lastly, starting with this release, the Kafka indexing service that was originally released in Druid 0.9.1.1 has graduated out of experimental status.This reflects the maturity of what has become an incredibly popular feature that allows direct, scalable, exactly-once ingestion of data from Kafka into Druid.We wrote about how it works back when it was originally released in a post titled Farewell Lambda Architectures: Exactly-Once Streaming Ingestion in Druid.Since then, the feature has attracted a lot of interest from the community, including important advancements like the addition of incremental publishing in Druid 0.12.0.It powers our Imply Clarity product (cloud-based performance analytics for Druid) as well as a slew of other systems, internal and externally-facing, at a variety of sites.We’ll be attending Kafka Summit London next month to talk more about it, and hope to see you there!
For a full list of what’s new in Druid 0.14.0, take a look at the release notes.
A reaffirmation of our open philosophy
With our contributions to Druid 0.14.0, which will form the basis of Imply 2.9, we at Imply are reaffirming our commitment to driving open-source Druid forward.We have chosen to open-source two key components that were formerly only available as part of the Imply distribution: the native Amazon Kinesis ingestion extension, and the unified web console that gives you a single view into your Druid cluster. In future versions of the Imply distribution, we will be moving our current, proprietary web-based data management app (named “Datasets”) into better alignment with this built-in Druid web console that we’ve contributed, bringing the fully open Druid experience and the Imply experience closer together. And we’ll be investing even more effort into improving this web console in future releases.
We do remain an “open core” company and intend to continue investing in proprietary products. But we take our commitment to an open Druid seriously, and do not plan to intentionally limit what the 100% open-source project is capable of. Instead, we are investing our proprietary-development energies mainly into two adjacent areas that help you maximize the value of your Druid investment: applications and cluster management.
On the application side, we have built Pivot, a world-class real-time analytics application designed from the ground up to work well with Druid.If you’re familiar with business intelligence applications like Tableau and Apache Superset, and dashboarding applications like Grafana, you’ll recognize Pivot as a unique cross between the two. Like Druid, it takes special care to handle high-volume and high-cardinality data without falling over.And like Druid, it embodies an engineering culture of speed and efficiency.The technology is proven at scale: our customers have deployed Pivot to large user bases on top of Druid clusters with 1000+ servers.I encourage you to check out Pivot at https://imply.io/get-started.
On the cluster management side, we have built Imply Cloud, a managed offering based in the Amazon cloud.Our management software launches instances in your account, so you get the best of both worlds: point-and-click cluster management while also retaining full control over your resources.And stay tuned for a future announcement of a self-hosted Imply Manager, giving you the same capabilities in any cloud or in your own datacenter.If you’re a customer, I encourage you to reach out to your Imply representative about our preview program.
I am Druid, and so can you
As a community project, Apache Druid’s development happens in the open.You can follow development or join the community of users and developers using any of the following resources:
Users congregate online at the druid-user mailing list and offline at meetups. The biggest one is the San Francisco Bay Area meetup, but we are also starting to schedule regular meetups in New York and other cities – stay tuned!
Development happens on the dev@druid.apache.org mailing list, and on GitHub at https://github.com/apache/druid. We accept issues and pull requests from anyone – come on over, star the repo, and check it out!
Druid news, like release announcements and upcoming events, are posted on the @druidio Twitter feed and on the Druid website.
Thanks for reading, and I hope you enjoy Apache Druid 0.14.0.
Other blogs you might find interesting
No records found...
Jul 23, 2024
Streamlining Time Series Analysis with Imply Polaris
We are excited to share the latest enhancements in Imply Polaris, introducing time series analysis to revolutionize your analytics capabilities across vast amounts of data in real time.
Transform your data management with upserts in Imply Polaris! Ensure data consistency and supercharge efficiency by seamlessly combining insert and update operations into one powerful action. Discover how Polaris’s...