Imply is a high performance analytics system for many different types of event-driven data.One of the common use cases of the system is to store, analyze, and visualize different types of networking data (Netlink/NFLOG, NetFlow v1/v5/v7/v8/v9, sFlow v2/v4/v5, IPFIX, etc.).
In this tutorial, we will step through how to set up Imply, Kafka, and pmacct to build an end-to-end streaming analytics stack that can handle many different forms of networking data.The setup described will use a single AWS instance for simplicity, but can be used as reference architecture for a fully distributed production deployment.
Prerequisites
- A bare metal server or cloud instance (such as an AWS m5d.xlarge instance) with 16GB RAM, 100GB of disk, and an ethernet interface.
- The server should be running Linux.
- You should have sudo or root access on the server.
- A router, switch, firewall, or host that can send networking data.
Install pmacct
- Download pmacct from the following URL: http://www.pmacct.net/pmacct-1.7.2.tar.gz
- Install libpcap. This should be available in your Linux repository.
$ sudo apt-get install libpcap0.8
- Install librdkafka and librdkafka-dev.
$ sudo apt-get install librdkafka-dev $ sudo apt-get install librdkafka1
- Set environment variables for libraries.
$ export KAFKA_LIBS="-L/usr/lib/x86_64-linux-gnu -lrdkafka" $ export KAFKA_CFLAGS="-I/usr/include/librdkafka"
- Download and extract the following jansson file: http://www.digip.org/jansson/releases/jansson-2.12.tar.gz
- Set environment variable for libraries:
$ export JANSSON_CFLAGS="-I/usr/local/include/" $ export JANSSON_LIBS="-L/usr/local/lib -ljansson"
- While in the jansson directory created during extract, compile jansson by running:
$ ./configure $ make $ make install
Compile pmacct
- Extract the pmacct-1.7.2.tar.gz tarball to a desired directory.
-
cd to pmacct directory that was created after extraction
- Run the following commands:
$ ./configure –enable-kafka –enable-jansson $ sudo make $ sudo make install
- Create your nfacctd (a binary installed with pmacct) configuration file with the following information. Modify the highlighted areas to add your relevant information. Verify nfacctd is working before removing the # in front of daemonize so logs are displayed at the terminal. Once you know everything is working uncomment this and restart nfacctd.
! kafka_topic: netflow kafka_broker_host: *<IP where your kafka process is running>* kafka_broker_port: *<consumer port – typically 9092>* kafka_refresh_time: 1 #daemonize: true plugins: kafka pcap_interface: *<local interface to listen for netflow packets on>* nfacctd_ip: *<local IP to listen for netflow packets on>* nfacctd_port: *<port netflow is being sent to>* aggregate: src_host, dst_host,in_iface, out_iface, timestamp_start, timestamp_end, src_port, dst_port, proto, tos, tcpflags
Install Imply
Install Kafka
- Download the most recent Kafka distribution from the following URL:
http://www-us.apache.org/dist/kafka/0.11.0.3/kafka_2.11-0.11.0.3.tgz
Note: The Imply distribution already includes Apache Zookeeper, which Kafka will use when you start it.
- Start Kafka with the following command from within the Kafka directory:
$ sudo ./bin/kafka-server-start.sh config/server.properties &
- Create a Kafka topic using the following command where is replaced with the name you want – such as netflow. From the Kafka installation directory, run:
$ sudo ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic *<topic name>*
Start nfacctd
- Nfacctd (included with pmacct) can be started with the configuration above. This will start a process that listens for incoming network flows.
$ sudo nfacctd -f ./nfacct.conf
- Start sending network flows to the system you have just set up. Make sure to change your security rules to allow the source IP of the network flow sender and the destination port that you configured on the router.If everything is working properly you should see nfacctd display number of received packets.Note that this does not happen all the time — counters are incremented only when a flow export takes place from the router and this process is based on flow export timers. When you see packets registered, you can check your Kafka consumer by running the following from the Kafka installation directory.:
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic *<topic name>* --from-beginning
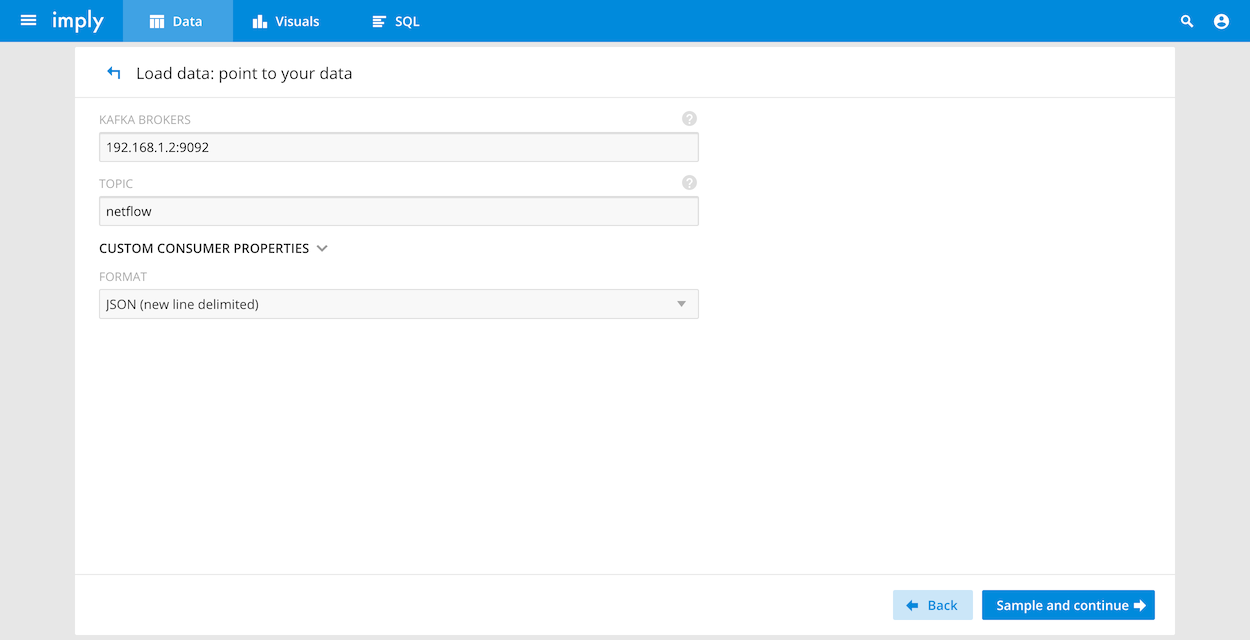
Connect Kafka and Imply