Tutorial: Add BGP Analytics to your Imply netflow analysis
Jun 08, 2020
Eric Graham
Imply is a real-time data platform for self-service analytics. It is very well suited for high performance analytics against event-driven data. One of the common use cases is to store, analyze, and visualize different types of networking data (NetFlow v5/v9, sFlow, IPFIX, etc.). I covered this in a previous blog post “Tutorial: An End-to-end Streaming Analytics Stack for Network Telemetry Data”.
For some network operators additional visibility is important. You might want to understand how you reach your customers through the Internet. Maybe you want to understand your top next-hop ASNs to determine your transit cost, or maybe performance has dropped and a specific ASN is the culprit, or you use BGP for internal routing with limited visibility into how traffic moves through your network. There are many use cases analyzing netflow with BGP.
A bare metal server or cloud instance (such as an AWS m5d.xlarge) with 16GB RAM, 100GB of disk, and an ethernet interface.
A server running Linux.
Sudo or root access on the server.
A router, switch, firewall, or host that can send networking data.
A router that can peer BGP and has a full or partial routing table (not default route). I used exaBGP for my setup with super-smash-brogp to generate BGP updates with the right attributes. It worked great for testing. (Email me if you would like additional setup details for this eric.graham@imply.io.)
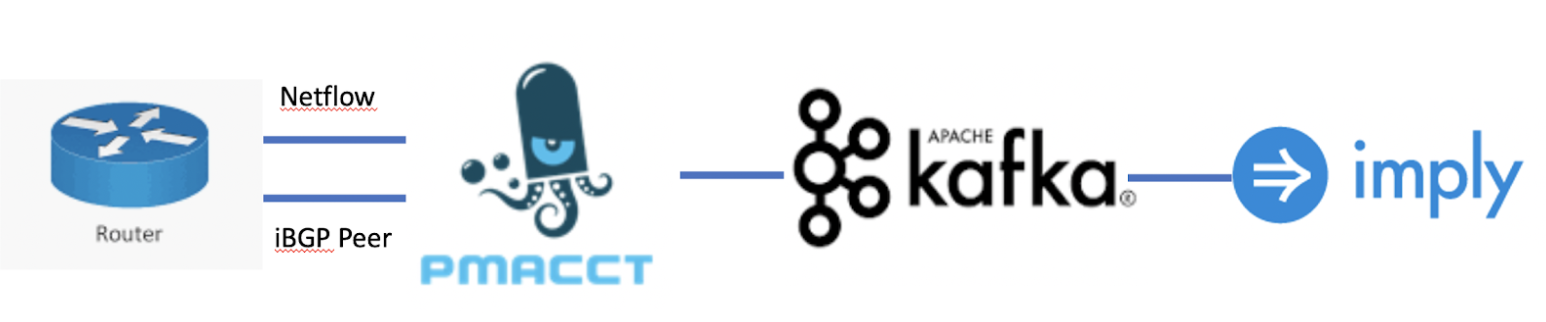
The architecture we will be using looks like the following:
Install supporting packages for pmacct
Install libpcap. This should be available in your Linux repository.
$ ./configure –enable-kafka –enable-jansson --enable-bgp-bins
$ sudo make
$ sudo make install
Create a bgp.map file for pmacct/nfacctd that includes the following. This maps the BGP router-id from your router to the netflow source IP. Highlighted selections need to be updated for your environment.
bgp_ip=2.2.2.2 ip=192.168.2.5
Create your nfacctd (a binary installed with pmacct) configuration file with the following information. Modify the highlighted areas to add your relevant information. Verify nfacctd is working before removing the # in front of daemonize so logs are displayed at the terminal. Once you know everything is working uncomment this and restart nfacctd.
!
#Kafka topic for netflow with BGP
kafka_topic: pmacct
kafka_broker_host: 10.1.9.106
kafka_broker_port: 9092
kafka_refresh_time: 1
kafka_refresh_time: 10
plugins: kafka
#daemonize: true
#interface you are listening on for netflow
pcap_interface: ens5
#IP you are listening to for netflow
nfacctd_ip: 10.1.9.106
#Netflow port you are sending to from your router
nfacctd_port: 20013
#debug[default]: true
nfacctd_time_new: true
#Kafka topic to send your BGP routing table to
bgp_table_dump_kafka_topic: pmacct.bgp
bgp_table_dump_refresh_time: 60
bgp_daemon: true
#IP on your host you are listening on
bgp_daemon_ip: 10.1.9.106
bgp_daemon_max_peers: 100
nfacctd_net: bgp
nfacctd_as: bgp
#Local BGP ASN. This should be the same as your router ASN for iBGP
bgp_daemon_as: 65001
#Point to the location you created above for your bgp.map file
bgp_agent_map: /opt/pmacct-1.7.2/bgp.map
aggregate: src_host, dst_host,in_iface, out_iface, timestamp_start, timestamp_end, src_port, dst_port, proto, tos, tcpflags, tag, src_as, dst_as, peer_src_as, peer_dst_as, peer_src_ip, peer_dst_ip, local_pref, as_path
Router configuration
Configure your router to send flow data to nfacctd daemon based on the config above.
In your router neighbor configuration the router should be defined as a Route reflector and nfacctd a Route Reflector Client.
Modify conf-quickstart/druid/_common/common.runtime.properties with the right directories for segments and logs. If you have plenty of local disk you can keep the default configuration. A good reference is the Imply quickstart documentation: https://docs.imply.io/on-prem/quickstart
Start Imply from the Imply directory with the quickstart configuration by typing the following:
Create two Kafka topics (one for netflow with BGP and one for your BGP routing table) using the following command where < topic name > is replaced with the name you want – such as netflow and pmacct.bgp From the Kafka installation directory, run:
Nfacctd (included with pmacct) can be started with the configuration above. This will start a process that listens for incoming network flows. Once you have added the nfacctd daemon as a neighbor in your router (next bullet down) you should also see BGP state move to OPEN state with your router.
$ sudo nfacctd -f ./nfacct.conf
On your router configure a neighbor to match what you added in your nfacct.conf file. You should have the same ASN for your router and the nfacct.conf to create an iBGP peer.
Start sending network flows to the system you have just set up. Make sure to change your security rules to allow the source IP of the network flow sender and the destination port that you configured on the router. If everything is working properly you should see nfacctd display the number of received packets. Note that this does not happen all the time — counters are incremented only when a flow export takes place from the router and this process is based on flow export timers. When you see packets registered, and the BGP peer is up, you can check your Kafka consumer by running the following from the Kafka installation directory.:
Open the Imply UI by opening a browser and either going to localhost:9095 (if browser is being run from your localhost) or . Remember to modify your security rules to allow destination port 9095 from your source IP.
Select the Data/+Load Data (left tab).
In the Druid data loader select “Load data”, “Create a new spec”, Apache Kafka”. “Connect data on right”
Fill in the details for the Kafka process including IP:consumer port (typically 9092) and the topic name that you created previously (e.g. 192.168.1.2:9092). You will be creating two data sources. One for netflow with BGP and the other specifically for the BGP routing table. Therefore this process will need to be executed twice.
Select “Sample and continue”
Select “Next” for the remaining screens to start loading your network flows into Imply.
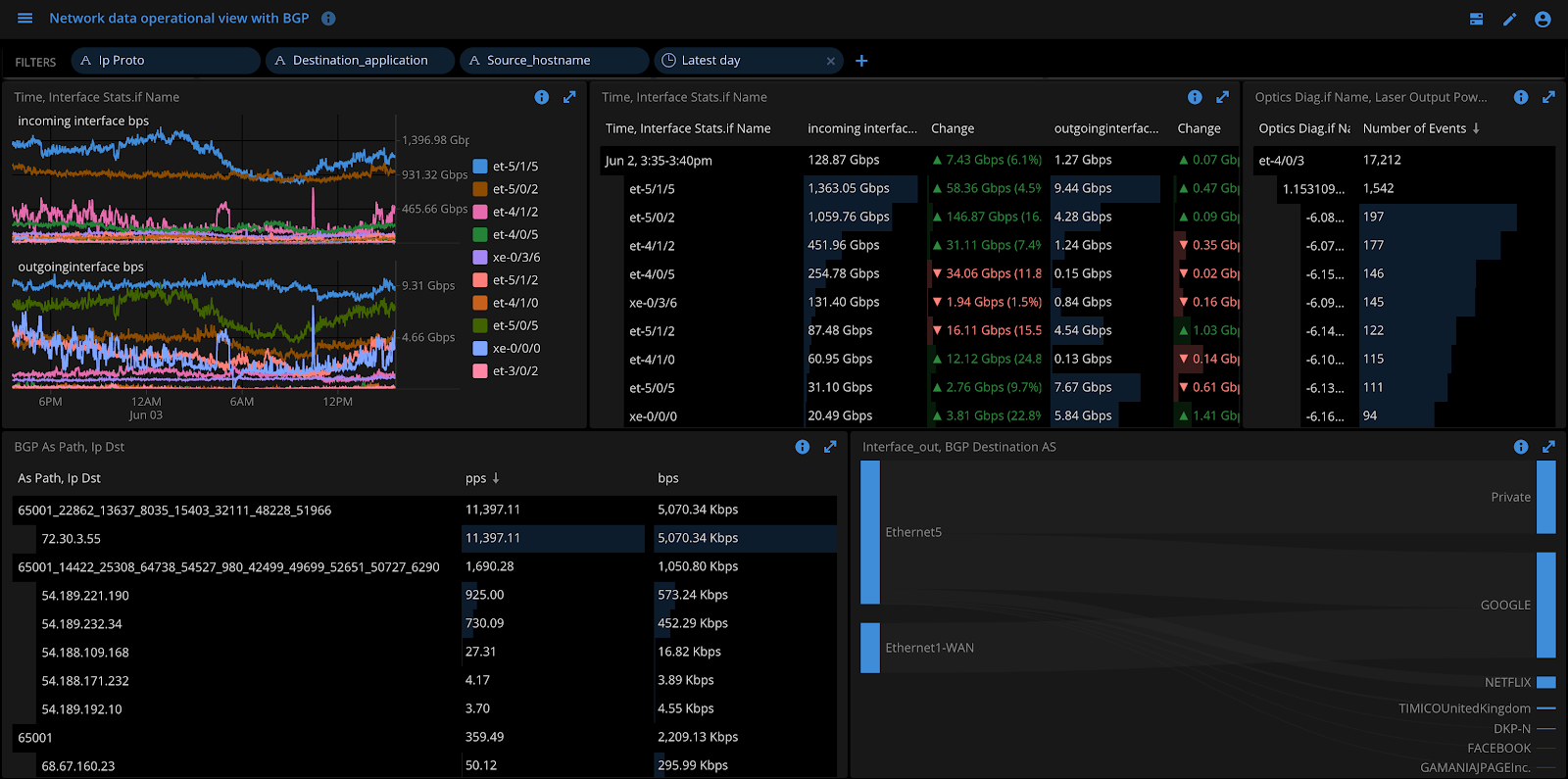
Start visualizing BGP with netflow. In the following dashboard I can view top BGP AS_Paths with destination IPs or top outgoing interfaces and the destination ASNs. I could further enhance this visualization by mapping ASN to AS-Name using JOINs or lookups, which I have done below (lower right).
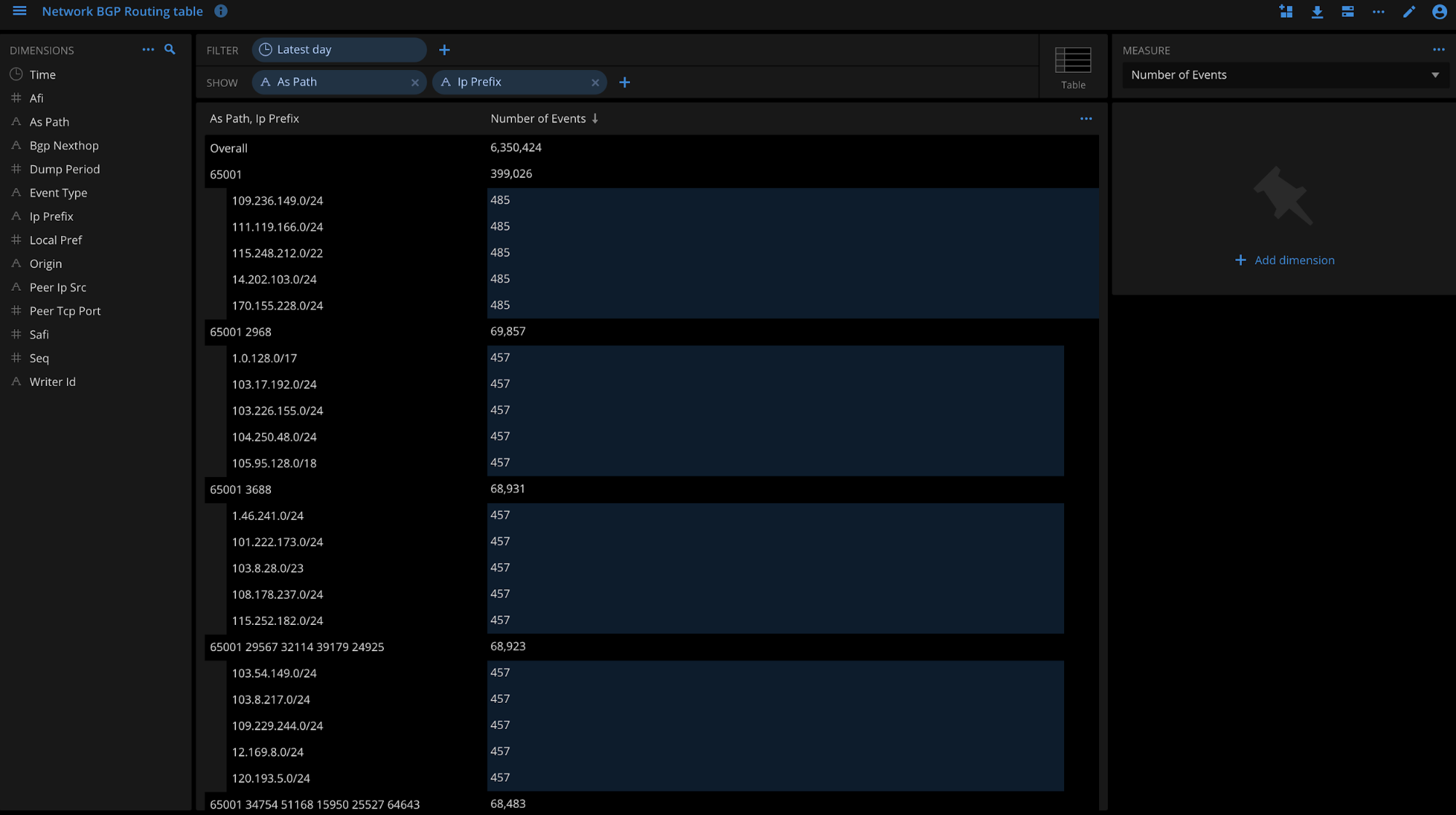
From my routing table I can use my dimensions to visualize data, for example, which AS_Paths do I use to reach my top prefixes.
In this blog we showed you how to combine the power of netflow with BGP routing to further enhance your network visibility. Whether you are a CDN, Service provider, mobile operator or just a large enterprise, BGP visibility matters. In the future please stay tuned for additional blogs providing a deeper dive into BGP analytics use cases and alerting.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...