Introduction
Real-time data processing has become crucial for decision-making across many industries — the proliferation of data in recent years has enhanced the ability of emerging technologies to process data efficiently and in large quantities. Now, processing data in real time is fundamental to how businesses operate and make decisions, and this importance will only continue to grow. We will go on to see new products and enhancements that bring more real-time data capabilities — from traditional analytics to stream processing tools — closer and closer to business users. In addition, the rapid evolution of AI is providing new features that will amplify the impact of real-time decision-making with use cases that are not currently possible.
Example use cases where real-time data is crucial today include, but are not limited to:
- Finance: Analyzing market trends or price movements that trigger automated action(s) based on algorithms and/or crucial insights that enhance decision-making.
- Retail: Improving operational stock efficiency using RFID (Radio-Frequency Identification) and providing real-time asset tracking and automated inventory management.
- Security: Moving to a proactive solution that identifies and mitigates potential threats through real-time data processing by applying advanced analytics and AI models to analyze patterns, detect anomalies, and predict potential threats instantly.
- Smart systems: Building a system embedded with capabilities to make decisions based on real-time data and predictive analytics like “Smart Transportation Systems” that optimize transportation logistics or traffic flow.
There are numerous real-time data architectures, and matching the right real-time data architecture to the specific use case is essential to success and achieving business value. In this Refcard, we will explore the following main factors of real-time data architectures: data volume, latency, historical data, complexity, and scalability.
Beyond the Architecture
The challenge of real-time data processing cannot be managed by architectural understanding alone. We must also consider a series of fundamental concepts.
Data Challenges
The “Three Vs” (Volume, Velocity, Variety) concept represents some of the bigger challenges in handling data in real-time environments:
- Volume: Managing and storing large volumes of data is sometimes more difficult with a real-time solution because large amounts of data can delay processing and cause missed opportunities or other business impacts due to delayed responses.
- Velocity: The speed at which new data is generated and collected can lead to bottlenecks, thus impacting the time in which the data can begin to be processed.
- Variety: Managing diverse data types requires a versatile solution to process and store different formats and structures. Often, a diverse range of data types is required to provide comprehensive insights.
On top of the “Three Vs,” other fundamental characteristics that are causing data solution challenges include those in the table below:
Table 1: Common data solution challenges
| Challenge | Description |
| Data freshness | Related to data velocity, data freshness refers to the “age” of the data, or how up to date the data is. Having the latest information is crucial to providing real-time insights. Imagine making decisions in real time based on yesterday’s prices and stocks. The velocity of the end-to-end solution will provide constraints and bottlenecks for the availability of the updated data. It is also important to be able to detect, predict, and notify on the data freshness used for making decisions and/or providing insights. |
| Data quality | A crucial aspect of data solutions that refers to the accuracy, completeness, relevance, timeliness, consistency, and validity of the data. Data quality is an unresolved problem due to the complexity of being able to analyze and detect these cases in large distributed solutions. Imagine we are providing a real-time analysis of sales during Black Friday and the data is not complete because the North American store data is not being sent; if it is not detected that the information is incomplete, any decision we make will be incorrect. |
| Schema management | Schemas need to evolve continuously and in alignment with the business’ evolution, including new attributes or data types. The challenge is managing this evolution without disrupting existing applications or losing data. Solutions must be designed to detect schema changes in real time and to support backward and forward compatibility, which helps to mitigate issues. As an example, a common approach is to use schema registry solutions. |
Performance
The performance of a solution lies in the attributes of efficiency, scalability, elasticity, availability, and reliability that are typically considered essential:
Table 2: Key components of real-time data performance
| Component | Description |
| Efficiency | Refers to the optimal use of resources to achieve output targets in terms of work performed and response times, using the least amount of resources possible and at an effective cost. |
| Scalability | A solution’s ability to increase its capacity as well as handle the growth of a workload. Traditionally, scalability has been categorized into vertical scalability (e.g., adding more resources to existing nodes) and horizontal scalability (e.g., adding more nodes); although nowadays, with serverless solutions in the cloud, this type of scaling is often transparent and automatic. |
| Elasticity | The capacity of a solution to adapt resources with the workload changes. This is closely related to scalability. A solution is elastic when it can provision and deprovision resources in an automated way to match current demands as quickly as possible. |
| Availability | How long the solution is operational, accessible, and functional. This is usually expressed as a percentage where higher values indicate more reliable access. |
| Reliability | Ensures solution capacity to continue working correctly in the event of a failure (fault tolerance) and the ability to recover from failures quickly and restore normal operation (recoverability). This is closely related to the availability of a solution: The challenge of durability and avoiding data loss is greatest in distributed real-time data solutions. |
Security and Compliance
Nowadays, with the rise of cloud solutions, the exposure of services to public networks and data protection laws, such as the General Data Protection Regulation (GDPR), make security and compliance two core components of any data solution.
Table 3: Security and compliance considerations for real-time data architectures
| Consideration | Description |
| Access control | Secures resources by managing who or what can view or use any given resources. There are several types of approaches: role-based access control (RBAC), attribute access control (ABAC), and rule-based access control. |
| Data in transit | The capacity to collect, store, and keep data for a duration. Data retention policies are crucial for organizations due to reasons like compliance with legal regulations or operational necessity. In addition to having the capacity to define these policies, the challenge lies with having simple mechanisms needed to manage them. |
| Data retention | The capacity of a solution to adapt resources with the workload changes. This is closely related to scalability. A solution is elastic when it can provision and deprovision resources in an automated way to match current demands as quickly as possible. |
| Data masking | Provides the ability to obfuscate or anonymize data to protect sensitive information in both production and non-production systems. In real-time data solutions where data is continuously generated, processed, and analyzed, data masking is very complex due to the impact on the performance. |
Architecture Patterns
Architecture patterns are key to effectively managing and capitalizing on the power of instantaneous data. These architecture patterns can be categorized into two segments: base patterns and specific architectures. While base patterns, like stream-to-stream, batch-to-stream, and stream-to-batch, lay the foundational framework for managing and directing data flow, specific architectures like Lambda, Kappa, and other streaming architectures build upon these foundations, offering specialized solutions tailored to varied business needs.
Base Patterns
The following patterns are fundamental to building complex data architectures like Lambda or Kappa, which are designed to manage scenarios of modern data processing.
Stream-to-Stream
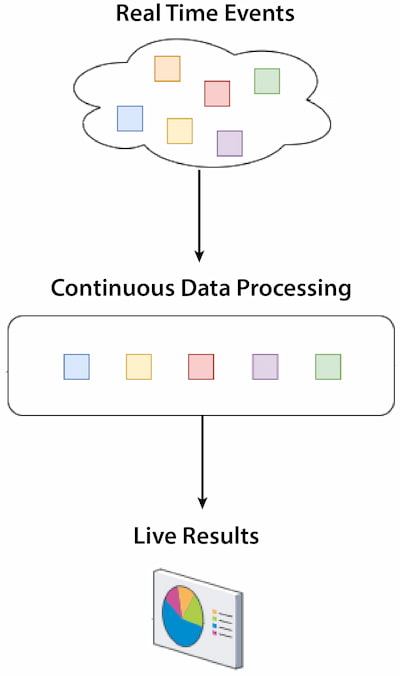
Stream-to-stream refers to a type of real-time data processing where the input and the output data streams are generated and processed continuously. This approach enables high reactivity, analysis, and actions.
Figure 1: Stream-to-stream
Batch-to-Stream
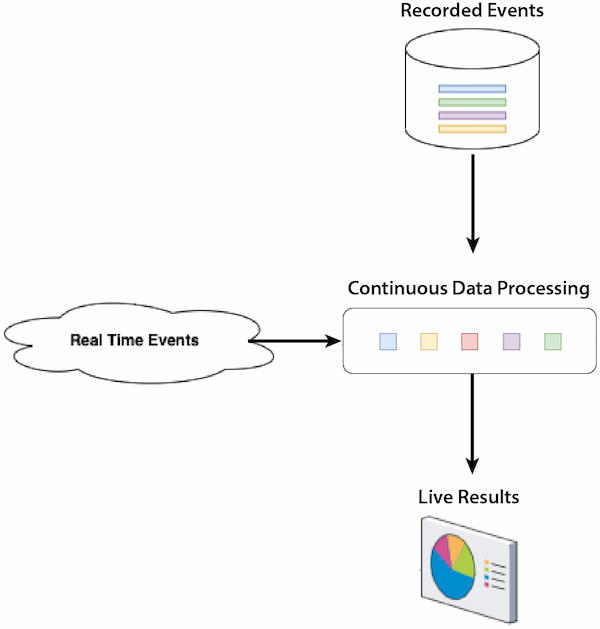
Batch-to-stream typically involves the conversion of any data accumulated (batch) in a data repository into a structure that can be processed in real time. There are several use cases for this implementation like integrating historical data insights with real-time data or sending consolidated data in small time windows from a relational database to a real-time platform.
Figure 2: Batch-to-stream
Stream-to-Batch
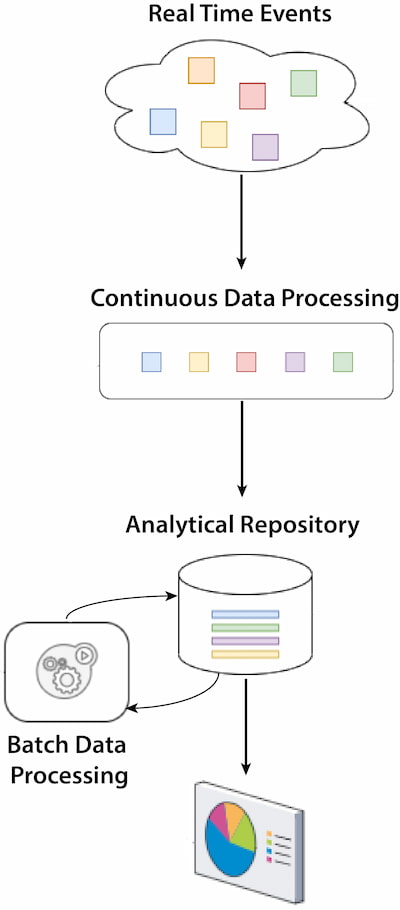
This pattern is oriented toward scenarios where real time is not required; bulk data processing is more efficient and meets most business requirements. Often, the incoming data stream is accumulated for a time and then processed in batches at scheduled intervals.
The stream-to-batch pattern usually happens in architectures where the operational systems are event- or streaming-based and where one of the use cases requires advanced analytics or a machine learning process that uses historical data. An example is sales or stock movements that require real-time and heavy processing of historical data for forecast calculation.
Figure 3: Stream-to-batch
It is essential to understand the requirements and behavior of any end-to-end solution. This will allow us to identify which architectures are best suited for our use cases — and consider any limitations and/or restrictions.
Lambda Architecture
Lambda architecture is a hybrid data pattern that combines batch and real-time processing. This approach enables complex decisions with high reactivity by providing real-time information and big data analysis.
Figure 4: Lambda architecture — Unified Serving Layer
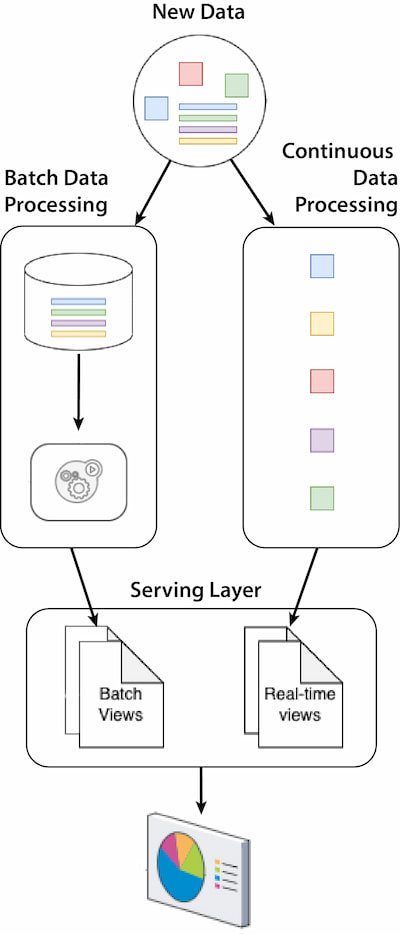
Figure 5: Lambda architecture — Separate Serving Layer
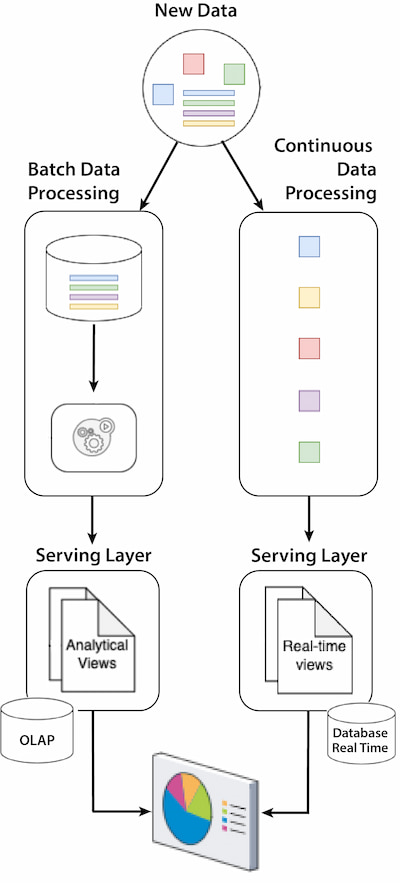
Components:
- Batch layer: Manages the historical data and is responsible for running batch jobs, providing exhaustive insights.
- Speed layer: Processes the real-time data streams, providing insights with the most up-to-date data.
- Serving layer: Merges the results obtained from the batch and speed layers to respond to queries with different qualities of freshness, accuracy, and latency.
- There are two scenarios: one in which both views can be provided from the same analytical system using solutions like Apache Druid and another using two components like PostgreSQL as a data warehouse for analytical views and Apache Ignite as an in-memory database for real-time views.
Advantages:
- Scalability: This has a higher scalability because real-time and batch layers are decoupled so that they can scale independently — both vertically and horizontally.
- Fault tolerance: The batch layer provides immutable data (raw data) that allows recomputing information and insights from the start of the pipeline. The recomputation capabilities ensure data accuracy and availability.
- Flexibility: This allows the management of a variety of data types and processing needs.
Challenges:
- Complexity: Managing and maintaining two layers increases the effort and resources required.
- Consistency: This refers to the eventual consistency between both layers that can be challenging for the data quality process.
Kappa Architecture
Kappa architecture is designed to represent the principles of simplicity and real-time data processing by eliminating the batch processing layer. It is designed to handle large datasets in real time and process data as it comes in. The goal is to be able to process both real-time and batch processes with a single technology stack — and as far as possible with the same code base.
Figure 6: Kappa architecture
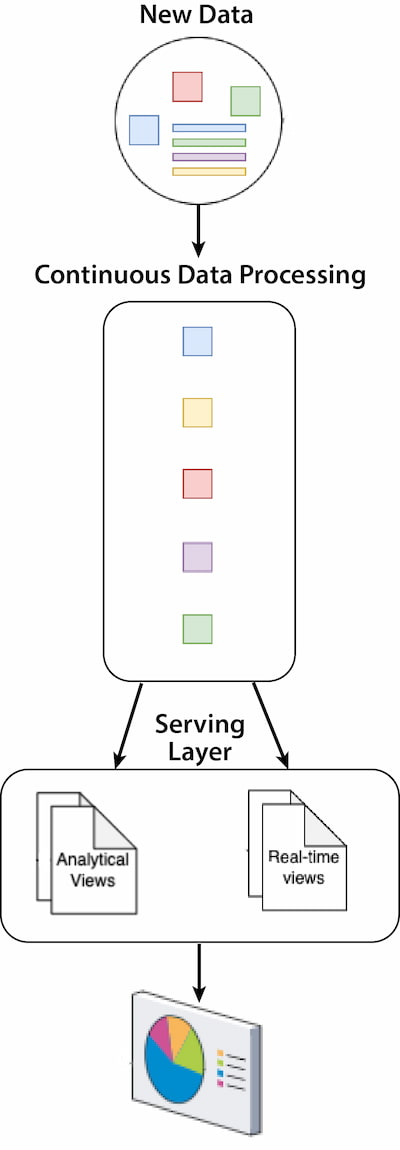
Components:
- Streaming processing layer: This layer manages the historical data and is responsible for running batch jobs, providing exhaustive insights. It allows the reprocessing of historical data and, therefore, becomes the source of truth.
- Serving layer: This layer provides results to the users or other applications via APIs, dashboards, or database queries. The serving layer is, indeed, typically composed of a database engine, which is responsible for indexing and exposing the processed stream to the applications that need to query it.
Advantages:
- Simplicity: Reduces the complexity of an architecture like Lambda by handling processing with a single layer and one code base.
- Consistency: Eliminates the need to manage the consistency of data between multiple layers.
- Enhanced user experience: Provides crucial information as the data comes in, improving responsiveness, decision-making, and user satisfaction.
Challenges:
- Historical analysis: Focused on real time and may not have the capabilities to perform in-depth analyses on large historical data.
- Data quality: Ensuring exactly-once processing and avoiding duplicate information can be challenging in some architectures.
- Data ordering: Maintaining the order of real-time data streams can be complex in distributed solutions.
Streaming Architecture
Streaming architecture is focused on continuous data stream processing that allows for providing insights and making decisions in or near real time. It is similar to the Kappa architecture but has a different scope and capabilities; it covers a broader set of components and considerations for real-time scenarios from IoT, analytics, or smart systems. On the other hand, Kappa architecture can be considered an evolution of Lambda architecture, aiming to simplify patterns; although, it is often the precursor to streaming data architectures.
Components: The continuous data processing layer of a streaming architecture is more complex than other architectures like Kappa as new products and capabilities have emerged over the years.
- Stream ingestion layer: This layer is responsible for collecting, ingesting, and forwarding the incoming data streams to processing layers and is composed of producers and source connectors. For example, nowadays, there are layers of connectors to enable seamless and real-time ingestion of data from various external systems into streaming platforms like Debezium for databases, Apache Kafka Connect for several sources, Apache Flume for logs, and many others. This layer plays a crucial role that can impact a solution’s overall performance and reliability.
- Stream transport layer: This layer is the central hub/message broker for data streaming that handles large volumes of real-time data efficiently and ensures data persistence, replicability, fault tolerance, and high availability, making it easier to integrate various data sources and data consumers, like analytics tools or databases. Apache Kafka is, perhaps, the most popular and widely adopted open-source streaming platform; although, there are other alternatives like Apache Pulsar or other private cloud-based solutions.
- Streaming processing layer: This layer is responsible for processing, transforming, enriching, and analyzing real-time-ingested data streams using solutions and frameworks like Kafka Streams, Apache Flink, or Apache Beam.
- Serving layer: Once data has been processed, it may need to be stored to provide both analytical and real-time views. In contrast to Kappa, the goal of this solution is not to simplify the stack but to provide business value so that the serving layer can be composed of different data repositories like data warehouses, data lakes, time series databases, or in-memory databases depending on the use case.
Advantages:
- Real-time insights: Enables users and organizations to analyze and respond as the data comes in, providing real-time decision-making.
- Scalability: Usually, these are highly scalable platforms that allow for managing large volumes of data in real time.
- Enhanced user experience: Provides crucial information as the data comes in, improving responsiveness, decision-making, and user satisfaction.
Challenges:
- Historical analysis: Focused on real time and may not have the capabilities to perform in-depth analyses on large historical data.
- Data quality: Ensuring exactly-once processing and avoiding duplicate information can be challenging in some architectures.
- Data ordering: Maintaining the order of real-time data streams can be complex in distributed solutions.
- Cost-effectiveness: It is, indeed, a significant challenge because this architecture requires continuous processing and often the storage of large volumes of data in real time.
Change Data Capture Streaming Architecture
Change data capture (CDC) streaming architecture is focusing on capturing data changes in the databases, such as inserts, updates, or deletes. Then, these changes are converted to streams and sent to other streaming platforms. This architecture is used in several cases such as synchronized data repositories, real-time analytics (RTA), or maintaining data integrity across diverse environments.
Components:
- Capture layer: This layer captures changes made to the source data, identifies data modifications, and extracts changes from the source database.
- Processing layer: This layer processes the data and can apply transformations, conversion, mapping, filtering, or enrichment to prepare data for the target data repository.
- Serving layer: This layer provides access to the stream data to be consumed, processed, and analyzed, thus triggering business processes and/or persisted data in the target system to be analyzed in real time.
Advantages:
- Real-time synchronization: Enables the synchronization of data across different data repositories, ensuring data consistency and integrity.
- Reduce load on source database: By capturing only the changes on the source data and sending them to several targets, the load on the source database decreases significantly compared to full data extractions or multiple extractions.
- Operational efficiency: Automate data synchronization processes, minimizing the risk of errors.
Challenges:
- Data consistency: Ensuring data quality across a distributed system can be challenging when the data is distributed to many destinations.
- Error handling: Providing a robust mechanism to handle errors across the different layers is a complex solution when the data is sent to several systems.
Reference Architecture: Streaming Architecture With Apache Kafka and Apache Druid
Apache Kafka and Apache Druid are two open-source analytics tools that combine results into a formidable architecture, harmonizing high-speed data streams and large data volumes with robust real-time analytics. In addition, Apache Druid is best integrated with Apache Kafka, optimizing its capabilities and leveraging the full power of the analytical experience.
Figure 7: Reference architecture
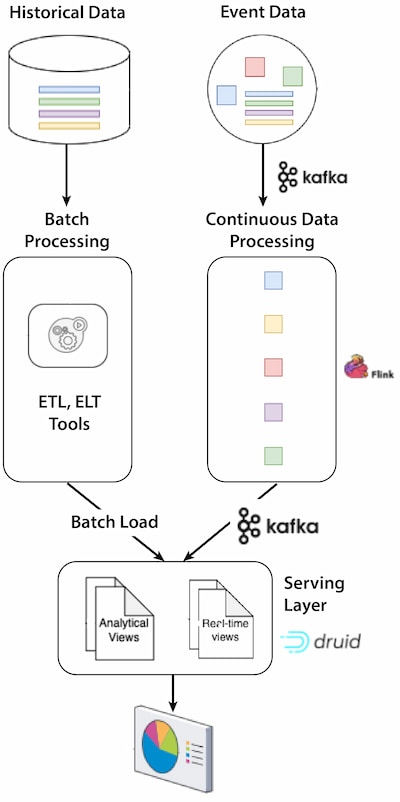
As shown in Figure 7 above, the reference architecture features:
- Apache Kafka: Acts as a high-throughput messaging system to ensure scalability, reliability, low latency, and a decoupled architecture. Kafka’s role is pivotal because it decouples data producers, stream processors (Flink), and data consumers (Druid), allowing them to operate at different paces and ensure smooth data flow.
- Apache Flink: Acts as a real-time stream processing engine that can continuously process, analyze, and manipulate the data flowing from Apache Kafka. It can then produce any processed data as Kafka topics and be consumed by Apache Druid.
- Apache Druid: Real-time data repository that stores, indexes, and provides data exploration and analytics.
In this architecture, the data flows through several stages:
- Streaming data ingestion: The data journey begins with the publication of the data to Kafka Topics.
- Streaming transport: Topics and Apache Kafka act as stream channels that carry the data to Apache Druid.
- Streaming processing: Data is processed by Apache Flink, stored in Apache Kafka, and finally ingested into Apache Druid, optimizing the format for analytics interaction.
- Serving layer: Analytical processes and users access the data using Apache Druid via APIs, JDBC, and/or HTTP.
- Batch processing: The method for ingesting historical data is batch ingestion (also known as bulk load). This method is particularly suited for backfilling data, ingesting large volumes of historical data, or periodic dumps from batch ETL jobs.
This solution is a good option when looking for a platform that is simply oriented to real-time analysis but also allows historical data analysis.
Apache Druid
Apache Druid is part of a new era of revolutionary OLAP (online analytical processing) data repositories that combine real time and batch analysis, thus providing a versatile, scalable, and high-performance solution designed to meet the evolving analytical needs of modern businesses.
Key features for Apache Druid and other RTA solutions include:
Table 4: Important real-time analytics platform features
| Feature | Description |
| Low latency queries | Executes OLAP queries in milliseconds with high cardinality and dimensional datasets using billions of rows without pre-defining or caching queries in advance. |
| High concurrency | Supports 100s to 100,000s of queries per second at a consistent performance. |
| Unified analytical experience | This allows seamless analysis between the present and the past. Queries that work with the most recent events are handled by real-time tasks that keep relevant data in memory. On the other hand, queries that require historical data are managed by a historical process. All this management is done transparently for the user and managed by the query engine. |
| Dual ingestion protocols | Loading data is supported by two ingestion methods: streaming and batch. Streaming ingestion is controlled by a continuously running supervisor on Apache Kafka; however, batch ingestion is managed by the controller tasks that provide several ingestion patterns. |
| Columnar storage | The innovative columnar storage format ensures optimal data compression and query performance. |
| Optimized data format | Ingested data is automatically columnized, time-indexed, dictionary-encoded, bitmap-indexed, and type-aware compressed. |
| Time-based partitioning | By partitioning the data according to their dates, queries on time ranges are considerably accelerated. |
| Schema auto-discovery | This can automatically detect, define, and update column names and data types upon ingestion, providing the ease of schemaless and the performance of strongly typed schemas. |
Apache Kafka
Apache Kafka is an open-source stream-processing platform designed to build real-time pipelines. It is horizontally scalable and fault tolerant. Nowadays, it runs in production for thousands of companies, providing robust and scalable real-time data streaming solutions.
Some of Apache Kafka’s advantages include:
- High throughput: Handles high volumes of data, enabling the processing of hundreds of megabytes to terabytes of data per second.
- Scalability: Scales out horizontally to handle higher loads; more nodes can be added to the cluster to increase capacity and throughput.
- Fault tolerance: Supports data replication to prevent data loss. If a broker or a node fails, data is restored from the replicated copies.
- Durability: Persistently stores data, ensuring no loss of data due to crashes, and maintains data safely until it is consumed.
- Low latency: Capable of providing end-to-end latency as low as possible, often within milliseconds, allowing real-time analytics.
When used in combination with Apache Kafka, your RTA solution can provide several additional capabilities:
Table 5: Integrating RTA solutions with Apache Kafka — key capabilities
| Capability | Description |
| Apache Kafka integration | As an example, Apache Druid has native connectivity with Apache Kafka, which allows real-time ingestion of streaming data without the need for a Kafka connector. When data is received from a Kafka topic, the Kafka indexing service processes the messages, transforms them into Druid’s internal data format, and indexes them into Druid’s data stores. This means that streaming data is made immediately available for querying and analysis. |
| Event-based ingestion | Out-of-the-box integration with Apache Kafka enables event-by-event ingestion; data is ingested into memory and made immediately available for use. In the background, the events are indexed and committed to longer-term storage. |
| Query-on-arrival | As soon as data is ingested into Apache Druid, users can run queries on this data, enabling real-time analytics and insights without having to wait for batch processing or data indexing to complete. This is made possible by event-based ingestion. |
| Continuous backup | This creates a backup of the data continuously in conjunction with the Kafka indexing service. It continuously persists ingested events into deep storage, such as an object store like Amazon S3, to enable zero data loss in the event of a system failure. |
| Guaranteed consistency | Apache Druid enables reliable and accurate data processing through the combination of its Kafka indexing service and the inherent features of Kafka. When data in a Kafka topic has been committed to a Druid segment, it is processed and consumed from Kafka. Druid’s indexing service keeps track of the consumed offsets and commits them to Kafka, indicating successful processing. In the event of failures or interruptions during ingestion, Druid’s Kafka indexing service utilizes Kafka’s offset management and commit features to achieve exactly-once semantics. |
| Fault tolerance | In case of failures, such as hardware outages or accidental data corruption, Druid enables easy and fast recovery. It’s as simple as watching Druid automatically rehydrate data nodes from deep storage. |
The evolution of Apache Kafka over the years is marked by a continuous stream of enhancements, improvements, and new features aimed at addressing the growing demands of modern, data-driven applications.
Conclusion
There are several key data architecture patterns — each one with its strengths, limitations, and use cases. The architecture we choose plays a pivotal role in determining performance, adaptability, and business impacts. However, the knowledge of these architectures alone won’t guarantee success because there are other factors to consider, such as adequate training, team size, cost, or even organizational culture, that may affect decision-making.
The success of real-time data processing lies in the art of aligning a suitable architecture pattern with the right use case and external factors. A mismatch could lead to increased costs, complexity, and even a business impact. Choosing the right real-time solutions and architectures can provide a significant competitive advantage when we truly unlock the vast potential of real-time data, driving innovation, efficiency, and success in an increasingly connected world.