SQL-based Transformations and JSON Columns in Imply Polaris
Oct 12, 2022
Timmy Freese
Transformations
There’s no “I” in “Team”, but there is a “T” in “ETL”. An important feature of any database is the ability to transform data during ingestion and query. Imply Polaris supports both. As an example, consider the situation where a company records its Total Revenue in a ‘total_revenue’ column and its Total Expenses in a ‘total_expenses’ column. If an analyst at the company wants to know the company’s Net Profits, they can implement a simple transformation of ‘total_revenue – total_expenses’.
Older versions of Imply provided users with the ability to perform transformations during ingestion using a native ingestion spec and during query using SQL. Now, Imply also enables SQL-based transformations during ingestion time. This much simplified user flow has been carried through to Imply’s DBaaS, Polaris.
To transform data using SQL expressions during ingestion, users can POST an ingestion job using the Polaris API or use the UI to enter an expression such as ‘total_revenue – total_expenses’ while editing the table’s schema. Additionally, when working with a rollup table, you can apply a variety of aggregation functions on measures, including MIN, MAX, SUM, and COUNT.
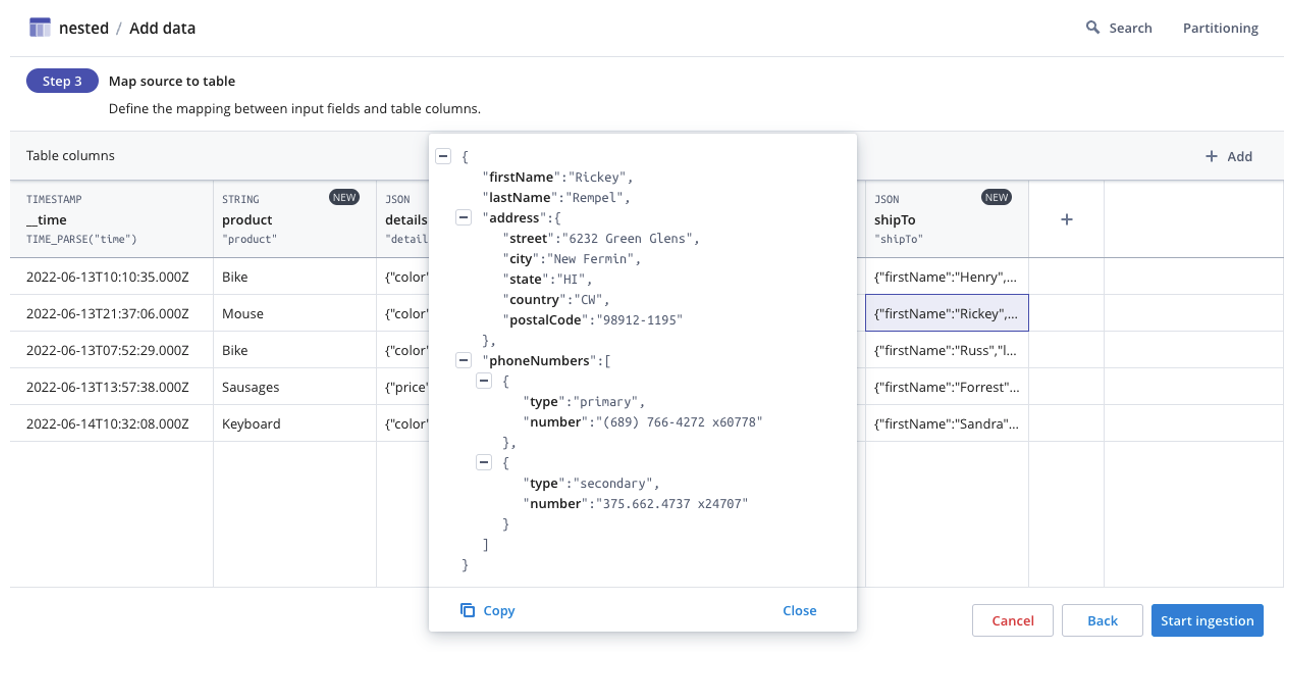
JSON Columns
In addition to being able to transform your data at ingestion, you can also work with nested data in Polaris. The world is a messy place, and capturing events in a fully structured way is often infeasible. Sometimes data comes in a semi-structured form and users will want to give this data additional structure. Polaris supports nested data with the JSON datatype. Additionally, users can add more structure to this JSON datatype using the JSON_VALUE transformation and other SQL JSON functions, available via API and UI. For more information about nested data in Polaris, see Ingest nested data in the Polaris documentation.
Enabling real-time analytics with transformations and JSON columns in Polaris is one of the many ways in which we are powering the next generation of m
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...