Every effective website and application exists to offer a route for its visitors to achieve some goal: clicking on a button to sign up, following a link to gain a deeper understanding, or simply viewing an asset to raise general awareness. The routes to completing these goals are ingrained in the very essence of the application – they define its reason for existing. All manner of hypermedia and both human and automated logic is used to create an experience where people are encouraged to follow a path to carry out some course of action.
Collecting data about how users interact with your website or application gives product managers, customer experience engineers and marketers the metrics they need to analyze the efficacy of those pathways. And, with this data and analysis, they can iteratively improve the designs to make that journey simpler, more engaging, and less time-consuming.
This analysis, commonly referred to as clickstream analysis, has broad market applicability, having started with company websites in the 90s and evolved to e-commerce sites, SaaS applications, mobile apps, game interactions and consumer IoT devices.
Applications such as Google Analytics and Adobe SiteCatalyst (previously Omniture) exist to help with clickstream analysis. However, these applications have scale limitations and lack access to raw data. When site operators and application teams hit these limits, they frequently turn to Apache Druid. In this blog post, we’ll deep dive into how you can easily build your own custom and scalable clickstream analysis engine using Druid.
Introduction
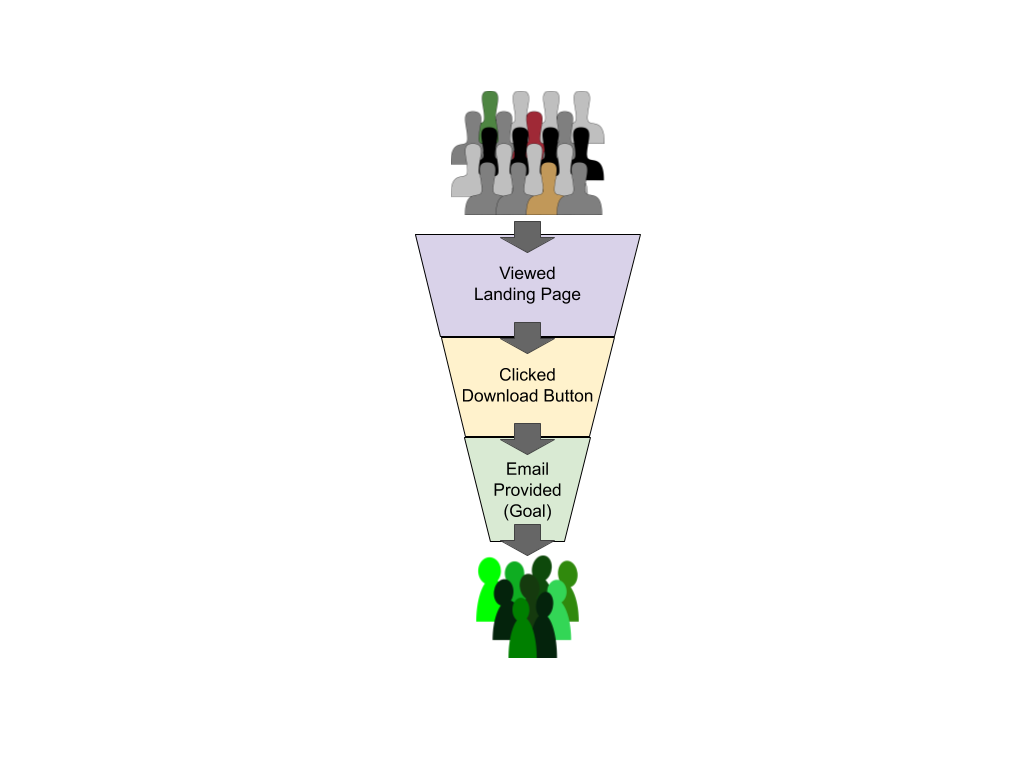
A funnel is a visual representation of the journey a user took to reach your goal. Imagine one objective of your website is to collect email addresses to drive the sales pipeline. For this objective, you create a landing page that provides valuable content in exchange for the user’s email address. This simple example involves just 3 steps that the user must take:
Go to the landing page,
Click a link/button to download, and
Enter an email address.
Fewer people will click “download” than go on to the landing page itself. Fewer people still will enter their email address. Visually then, this looks like a funnel – with the entry point at the very top. At the exit point are those visitors who completed the entire journey and achieved our objective for them: in this case, entering their email address to download the content from our landing page.
Analysis of the funnel is critical to learning from design decisions: how long did it take to get from the top to the bottom? What kinds of people abandoned their journey half-way through? When we made a change to page X, did it improve conversion rates from one step to the next?
It’s easy to see why funnel analysis has become such an important technique in designing user journeys.
Preparing for Funnel Analysis
You’ll need three things to build your funnel:
A stream of data that describes actions being taken by users: the “events”,
A way of determining which events evidence activity at a stage of your funnel: the “map”, and
A way to explore the collected data by generating useful metrics quickly.
User Activity Events
Every activity or action performed by a user that relates to your objectives for them needs to be recorded so it can be easily analyzed.
The types of activities that get recorded will vary from application to application but are likely to include events such as “page viewed”, “link clicked”, and “form completed”.
And while the actual content of those recorded events will also vary, they are more than likely going to include at least:
What was attempted?
When was this attempt made?
Who tried to do it?
Did they succeed?
Here’s an example of an event record in JSON format recording that a user with ID 45 viewed the home page on Monday 29th April 2019 at 15:13 UTC:
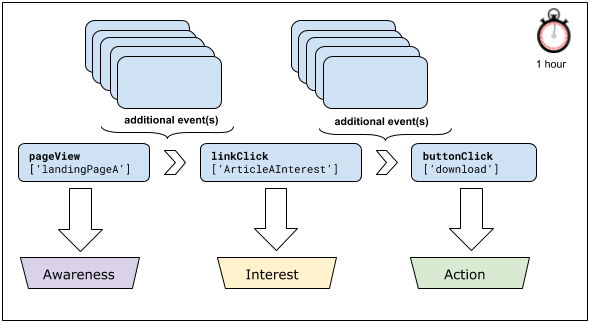
Once you have determined which events are being recorded, you can map these onto the stages of your funnel. Remember that your application may be capturing more events than are actually needed for your analysis. Identify those events that indicate a significant change in behavior and ignore the rest. In the diagram below, you can see that we have identified three very clear stages: all the rest we’re just noting as “additional event(s)” and can be ignored.
Computing Metrics
Now that we know the events, and we have mapped these to the funnel, what kinds of answers might we want?
How many users viewed the page but did not click the link?
Of the users that did not click the link, how many went on to do something else on this site?
How much time, on average, did the visitors spend on the page before they clicked on the article link?
For most funnel analysis, approximate answers to these questions are perfectly acceptable: we want an indication of typical behavior, not to submit an audit report to the tax office. We need real-time statistics that help us improve the design, the feel, the experience of our application: we simply don’t need exact figures for this creative exercise.
You may ask “why not get an exact answer”. In short, at scale you may not be willing to wait minutes for an exact answer, whereas an approximate answer using innovative techniques I describe below may take a second or less instead. This time difference is especially true if the query is part of an ad hoc and iterative data exploration where the answer to the last question informs the next one in real-time.
A key advantage of using Apache Druid, an open source data base built for real-time ad hoc analytics, is its support for a super fast, super efficient open source library to generate approximate statistics. This library, known as the DataSketches library, dramatically speeds up calculations for this kind of analysis. In fact, it’s used every day for real-time, on-the-fly statistical analysis on extremely large, extremely busy websites.
Apache Druid provides access to these algorithms through an extension called the Theta Sketch module. For operations like those needed for funnel analysis, this module is exactly what we need. It will help us answer the questions posed in the previous section very quickly and efficiently.
Sample Funnel Analysis
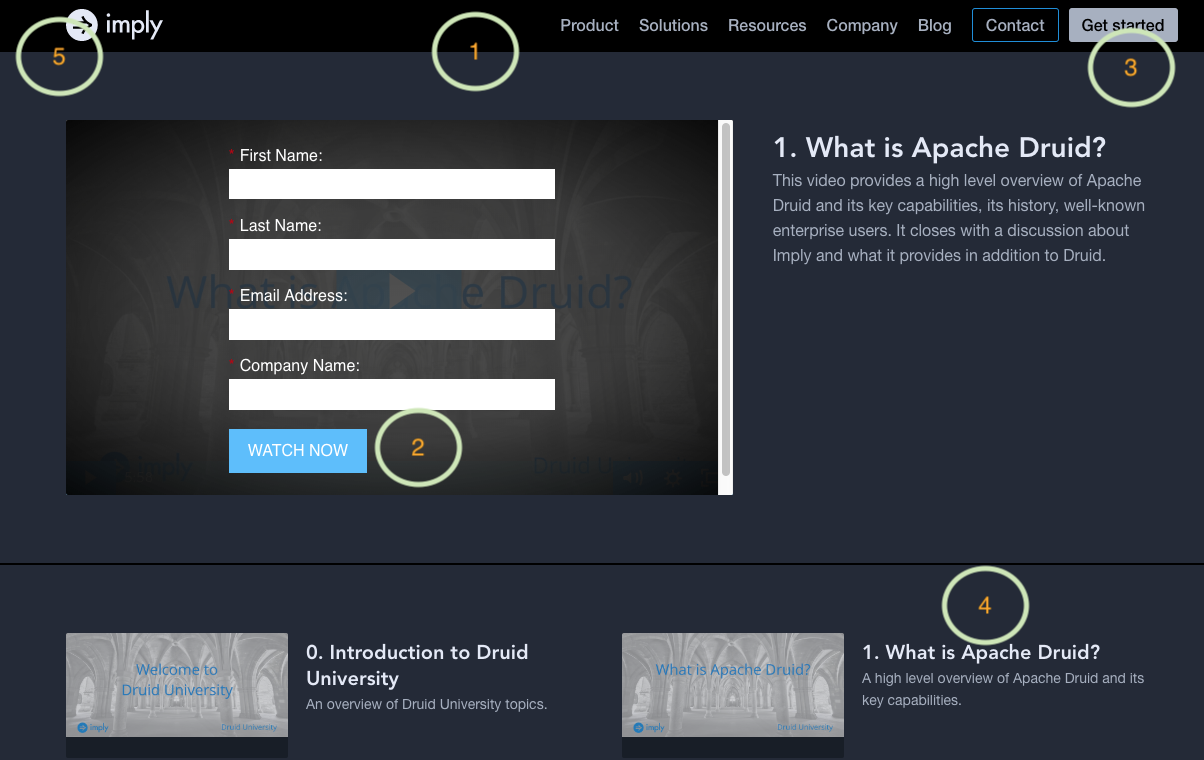
Now we’ve understood the business needs, let’s get technical with a concrete example using the Druid University landing page from imply.io’s website. This example has a funnel that is identical to the one we defined in our earlier examples: the desired objective is to provide the user with valuable information in exchange for their contact details.
There are a number of user activity events that may be collected on this page. Let’s focus on the 5 highlighted below for this discussion:
Event Collection
In a previous blog post, we discussed using Divolte for collecting user activity events. Whether you use this open source framework or something else, we’ll assume you are ultimately sending these events to a Kafka topic in the JSON format described earlier. We’ll set up Druid to retrieve the events from Kafka.
Data Model
Before we load our data into Druid, let’s take a minute to model the data from our application event data into a Druid datasource named “events”. Druid gives you very fast response times to queries of large datasets. Since performance is usually one of the primary reasons for using Druid, it makes sense to take a minute to think about how the data will be ingested into Druid.
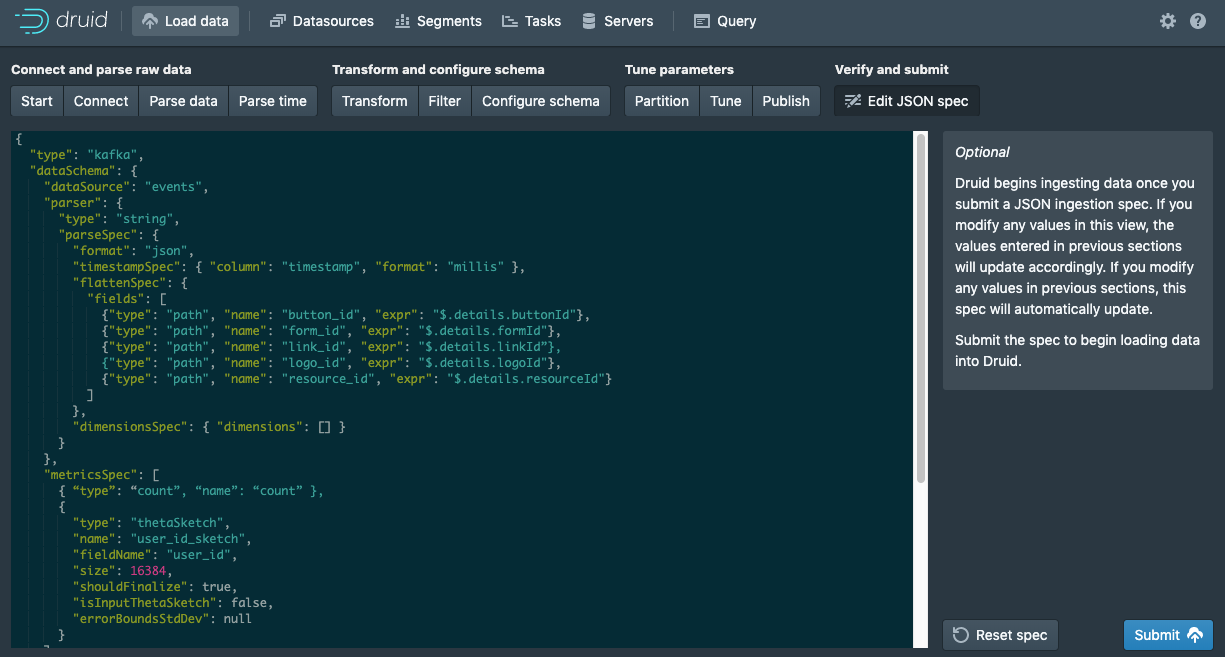
Each row in the datasource will store a single event and its related attributes. Since Druid does not natively store nested objects in a queryable format, we will flatten the details sub-object as part of the ingestion process. For example, the 2 attributes linkId and videoId in the showVideo linkClick details sub-object will become top level link_id and video_id dimensions in the Druid datasource. Similarly, button_id, form_id, and resource_id will be made top-level dimensions from their respective objects. Once complete, the events schema will look like this:
Ingestion
If you have not done so already, download and unpack the latest version of Apache Druid. Whether you are using a full cluster or single node installation, be sure to start the services so they are ready for ingesting data.
Once the services are started, you can use the visual Data Loader available in Druid 0.15 to set up ingestion from a Kafka topic in minutes. Step through the workflow to build your ingestion spec.
Let’s take a look at an example ingestion spec generated by the Data Loader:
Notice that you calculate and store the sketch object as a metric with each row in your Druid datasource as you ingest data with this addition to the metricsSpec:
The metric value, computed and stored in user_id_sketch, effectively stores a Set data structure representing an approximation of the unique user_id values. The configurable size represents the maximum number of entries that can be stored. The value of 16384 is the default and is sufficient for most use cases. In the next section, we’ll look at how queries read this value to perform calculations from it.
Before you start loading data, be sure you have added the druid-datasketches extension to your druid.extensions.loadList in common.runtime.properties.
Data rows will begin being ingested once the ingestion spec has been submitted to the Druid overlord. If you are using the Druid Console Data Loader, simply click the Submit button in the Edit JSON spec step. Otherwise, POST the spec to the overlord endpoint.
Query
With data flowing into Druid, we can now start to get answers to our questions.
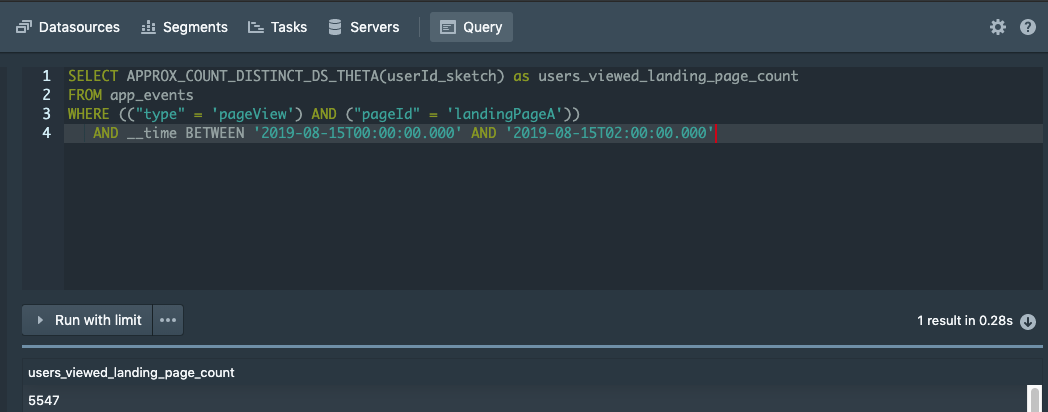
In particular, let’s count the number of users at the first stage of the funnel (i.e., those that viewed the landing page) for a specific 2 hour window (08/15/2019 00:00 – 02:00):
SELECT APPROX_COUNT_DISTINCT_DS_THETA(user_id_sketch) as users_viewed_landing_page_count
FROM app_events
WHERE (("type" = 'pageView') AND ("page_id" = 'landingPageA'))
AND __time BETWEEN '2019-08-15T00:00:00.000' AND '2019-08-15T02:00:00.000'
Using SQL, the APPROX_COUNT_DISTINCT_DS_THETA function is used to calculate the number of unique users from the pre-computed theta sketch and the associated library. We can run a similar query to get the results of each stage of the funnel. For example, to count the users in stage 2 who clicked the “Watch Now” button, we run this query:
SELECT APPROX_COUNT_DISTINCT_DS_THETA(user_id_sketch) as users_clicked_download_count
FROM app_events
WHERE (("type" = ‘buttonClick’) AND ("button_id" = ‘watchNow’))
AND __time BETWEEN '2019-08-15T00:00:00.000' AND '2019-08-15T02:00:00.000'
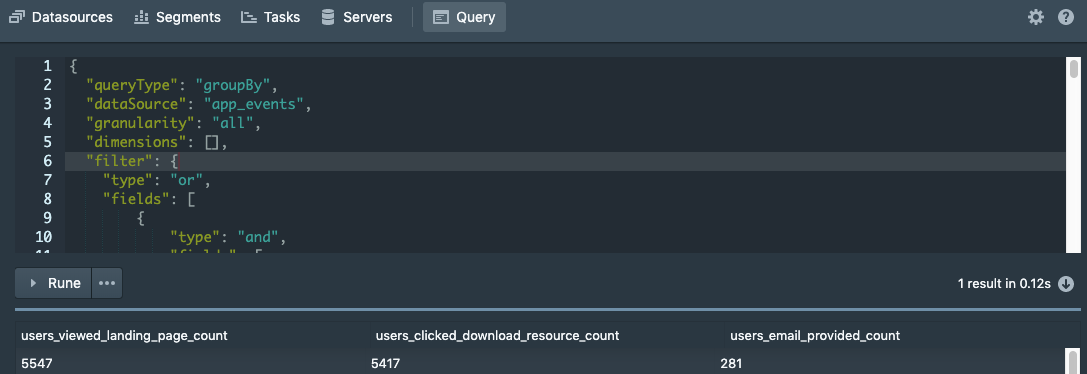
If you are more comfortable with the native Druid query language, you can write the above two queries in one using this query:
You can run this query from the Druid Console Query tab or by simply sending a POST request to the Druid Broker or Router.
The results will show you how many users completed the first two steps of the funnel.
The native query language provides us with some additional benefits including post aggregations that open up additional possibilities. For example, recall that the theta sketch value is, in essence, a Set data structure that maintains a unique set of user. Because of this we can perform set operations such as union and intersection on the results.
In some instances, it may be helpful to perform an intersection of users who performed 2 steps. That is, intersect the group of users that performed step 1 with those that performed step 2 and output the results showing everyone who did both step 1 and step 2. In our example, you cannot click the “Watch Now” button without first viewing the page so this intersection is not needed. But, if it were required, you would simply add a post aggregation to your native query:
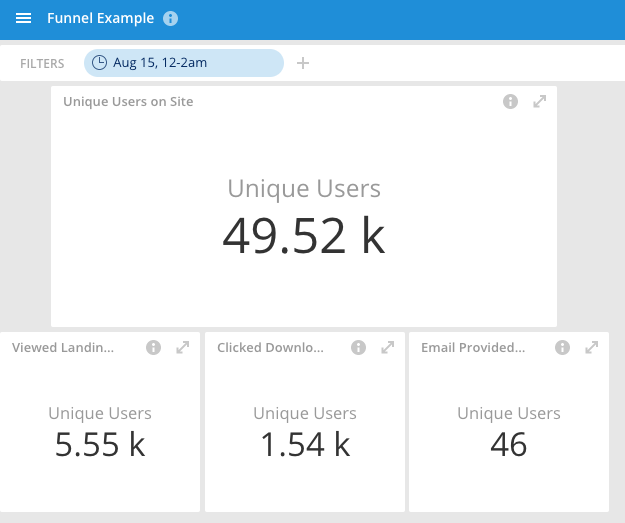
You aren’t limited to running SQL or native queries to get results. You can also use visualization tools like Imply Pivot, or your favorite traditional UI (e.g. Tableau, Looker) to create a dashboard and drag-and-drop interactive charts showing you the results in a live view:
These tools make the data more accessible to non-technical users and allow you to compare one week to another or one version to another with ease.
Summary
Over the past two decades the business world has been instrumented to capture every transaction and interaction as it happens. Thus clickstream analysis has evolved from being a website performance method to one that captures an increasing range of business performance metrics, by processing a wide variety of data at tremendous speed and scale.
Using Apache Druid along with the Data Sketches library provides a fast and scalable design to analyze conversion funnels that synthesize billions of rows of data for dozens or hundreds of concurrent users. If your current tools can no longer scale to meet the load of your users and the magnitude of events collected, then check out how Druid can help.
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...