Whether you are new to Apache Druid® or you’ve been using it for years, it’s always a good idea to invest some time and effort into creating a plan.
Project Planning Checklist
- Purpose
- Queries
- Data Sources
- Visualization
- Infrastructure
- Documentation
Purpose
Why are you doing this project? Are you creating something new, to enable interactive data conversations? Are you gathering IoT streams for subsecond analysis in historical context? Do you have an application that was originally created using some other database and you’ve outgrown its capacity for concurrency, scale, or speed?
Documenting the project’s purpose doesn’t need to be (and usually shouldn’t be) an exhaustive technical specification. Any project worth doing should be describable in 2-3 clear sentences, using clear language and avoiding technical jargon and “speeds ‘n’ feeds”. The purpose should be clear to the technical team and also clear to non-technical people who will be affected by the project.
A few examples:
- We have a data warehouse which is great for queries where we don’t care about how long it takes to run (like daily sales reports or weekly shipping reports), but sometimes we need to know what’s happening right now, and get answers that are up-to-the-minute or up-to-the-second. In this project, we will be adding Druid as a second data engine, so we’ll be able to use Druid when real-time matters and our existing data warehouse when it doesn’t.
- To protect our customers from fraud, we use machine learning to create predictive models, then run inferences to identify risk from different activities for each customer. When each customer interacts with us, we only have a few hundred milliseconds to check those inferences and decide to block activity that has a high risk of fraud, without causing delays for legitimate activities. We’ll use Druid as a database of customer inferences where we can be sure of subsecond performance, even for complex retrievals across multiple customers.
- We’re ingesting IoT streams from many, many devices and creating dashboards for our customers to use. We built our solution using a time-series database, which is very fast when there is only a few queries, but it gets much slower when we have many customers running concurrent queries. We also are spending a lot of engineering time modifying schemas when the devices are updated and change the data they report. Our project will upgrade the database to Druid, which can handle all of our needs for both concurrent queries and auto-schema detection from changing sources.
A clear and simple purpose statement explains the project to stakeholders. It’s also useful to frame the project through its lifecycle, helping to avoid “feature creep” as the project progresses.
Queries
As a database, the purpose of Druid is to execute queries. Understanding what sort of queries you want to run will define your data schema and your infrastructure needs. You won’t know in advance every query that you might need for your project, but you should be able to forecast the most common queries that will be needed.
While Druid is high performance at any scale, it can execute queries faster and cheaper when you use aggregates and approximations.
Aggregates, also called rollups, combine multiple rows into a single metric. For example, if you are doing clickstream analytics where you ingest an average of 10,000 events per second spread across 100 web pages, your table will grow by 864 million rows per day.
2023;8;13;3;29;24023;1;A15;14;5;2;33;2;1
2023;8;13;4;29;24023;1;A16;1;6;1;33;2;1
2023;8;13;5;29;24023;4;P11;4;4;2;38;1;1
2023;8;13;6;29;24023;4;P18;2;6;1;28;2;1
2023;8;13;7;29;24023;4;P13;4;5;1;38;1;1
2023;8;13;1;29;24024;2;B10;2;4;1;67;1;1
2023;8;13;1;9;24025;1;A11;3;4;1;62;1;1
2023;8;13;1;34;24026;1;A2;3;1;1;43;2;1
2023;8;13;2;34;24026;3;C2;12;1;1;43;1;1
2023;8;13;3;34;24026;2;B2;3;1;2;57;1;1An example of clickstream data. The 7th field (A15, P13, …) is the code for the webpage.
Do your queries really need that level of precision? If you are looking to understand directional changes in web activity, perhaps you could rollup per page per second. This would grow the table by 8.64 million rows per day. Or maybe you could rollup per minute, yielding only 144 thousand rows per day.
Of course, you could do both, creating a detail table that has the full precision for those queries that need it, and one or more smaller (and faster) aggregate tables for queries that only need directional information and not the full detail.
Another useful option is approximation, using sketches. These provide very fast set operations, such as “how many users who visited page A also visited page B”? The answers are approximate, but will always be within 2% of a precise count, and will run much faster. Again, you can easily set up multiple tables using the same sources if you’ll need both very accurate (if slower) queries and also very fast approximate queries.
Data Sources
What data are you using for the project? How will the data get to Druid?
Druid has two different ingestion types for two very different types of data: stream and batch.
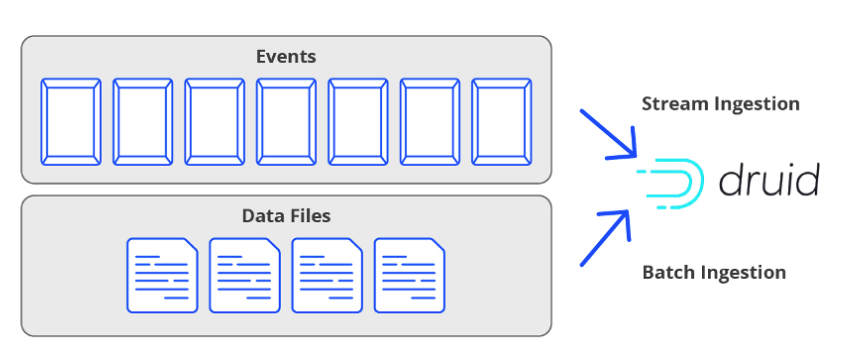
Stream data is a flow of events, delivered by a stream processor, such as Apache Kafka®, a Kafka-compatible service, or Amazon Kinesis. Once you configure an ingestion spec for a stream and submit it as a task, data will flow into a Druid table forever (or until the ingestion task is paused or terminated).
Do you have applications creating events you want to analyze? Use a stream (or multiple streams) to deliver these events to Druid. See Ingesting Stream Data.
Batch data is stored in files. Unlike stream ingestion, which is a continuous indefinite task, batch ingestion is once-and-done, with the task completed when all files in the batch are ingested. Of course, it’s common to automate a batch ingestion when files arrive for ingestion. See Ingesting Batch Data.
Tables in Druid can be used as a source of batch ingestion. This is useful to experiment with different data schemas, aggregation, and approximations. It’s also useful to combine
A common source of data is other databases, which can use either stream or batch tools to copy data into Druid. Many databases now include tools to expose changes as a stream, while open source tools such as Debezium has connectors for many common databases (including MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, Db2, and Cassandra) that deliver data changes as a Kafka topic, which can then use stream ingestion into Druid.
Another option is to periodically export data from a source database into a file The data file can be created using database tools like PosgtgreSQL pgdump, Oracle Data Unload, or MongoDB mongoexport, or it can be done using common ELT tools including Informatica, Fivetran, and Matillion. Then the file can be used with batch ingestion into Druid.
Visualization
Most Druid projects need some way for humans to view and understand data, creating charts, graphs, dashboards and other visualizations. What will you use?
If you’re writing an application, you could use the visualization tools included in Python, JavaScript, or other languages that include visual elements. See Python Visualization Tutorial.
Or you could use an open source visualization package. Apache Superset is a data visualization and exploration platform that was originally created at Airbnb to create dashboards with Druid. The current version includes connectors to work with Druid. Grafana is another open source visualization platform which includes plugins for Druid.
There are also commercial visualization tools available for Druid. Preset offers supported distributions of Superset, while Grafana Labs does the same for Grafana. Imply, a company founded by the original creators of Druid, offers Pivot, a visualization tool specifically created for Druid.
An example of data exploration using Pivot and Druid
Infrastructure
Druid needs hardware – servers and storage.
Druid clusters can be of any size, from running on a laptop to thousands of servers.
Sizing the needed cluster can be challenging, influenced by the rate of data ingestion, the amount of data to be stored, the complexity and frequency of queries, and the use of aggregations and approximations.
Fortunately, Druid clusters are fully elastic. You can add and remove servers from a running cluster without any downtime. So if you don’t get infrastructure calculation right on the first attempt, it’s easy to change, especially if you’re using on-demand resources from a public or private cloud.
For more details on infrastructure design, see Scaling a Druid Cluster lesson.
Documentation
As the author and software engineer Michael Lopp has noted: “The rule is simple: if you don’t write it down, it never happened.”
Most developers and architects dislike (or even hate) documenting their work. If you want successful projects, you must learn to overcome this resistance to creating written guidelines to the intent, design, configuration, and operations of the project.
As noted in the “Purpose” section above, a project should start with a short, clear description of its goals.
As the project is defined, the design should be captured in documentation, showing data flows from source systems, through transformation, to the Druid database, to systems that use the data to create reports, dashboard, other visualizations, and automated actions.
Specific configuration of the software and infrastructure should also be documented. How did you modify the default settings for Druid parameters? For data ingestion, what SQL statements (Ingesting Batch Data lesson) or ingestion specifications (Ingesting Stream Data lesson) are in use? What queries are commonly used? Where are the servers and storage (on premise? In a cloud?) and how are they configured? How is the environment secured (Securing Druid Projects lesson).
Finally, the project needs documentation on operations. When a new team member is tasked with administering the Druid environment, what do they need to know? What should be monitored to ensure reliable operations (Monitoring a Druid Cluster lesson)? What should they do if there is a problem?
Plan the Work, and Work the Plan
Hopefully, this guide has sparked some ideas as to how you should create the plan for your Druid project. Remember that the plan is not the project, and be ready to adjust as needed.
Keep your plan updated, while reviewing the original purpose statement to be sure that your project is still focused on its goals.
Work your plan through design, development, deployment and continuous improvement as you take your ideas from inception to useful projects that use data to fulfill your mission!
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


