Why Use Batch?
Apache Druid is usually associated with scale, speed, and streaming, enabling high-concurrency subsecond queries of data sets of any size with true stream ingestion that make each event in a stream immediately available. Not all data is in a stream, though: sometimes you want to include historical data or batch data from other sources.
It’s easy to ingest batch data into Druid, turning files into full-indexed, high-performance tables using SQL commands. Druid also includes the tools needed to transform data as part of ingestion, using aggregations and joins to create the table needed to best support needed queries. It’s even possible to use batch ingestion from a Druid table to a new druid table, making it easy to experiment with data models to optimize a Druid deployment.
Data Ingestion Checklist
- Data Sources
- Transformation
- Automation
Sources
Batch data usually comes from either files or databases.
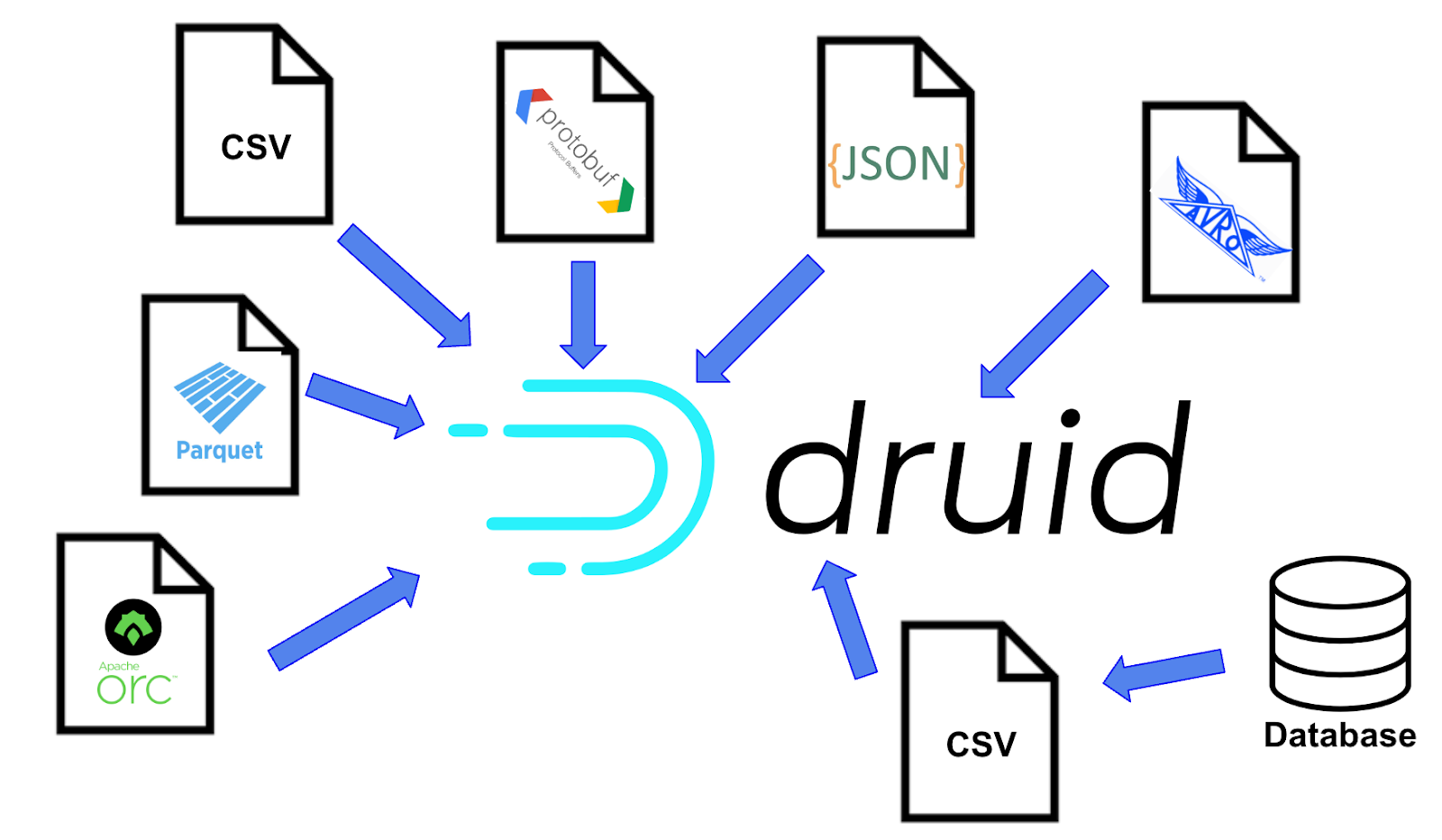
File data can be in a range of standard formats, from simple delimited text (CSV or TSV), to JSON, ORC, Parquet, Avro, and Protobuf, to advanced formats including Iceberg and Delta Lake. Druid can accept both raw and compressed files, using common compression formats like bz2, gz, xz, zip, sz, and zst.
The files can be anywhere that can communicate with the Druid cluster: local storage, HTTP, cloud storage (Amazon S3, Azure Blob, Google GCS, and others), network storage, or elsewhere.
When data exists in another database, a common approach is to create a stream (Ingesting Stream Data lesson) to copy-on-change, so Druid will have the most current data. Sometimes this isn’t possible, so the best approach is to export the data into a file, which can then be used for a Druid batch ingestion. The data file can be created using database tools like PosgtgreSQL pgdump, Oracle Data Unload, or MongoDB mongoexport – or it can be done using common ELT tools including Informatica, Fivetran, and Matillion.
One additional source is another Druid table, which can be used as a batch ingestion source. This is useful when you want to experiment with aggregations or approximations and when you want to join data already in Druid with additional data in files.
Simple ingestion
The easy way to ingest batch data is with Druid’s SQL commands: INSERT with EXTERN.
Unlike many other databases, there is CREATE TABLE in Druid. Ingestion, indexing, and INSERT are three names for the same activity – in Druid, all data is always fully indexed. When you INSERT data into a table that does not yet exist, that table is created.
Imply Data makes some sample data available. There is a file with on-time flight data for a bit over 500,000 flights online at https://static.imply.io/example-data/flight_on_time/flights/On_Time_Reporting_Carrier_On_Time_Performance_(1987_present)_2005_11.csv.zip
To ingest this table into Druid, all that’s needed is a simple SQL command:
INSERT INTO myFlightTable
SELECT * FROM TABLE(
EXTERN( '{"type":"http","uris":["https://static.imply.io/example-data/flight_on_time/flights/On_Time_Reporting_Carrier_On_Time_Performance_(1987_present)_2005_11.csv.zip"]}',
'{"type":"csv","findColumnsFromHeader":true}'
));Since this statement does not explicitly define the data type for each field, Druid will use schema auto-discovery to determine whether each column in the table should be a string, long, double, or some other data type.
Like any SQL statement in Druid, this can be executed using the Druid REST API for Ingestion or by embedding the SQL into any supported language (JavaScript, Python, Java, and many others).
As an alternative to SQL, ingestion can also use the Druid Native ingestion spec, which can be created using the Druid Web Console.
Transformation
Druid works best with large flat tables (Data Modeling lesson). While Druid has strong support for joins as a part of query, whenever possible the path to simpler queries and higher performance is simple: perform any needed joins once, during ingestion, instead of repeatedly during each query.
Joins in Druid use standard SQL, and can be part of the INSERT statement:
INSERT INTO myFlightTableWithCancelCodes
WITH flights AS (
SELECT * FROM TABLE(
EXTERN '{"type":"http","uris":["https://static.imply.io/example-data/flight_on_time/flights/On_Time_Reporting_Carrier_On_Time_Performance_(1987_present)_2005_11.csv.zip"]}',
'{"type":"csv","findColumnsFromHeader":true}'
)),
cancelcodes AS (
SELECT * FROM TABLE(
EXTERN(
'{"type":"http","uris":["https://static.imply.io/example-data/flight_on_time/dimensions/L_CANCELLATION.csv"]}',
'{"type":"csv","findColumnsFromHeader":true}'
)))
SELECT
depaturetime,
arrivalime,
Reporting_Airline,
OriginAirportID,
DestAirportID,
Cancelled,
CancellationCodeLookup.Description AS CancellationReason
FROM “flights”
JOIN cancelcodes AS CancellationCodeLookup ON CancellationCode = CancellationCodeLookup.Code;Other common transformations include rollups, using functions such as COUNT, SUM, and GROUP BY to aggregate data into fewer rows for faster queries. Rollups and data sketches to get fast, accurate approximations for large sets that are expensive to compute precisely, like distinct counts and quantiles (Data Sketches).
Automation
Sometimes ingestion is once-and-done, but it’s common to have batch data delivered regularly, such as hourly, daily, or weekly.
The easiest way to automate is to embed the ingestion SQL statement into a code module of your preferred language, then use a workflow tool to launch ingestion when new data arrives. A common choice is Apache Airflow, which includes Airflow Providers specific for Druid.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


