Why Use Streams?
Events are the core of real-time analytics. The value of each event declines over time, so getting insight fast is critical. Streams are the standard technology for moving events between systems with speed and scale.
Data streaming is high-speed high-scale messaging. While messaging has been in use since the 1960s, modern streaming emerged from projects at LinkedIn (Kafka) and Amazon (Kinesis) in the early 2010s. It’s common today to find streams with millions of events per second, simplifying and scaling moving event data.
Druid includes true stream ingestion. No “connector” software is needed. Any data stream compatible with Apache Kafka or Amazon Kinesis can ingest directly into Druid with each event immediately available for query.
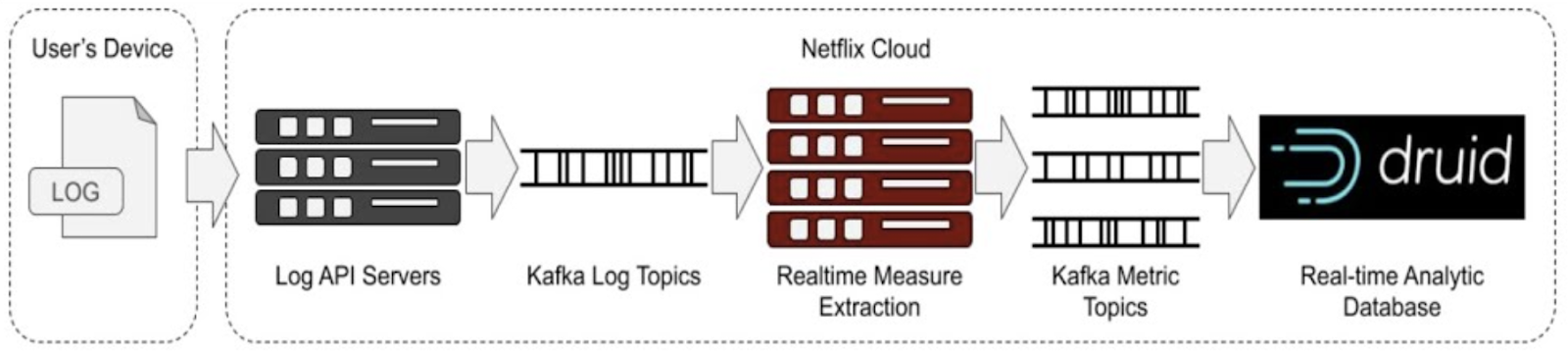
Netflix Metrics pipeline, using Kafka streams and Druid. Source: YouTube
Data Ingestion Checklist
- Data Sources
- Schema Definition
- Ingestion Spec
- Monitoring
Sources
Apache Kafka organizes groups of messages as topics, a common name for a group of messages. Applications that place events into a topic are producers, while those that read events from a topic are consumers. By configuring an ingestion spec, Druid becomes a consumer for a topic, and every event placed into the topic immediately becomes part of a Druid table.
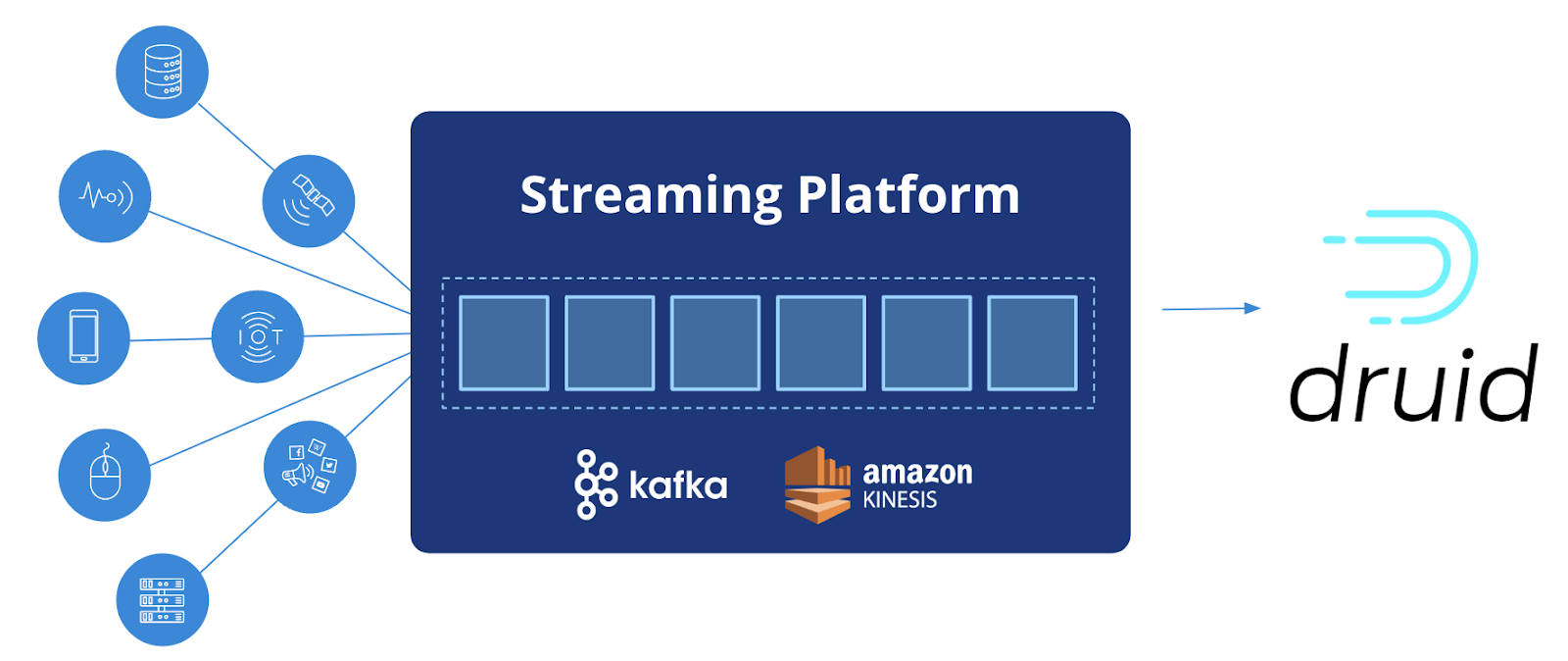
The topics can be open source Apache Kafka or any of the providers offering hosted Kafka, including Confluent Platform, Confluent Cloud, Amazon Managed Services for Kafka, Azure HDInsight Kafka, Aiven for Apache Kafka, and others.
Other streaming systems that are API-compatible with Kafka will also work with Druid, which treats their topics as if they were Kafka topics. Redpanda, StreamNative Kafka-on-Pulsar, Azure Event Hubs for Apache Kafka, are some of the options available.
Defining a Schema
Data in a stream will usually by in JSON format, such as:
{"title":"The Matrix","year":1999,"cast":["Keanu Reeves","Laurence Fishburne","Carrie-Anne Moss","Hugo Weaving","Joe Pantoliano"],"genres":["Science Fiction"]}This message has four key-value sets, each of which is suitable for a column in Druid.
One option is to define an explicit schema, with each column and its data type defined as part of the ingestion spec.
title (STRING)
year (LONG)
cast (ARRAY)
genres (ARRAY)
An easier option (especially for more complex topics that might have hundreds of key-value sets) is to let Druid use schema auto-detection, automatically examining each field and creating a column of the appropriate data type.
Druid can store complex nested data in a column. If the data in the stream is nested JSON, such as:
{
"time":"2022-6-14T10:32:08Z",
"product":"Keyboard",
"department":"Computers",
"shipTo":{
"firstName": "Sandra",
"lastName": "Beatty",
"address": {
"street": "293 Grant Well",
"city": "Loischester",
"state": "FL",
"country": "TV",
"postalCode": "88845-0066"
},
"phoneNumbers": [
{"type":"primary","number":"1-788-771-7028 x8627" },
{"type":"secondary","number":"1-460-496-4884 x887"}
]
},
"details"{"color":"plum","price":"40.00"}
}The nested data in the “shipTo” and “details” columns will be stored using Druid’s COMPLEX<json> data type. Data stored this way is faster to query than flattened data.
Creating an Ingestion Spec
Actually ingesting data from a stream is driven by creating a supervisor specification for Kafka or Kinesis stream ingestion, commonly called an ingestion spec.
Each ingestion spec will consume the data from a single Kafka topic or Kinesis stream. It’s a JSON object that defines how the stream data should appear in a Druid table. Once submitted to the Druid Overload process, every event in that stream will be ingested into Druid and all future events will be immediately ingested, too.
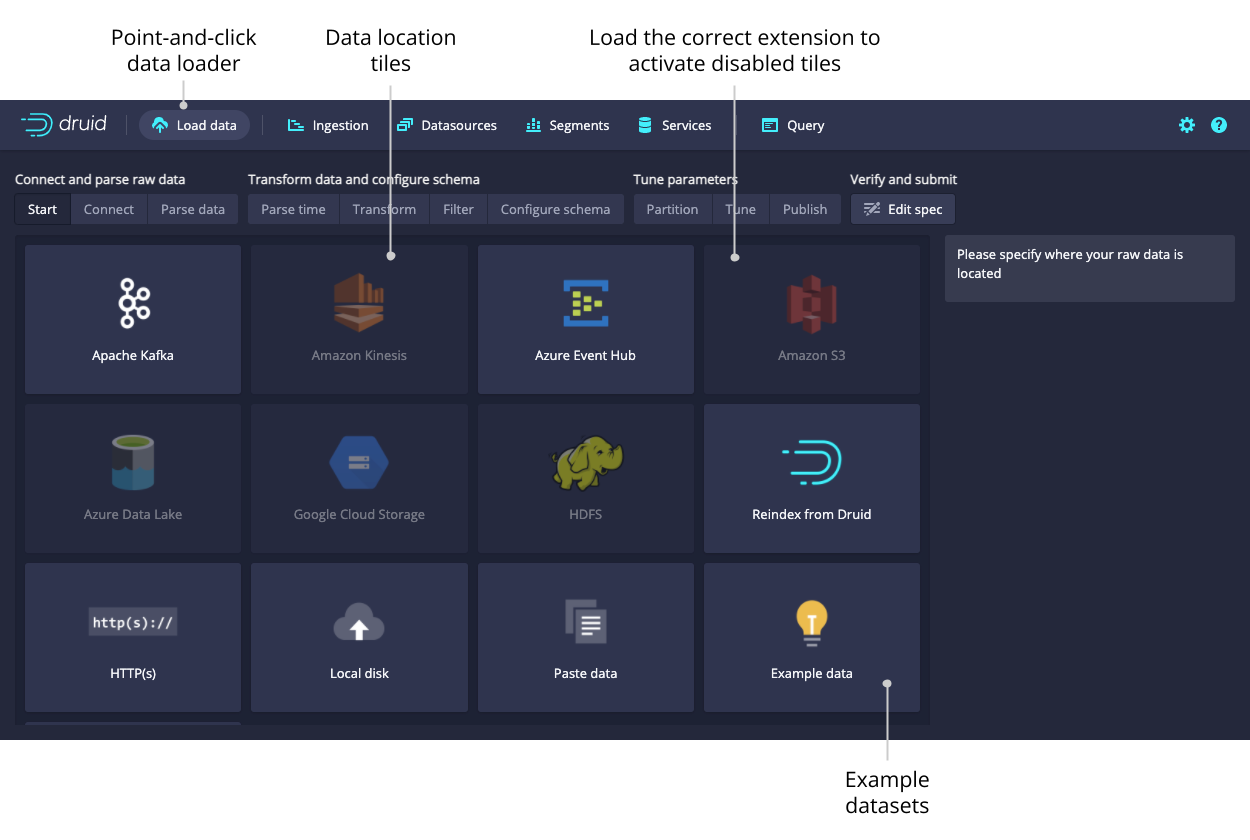
The easiest way to create and submit an ingestion spec is to use the Druid Web Console. The Load Data Section provides step-by-step guidance to select a datasource, define the schema (or use auto-detection), choose parameters, and submit the spec to make it active.
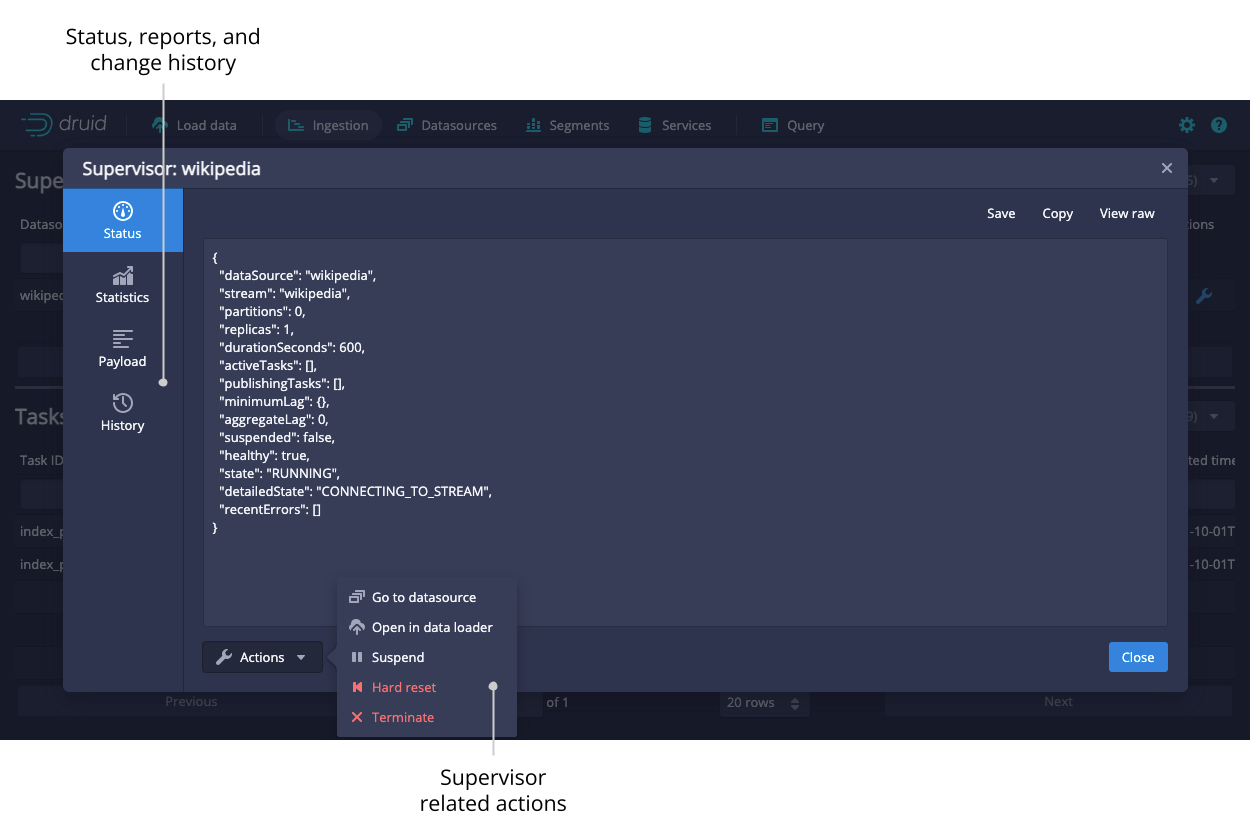
Monitoring
Once submitted, the ingestion spec will continue to ingest data from its associated stream forever, until it is suspended or terminated.
Again, the easiest way to monitor ongoing ingestion tasks is in the Druid Web Console. The Supervisors and Tasks view shows each running Druid task, its current status, and allows each ingestion to be paused, resumed, or terminated.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


