During ingestion time, Druid partitions data into files called segments, which are generally partitioned by timestamp. Even though the primary partition is on time, we can further partition it based on other dimensions, such as range or hash values.
Afterwards, these segments are distributed among all data nodes for querying ahead of time, where they are memory mapped to provide an efficient way for the query processing engine to access data during query execution.
What is memory mapping?
Modern computers have a virtual memory that is not physically present, and instead is set up through a hard disk (virtual memory). Therefore, any program inside the computer will have a virtual memory address to store data—which cannot be used unless converted to a physical address.
In short, memory mapping is the process done by the Operating System (OS) to translate virtual memory addresses to physical addresses. As a result, the program can run as long as the OS loads it as required.
How does memory mapping work?
Memory mapping in the host operating system maps the bytes of a file to a continuous virtual memory range, making the file appear as if it were just another chunk of memory. When read, data is paged into physical memory in a cache that resides in the free space. It stays there, allowing re-use if it is read again.
In case all of the space is occupied, it is automatically removed for other segments to be read or to free up space for other processes.
How does memory mapping affect performance?
The results are particularly noticeable when there are repeated reads of the same data. Parts of the files are retained in the page cache, and memory read speeds are typically higher than disk read speeds. The historical process could have as much free memory space as allocated for the segment cache, meaning all segments it serves could be stored in the page cache.
However, for all practical purposes, this isn’t usually feasible, so the ratio of free space to disk cache is typically chosen to accommodate the use case and desired performance characteristics of the cluster.
What is data compression?
Data compression reduces the number of bits needed to represent data. Compressing data can save storage capacity, speed up file transfer, and decrease storage hardware and network bandwidth costs. Data compression techniques use algorithms to determine how to shrink the data size. For instance, an algorithm may represent a string of bits—or 0s and 1s—with a smaller string of 0s and 1s using a dictionary to convert between them. The formula may also insert a reference or pointer to a string of 0s and 1s the program has already seen.
Data compression can be either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information.
What is dictionary encoding?
Dictionary encoding is a data compression technique that can be applied to individual columns. It will store each unique value of a column in memory and associate each record with its corresponding unique value. This eliminates the storage of duplicate values in a column, reducing the overall memory and disk space required to hold the data.
Dictionary encoding is most effective on columns with low cardinality. The fewer the number of unique values within a column, the more significant reduction in memory usage. Queries against the encoded column will generally be faster.
Let’s say we have a table of people’s favorite colors.
| Name | Color |
| Abhishek | red |
| Pankaj | blue |
| Anil | red |
| Pramod | red |
| Senthil | blue |
| Jyoti | green |
The color column has many repeated values and can represent a dictionary vector. First, we make a flat base vector containing only distinct colors: [red, blue, green]. Then, we map each color to an index into the base vector: 0 for red, 1 for blue, and 2 for green. Using this mapping, we convert the original values into an array of indices: [0, 1, 0, 0, 1, 2]. Finally, we combine the indices and a base vector to make a dictionary vector.

Now, let’s say we want to represent a subset of the people whose favorite color is red. We can take the original flat vector of names and wrap it in a dictionary vector with indices pointing only to rows where color = red, e.g., rows 0, 2, and 3.
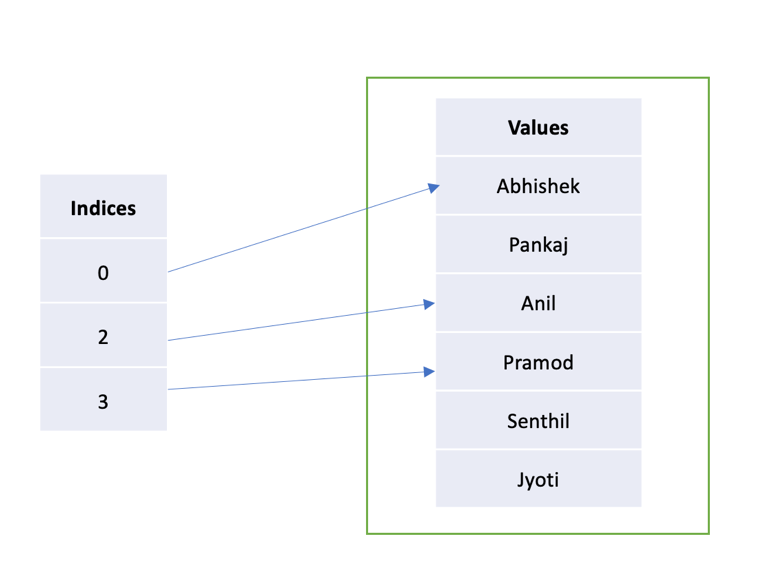
As we can see, dictionary vectors represent cardinality increase and reduction.
Dictionary encoding with strings in Druid
Since string value sizes vary from row to row, dictionary encoding is employed, where each distinct value is placed into a sorted dictionary and assigned an integer identifier representing its position in the sorted set of values. The actual column part we store in the segment then consists of a series of integers that map to the values in the dictionary rather than the values themselves.
Besides the integer dictionary id column and the value dictionary as described above, in Druid, there is a third part that consists of bitmap value indexes ordered identically to the value dictionary, where the set bits of the bitmap corresponds to which rows of the integer column contain that dictionary identifier. Druid stores things like this for a few reasons.
- First, dictionary encoding makes random access to individual rows an efficient computation. Integers are a fixed width, so we can compute the offset in the integer column for a specific row in code simply by multiplying the number of bytes per value by the row number.
- Second, since the integer column parts are stored in fixed-size compressed blocks and use a byte packing strategy to use the smallest number of bytes representing all values, we can also compute which block a particular row belongs to in order to decompress it and then seek out the desired row.
What is delta encoding?
Delta encoding refers to techniques that store data as the difference between successive samples (or characters) rather than directly storing the samples themselves. The image below shows an example of how this is done. The first value in the delta-encoded file is the same as the first value in the original data. All the following values in the encoded file are equal to the difference (delta) between the corresponding value in the input file and the previous value in the input file.
Delta encoding can be used for data compression when there is typically only a slight change between adjacent values.

What is front coding?
Front coding is a type of delta encoding compression algorithm, whereby common prefixes (or suffixes) and their lengths are recorded so that they need not be duplicated. This algorithm is particularly suitable for compressing sorted data, e.g., a list of words from a dictionary.
| Input | Common prefix | Compressed output |
| myxa | no preceding word | 0 myxa |
| myxophyta | ‘myx’ | 3 ophyta |
| myxopod | ‘myxop’ | 5 od |
| nab | no common prefix | 0 nab |
| nabbed | ‘nab’ | 3 bed |
| nabbing | ‘nabb’ | 4 ing |
| nabit | ‘nab’ | 3 it |
| nabk | ‘nab’ | 3 k |
| nabob | ‘nab’ | 3 ob |
| nacarat | ‘na’ | 2 carat |
| nacelle | ‘nac’ | 3 elle |
| 64 bytes | 46 bytes | |
Front coding in Druid
We can enable front coding on both existing data sources as well as new data sources. It works for string columns as well as for MVDs and arrays. We can add the configuration with compaction with existing data source(s).
However, please note that this will trigger the compaction job for all segments (including the ones that have already been compacted). The bucketSize value is always 2ˆx. Based on my experience so far, we have seen 20% to 25% of storage reduction between bucketSize of 16 and 32.
To enable front coding, we need to add the stringDictionaryEncoding under tuningConfig. See below:
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
},
"indexSpec": {
"stringDictionaryEncoding": {
"type": "frontCoded",
"bucketSize": 4,
"formatVersion": 1
}
}
}Front coding is a fantastic functionality and can be super helpful in reducing storage if we have the right data set. A good example could be a data source with columns containing URLs. Since the majority of URL data will have something like http://abc.com/index.asp where strings like http://, .com, and index.asp might be redundant across the entire data source, this would be a very good candidate for utilizing this feature.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


