
Analyze millions of events per second in your application
With Kafka, you can get millions of events in a flash. But how can you interactively analyze all those events as they happen with hundreds or thousands of concurrent users? Typical databases can’t handle the high concurrency and volume of real-time events, even the ones that promise “unlimited scalability.”
Developers from Netflix, Twitter, Confluent, Salesforce, and many others choose Druid as their real-time analytics database, often pairing it with Confluent/Kafka in what we call the K2D Stack: Kafka to Druid.
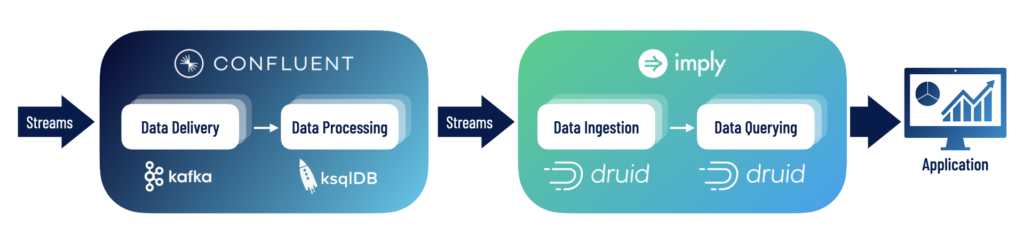
With Imply Polaris, you can have Druid up and running in minutes, with built-in Confluent Cloud and a slice-and-dice visualizer – perfect for a quick proof-of-concept.
Druid is unique in the streaming analytics world
Developers love Druid because it natively connects to Kafka and can handle millions of events per second.
In addition to high speed, high volume streaming capability, Druid ingests and queries batch data as well and offers a query engine optimized for long-running queries. Getting both streaming and batch in one place, simplifying your application architecture.
Key Challenges
Query events the moment they hit the cluster – no waiting for the events to persist to storage
True event-by-event ingestion – not batch ingestion masquerading as streaming
Exactly-once semantics (no duplicates) – without workarounds or writing special queries
“We built an observability platform powered by Kafka and Druid. This solution ingests over 3.5 million events per second and handles hundreds of queries on top of that. And this gives us real-time insights into the operations of thousands of these Kafka clusters within Confluent Cloud”

Read More about Apache Kafka
and Apache Druid



Solution Brief
K2D (Kafka to Druid) Stack for Real-Time Analytics Applications
Read the Solution Brief →
Case Study:
Confluent Health+
Confluent Health+ provides Confluent Cloud customers with the visibility needed to ensure the health of their data-in-motion infrastructure and to minimize business disruption. Health+ offers intelligent alerts, cloud-based monitoring and visualizations, and a streamlined support experience.
“Leveraging Druid as part of our stack means we don’t shy away from high-cardinality data which means we can find the needle in the haystack. As a result, our teams can detect problems before they emerge and quickly troubleshoot issues to improve the overall customer experience.
The flexibility we have with Druid also means we can expose the same data we use internally also to our customers, giving them detailed insights into how their own applications are behaving.”
Xavier Leaute and Zohreh Karimi, Lead Engineers at Confluent
Learn more about Apache Druid
An Introduction to Apache Druid
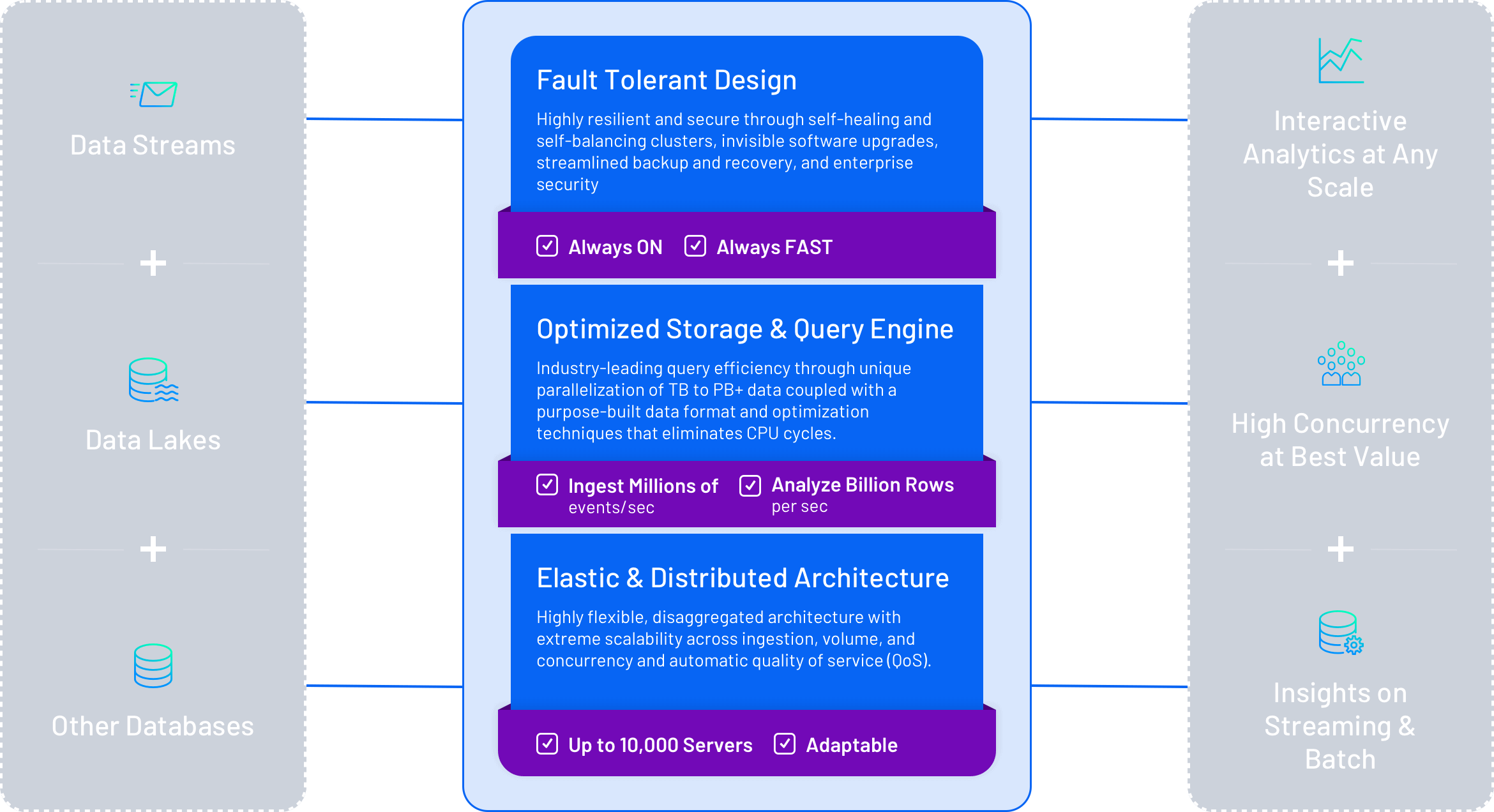
Druid’s flexible, efficient, and resilient design make it the best choice for modern analytics applications. Here’s a quick but technical overview of what makes Druid different.
An Introduction to Analytics Applications
The world of analytics is shifting from traditional BI solutions designed by data engineers to custom applications created by developers. Learn what this is all about and what it takes to build a successful analytics application.
A new architecture for
analytics applications
Try Apache Druid for yourself. Get started in minutes with Imply Polaris. No credit card required
More ways to support your Druid journey


Druid University
Grow your knowledge with Druid videos and accreditation courses.
Join the University →

Druid Meetups
Engage with other Druid believers. Share knowledge. Expand your network.
Attend a Meetup →

Druid Stories
Help others learn from your experiences with Druid by sharing your Druid story.
Tell Your Druid Story →
Grow your knowledge and developer power with Apache Druid Basics Accreditation
The Imply Accreditation Program for Apache Druid Basics begins by demonstrating how to set up a local environment, followed by instruction on architecture, the importance of processes and how they interact with each other. Delegates then learn how to ingest data into Druid and finally how to query it.
This expert-led training is completely free, and you’ll earn a certificate that you can display on your LinkedIn profile after passing the exam!