Apache Druid
The real-time analytics database designed to power analytics applications at any scale, for any number of users, and across streaming and batch data.
- Capabilities
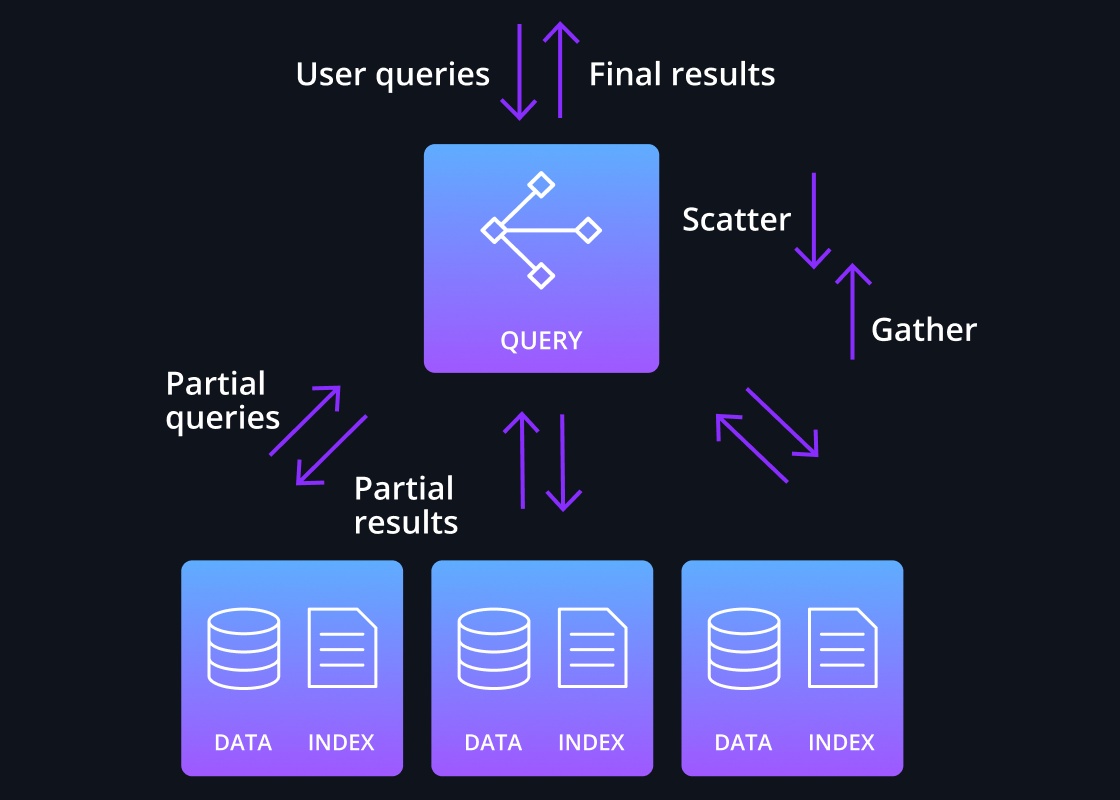
Scatter/gather processing
Druid’s core query engine features a highly efficient design to execute queries across large data sets. Queries are divided and fanned out – ie “scattered” – to relevant data nodes; partial results are merged by a broker node – ie “gathered”.
This design is highly efficient as only a portion of the data set is read and data is not sent across process boundaries or among the data nodes.
This single-stage process works for the smallest single node cluster to clusters with thousands of nodes with each data node processing billions of rows, enabling sub-second performance for most queries even with data sets of multiple petabytes.
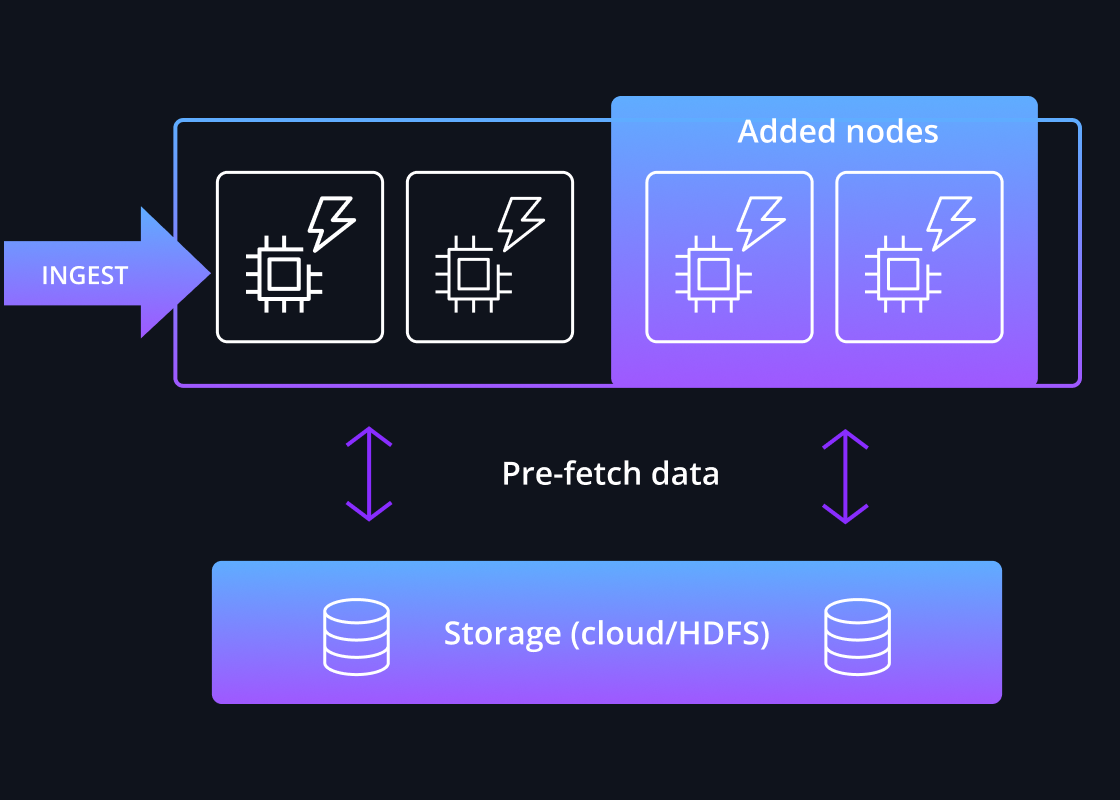
Intelligent Pre-Caching
For performance-sensitive workloads, data is pre-loaded into local caches before queries are issued, which guarantees high performance as data does not need to be read from deep storage over the network during a query.
Druid utilizes a high degree of intelligence to quickly identify which segments are relevant to the query and where they are located across a cluster of continuously rebalanced nodes. Queries are then fanned out across those relevant nodes and gathered so the final result can be sent to the application.
Optimized Data Format
Druid’s storage format was built in tandem with the query engine to maximize performance through processing efficiency. It stores ingested tables into optimized segments – with each segment comprising up to a few million rows of data.
The data in Druid segments are columnarized, time indexed, dictionary encoded, bitmap indexed, and type-aware compressed – all automatically. Queries only load the specific columns needed for each query and reads the optimized index, which further improves the performance of scans and aggregations.

“If you want super fast, low latency, less than a second, this is when we recommend Druid.”