Modernizing Rubicon Project’s Analytics Stack for Programmatic Advertising
Oct 22, 2018
Ken Lin
This is a guest post from Ken Lin, Senior Director of Product Management, and Johnny Shen, Director of Engineering, from Rubicon Project.
Rubicon Project is one of the world’s largest digital advertising exchanges and helps premium websites and mobile apps sell ads easily and safely In addition, the world’s leading agencies and brands rely on Rubicon Project’s technology to execute tens of billions of advertising transactions daily.
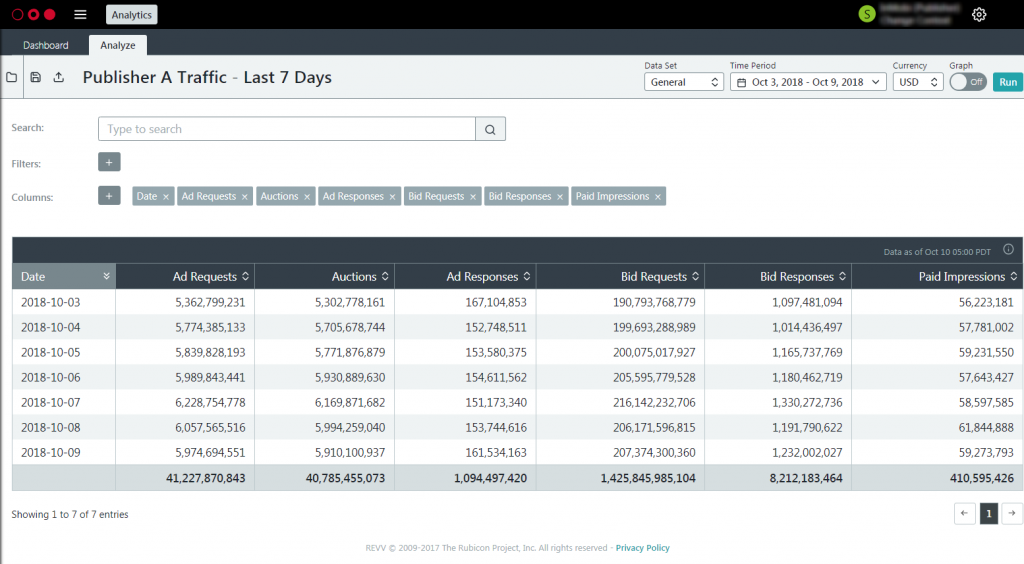
A core product offered by Rubicon Project is its Performance Analytics solution Performance Analytics is Rubicon Project’s flagship reporting platform and is used by thousands of external customers, publishers, and DSPs across the globe Every day, marketers, decision makers, buyers, sellers, and account managers log in to analyze and visualize their respective performance metrics, which range from ad requests, bid requests, auction rates, fill rates, CPMs, and much more.
Rubicon Project processes trillions of ad and bid requests quarterly with over 1,000 header bidding connections and 40% growth in mobile ad spend in Q2 2018 compared to Q2 2017, 70% growth in video ad spend in the first half of 2018 compared to the first half of 2017, and 300% growth of audio ad spend in Q2 2018 As Rubicon’s traffic has grown, it faced a big challenge on how to continue to scale its analytics stack to provide interactive analytics to the wide base of users.
Rubicon Project’s previous reporting platform was MySQL, which worked well when the data volume was 10% of what is received today. To power the Performance Analytics platform, Rubicon Project chose Druid as part its underlying data store and partnered with Imply to create a world-class solution for the industry.
In 2016, as Rubicon Project was looking to modernize its analytics stack with three main goals in mind: accuracy, performance, and timeliness.
Accuracy is the foundation of a reporting application Publishers and DSPs make vital business decisions and campaign adjustments based on data from Performance Analytics, which requires precise data calculation and aggregation to match finance billing data Rubicon Project’s modern analytics solution has to ensure strict accuracy of results.
Performance: Performance Analytics does not just generate static reports for users, it also allows users flexibly to explore trends and patterns in data Users can self service explanations of anomalies in reports To provide users with this experience, Rubicon Project requires queries to be returned near instantly, even when aggregating billions of message entries This allows Rubicon Project to provide users with an interactive data exploration experience through its UI.
Timeliness: Publishers, buyers, and DSP adjust their inventory, bid, and spend quickly to react to the fast pace of programmatic advertising Much of their in-moment decisions are based on past campaign results The faster data is loaded and disseminated, the faster Rubicon Project’s customers can make decisions This iterative decision making cycle pushes the digital programmatic advertising industry towards more transparency and efficient spend and purchase Hence, short SLAs on data ingestion and queries is critical for Performance Analytics.
To achieve the above goals, Rubicon Project faced several tough Engineering problems:
Huge data volumes. With strong business growth in past years, Rubicon Project’s traffic volumes have doubled within the last 12 months This added great pressure on Performance Analytics to aggregate and store trillions of raw messages.
Cost Control. Pouring money on infrastructure to resolve scaling and performance issues is a short-term solution to deal with growing business needs. Long term, controlling cost and operating within budget is critical for company success Rubicon Project required a very efficient software solution to scaling problems.
Monitoring and Alerting. Incidents are an inevitable part of dev/ops and Rubicon Projected needed monitoring tools and alerting processes to proactively identify problems and resolve issues before they become a major fire This is extremely important as Rubicon Project is in a phase of fast growth.
Rubicon Project evaluated many different technologies in the data space and chose Apache Druid (incubating) as its next generation analytics solution There are three great reasons for choosing Druid in addition to the requirements above:
Storage saving. Druid can rollup or pre-aggregate data once ingested Most of Rubicon Project’s raw level events are generated at a millisecond level but many of queries require results at a minutely, hourly, or daily level Druid provides capabilities out-of-the-box to summarize and pre-aggregate data as it is ingested In practice, Rubicon Project’s raw data is reduced 10-100x when stored in Druid.
Ad-hoc analytics. Druid excels at ad-hoc slice-and-dice queries that are critical to powering an interactive UI for Rubicon Project’s customers Reports in Performance Analytics are not static and are fully interactive and allow customers to arbitrarily drill into data to better understand trends and patterns.
Real-time and batch ingest. Druid supports both real-time and static ingest efficiently Rubicon Project can stream in live data into Druid so customers can quickly make decisions on their advertising spend, and at the same time allow the company to make bulk updates and corrections of data through Druid’s batch loading interface Druid seamlessly blends real-time and batch loads together.
Rubicon Project has partnered closely with Imply and leverages Imply’s suite of tools power Rubicon Project’s Performance Analytics solution. Today, Rubicon Project’s production Druid cluster scales horizontally, loading more than 2 TB of data per hour and over a trillion events events per day, and is used by thousands of users across the globe with an average response of <500ms.
For high performance analytics solution to large operational data, Rubicon Project encourages checking out druid.io and imply.io.
Rubicon Project is an independent, publicly-traded company (NYSE:RUBI) with fifteen offices worldwide and is headquartered in Los Angeles, California.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...