How much, and what sort of infrastructure is needed for an Apache Druid® project? A Druid cluster can be of any size, from running on a laptop to thousands of servers.
Sizing the needed cluster includes many variables, including the rate of data ingestion, the amount of data to be stored, the complexity and frequency of queries, and the use of aggregations and approximations.
By design, Druid clusters are fully elastic. You can add and remove servers from a running cluster without any downtime. So if you don’t get infrastructure calculation right on the first attempt, it’s easy to change, especially if you’re using on-demand resources from a public or private cloud.
There are also techniques that can be useful to maximize performance without needing to add additional infrastructure.
Performance and Scaling Checklist
- Initial Cluster
- Infrastructure Provider
- Adding and Removing Capacity
- Landscape Design
- Performance Tuning
Initial Cluster
Druid runs as a collection of tasks, each run by processes that are hosted on servers running Linux. There also three external dependencies that must be supported.
Each Druid process is actually a Java process, executing on a Java runtime (the recommended version is OpenJDK 17, but many variants are supported). One or more copies of each process are needed in each cluster. For a small cluster or a development cluster, all processes (and dependencies) can be run on a single machine, which simply requires 6 GiB of memory.
There are 6 processes that are needed for any Druid cluster:
Overlord manages data ingestion (and creates Peon processes to execute ingestion)
Coordinator manages how Historicals store data segments
Broker manages queries (when you query Druid, you communicate with a Broker process)
Router provides the Druid web console for management and can also route queries to specific brokers if you want to create different tiers of data
Historical stores data in segments (files) and execute queries
MiddleManager sends ingestions tasks to Peon processes
There is also a new Indexer process that can be used to replace both MiddleManagers and Peons.
For scalable deployment, a common convention is to create 3 types of nodes, each running a pair of processes:
Master Nodes are servers running Overlord and Coordinator processes. They have modest needs – a good starting configuration is 2 moderately-powerful CPUs and 8GiB memory. No need for storage other than boot requirements.
Query Nodes are servers running Broker and Router processes. Queries can require fast processing, so a good starting configuration is 2 high-powered CPUs and 4GiB memory. Again, no need for storage other than boot requirements.
Data Nodes are servers running Historical, MiddleManager, and Peon processes (or, alternately, Historial and Indexer processes). These nodes don’t need a lot of computing power, but do need memory and high-speed storage. A good starting configuration is 2 moderately-powerful CPUs, 16GiB memory, and 400GB high-speed local storage (such as NVMe SSD drives).
While the processes can run directly on Java runtimes on Linux, it’s common to deploy using containers managed by Kubernetes, which can reduce the work of managing the processes. This choice doesn’t impact the number or size of servers needed.
The cluster will also need to support 3 external dependencies:
Apache Zookeeper® provides service discovery and coordination among the Druid processes. The system requirements for Zookeeper are very small, so instead of providing separate infrastructure, its common to run it alongside the Overlord and Coordinator processes on the Druid Master Nodes. If you need high availability (for production or test), Zookeeper requires a cluster of 3 or 5 servers.
Metadata about tasks and storage is stored in a relational database, usually PostgreSQL or MySQL. Even a very large Druid cluster has a small amount of metadata, so only a small database server (1 CPU, 2GiB memory, 10GB storage) is sufficient.
Deep Storage is a reliable and durable copy of each data segment, used for cluster rebalancing, avoiding data loss from server failure, and even directly responding to queries (slower than queries from data nodes, but reducing the costs of the cluster by reducing the number of needed data nodes). This is usually a dedicated storage service, using HDFS or object storage semantics.
Putting all this together, a typical initial cluster that supports high availability will include:
3 Master Nodes (also running Zookeepeer)
2 Query Nodes
2 Data Nodes
2 Metadata servers (a primary and a replica)
Deep Storage
Using the guidelines above, this will support up to 400GB of stored data (about 1TB or more of raw data), with stream ingestion, and subsecond high-concurrency queries.
Infrastructure Provider
Most Druid clusters use public clouds. Any Cloud provider offering object storage and Linux servers can be used. The most common choices are Amazon Web Services, Microsoft Azure, or Google Cloud Platform.
Following the recommendation for an initial cluster above, specific infrastructure configurations can include:
Druid on Amazon Web Services
For Deep Storage, use S3.
For Master Nodes, use EC2 m5.large or m6i.large or m6a.large
For Query Nodes, use EC2 c5.large or c6i.large or c6a.large
For Data Nodes, use EC2 i3.large
For Metadata, use Amazon RDS PostgreSQL or MySQL db.t3.micro or db.t4g.micro (with Multi-AZ is high availability is needed)
If Kubernetes is desired, use EKS.
Druid on Microsoft Azure
For Deep Storage, use Azure Blob (with ZRS or GRS replication if high availability is needed).
For Master Nodes, use B2s or B2as virtual machines
For Query Nodes, use B2ls or B2als virtual machines
For Data Nodes, use D16a virtual machines
For Metadata, use Azure Database for PostgreSQL or Azure Database for MySQL with a B1ms instance (with zone-redundant option if high availability is needed)
If Kubernetes is desired, use AKS.
Druid on Google Cloud Platform
For Deep Storage, use Cloud Storage.
For Master Nodes, use Compute Engine n2-standard-2 or n2d-standard-2
For Query Nodes, use Compute Engine c2d-highcpu-2
For Data Nodes, use Compute Engine c2d-highmem-2 with 2 Local SSD
For Metadata, use Cloud SQL with PostgreSQL or MySQL with 1 CPU (add HA Configuration option if high availability is needed).
If Kubernetes is desired, use GKE.
Druid on other clouds or on-premise
For Deep Storage, use any storage that is S3-compatible or HDFS compatible
For Master Nodes, use virtual machines with 2 CPU and 8GiB memory
For Query Nodes, use virtual machines with 2 high-speed CPU and 4GiB memory
For Data Nodes, use virtual machines with 2 CPU, 16GiB memory, and at least 400GB local SSD storage
For Metadata, use PostgreSQL, MySQL either directly or through a managed service, with a high-availability cluster if needed.
If Kubernetes is desired, use the provider’s managed Kubernetes offering or open source Kubernetes.
Adding and Removing Capacity
To add or remove a node, just run the start command for the node type you want to add or remove. These commands will be found in the directory where an Apache Druid version was downloaded; it can be any Linux installation that has network connections to the nodes that are being managed.
For master nodes:
bin/start-cluster-master-no-zk-server (if NOT running Zookeeper on the master nodes)
bin/start-cluster-master-with-zk-server (if running Zookeeper on the master nodes)
For query nodes:
bin/start-cluster-query-server
For data nodes:
bin/start-cluster-data-server
Each command will launch an interactive session where you can specify which nodes you want in the cluster. Druid will continue to run while adding or removing the nodes, while automatically rebalancing as a background process. Any capacity on new nodes becomes immediately available.
To view the logs for these operations, look at the tail of:
var/sv/coordinator-overlord.log
var/sv/broker.log
var/sv/historical.log
It’s usually a good idea to use the same machine types (same number of processors, amount of memory, network connections, and storage sizes) for each node of each category. Sometimes it might make sense to have different tiers of data nodes (see performance tuning, below), in which case each tier should have nodes that are all the same machine types.
… but the machine types don’t have to match. To change the machine type in use, add nodes of the new machine type, wait for rebalancing to complete (by looking at the logs), then remove the nodes of the old machine type. Druid will keep working through all of these changes without downtime.
Landscape Design
A Landscape is the collection of production and non-production clusters that comprise a project. At a minimum, a project will require a development environment and a production environment. In this example, Local Development is a single laptop (Wow, That Was Easy), while Production is a scalable cluster as described above.
A minimal landscape
When a project has multiple developers, it’s a good idea to provide developers with both Local Development systems and a scalable Central Development cluster where they can work collaboratively. It’s also a good idea to add a scalable Test cluster to enable both unit testing for continuous integration / continuous testing and occasional performance testing, where the Test cluster is temporarily increased in size to validate capabilities for expected future workloads.

A simple landscape
As projects grow larger, it often becomes useful to add additional clusters to the landscape, dividing the testing load between a Feature Test cluster and a Performance Test cluster and adding an additional cluster for Staging, to help manage deployment of new features
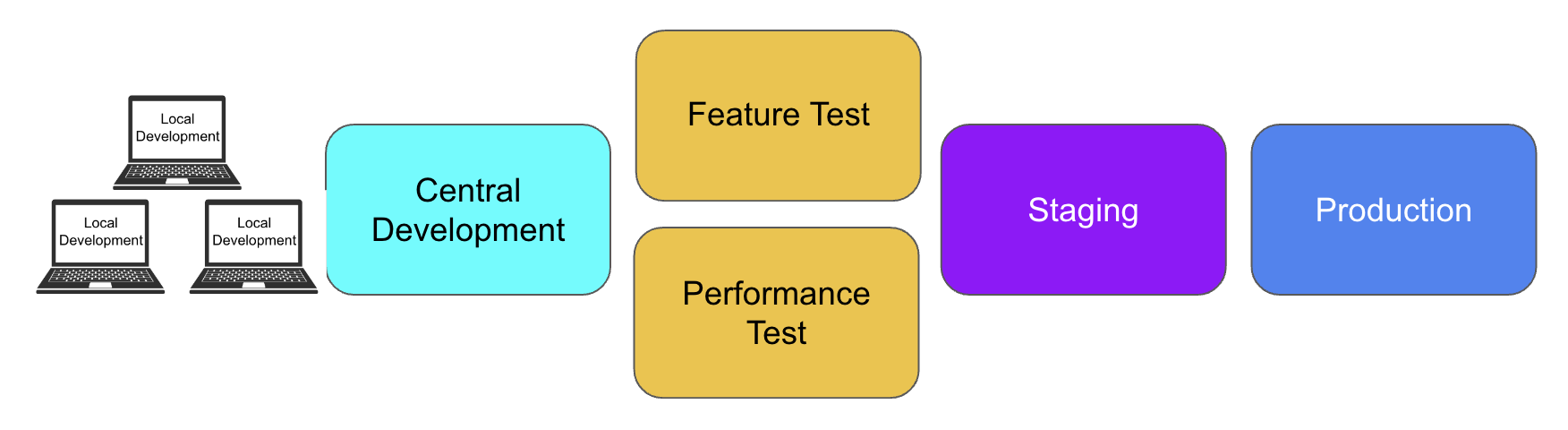
A more complex landscape
Since Druid is inherently high-availability, there’s no need for an additional Production cluster to provide reliability. See Providing High Availability and Disaster Recovery in Apache Druid for details.
Performance Tuning
Along with adding and removing infrastructure, there are several tools in Druid to optimize configurations for performance, depending upon workload requirements. These are detailed in the Druid documentation.
For larger and more complex workloads, two powerful tool for performance tuning are Query Laning and Service Tiering.
Query Laning uses multiple Druid Broker processes, each managing a “lane” of incoming queries, allowing separation of smaller quick-running and larger, slower-running queries into separate Brokers (similar to a highway with ‘local’ and ‘express’ lanes). There are several laning strategies supported by Druid to define which queries go to which lanes.
Service Tiering creates groups of Druid Historicals processes + Druid Broker processes to enable different resource sets for different sets of data and queries. A common simple use is to create a “hot” tier for recent data, and a “cold” tier for older, less-frequently-required data. This is when the Druid Router process becomes necessary, routing each incoming query to the correct service tier.
Using Service Tiering “breaks” the rule-of-thumb that all Data Nodes in a cluster should be of the same machine types. Instead, while using Service Tiering, all Data Nodes in the same tier should be of the same machine types, but the specific types for each tier may be different. A “hot” tier may need Data Nodes with high performance processors and fast local storage, while a “cold” tier may need processing capacity and less local storage (or, if using Druid Query-from-Deep-Storage, no local storage at all!).
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


