I have worked with relational databases throughout my career as a developer and sales engineer creating transactional and analytical applications and Proof of Concepts (POCs). For the past seven years, I have worked with NoSQL databases. Recently, I was tasked with developing some how-to solutions using the Apache Druid real-time, analytics database. I decided to document the experience to serve as a reference for others interested in learning about Druid. In this blog I will cover:
- Installing Druid locally
- Importing documents via SQL ingestion
- Executing SQL queries
Druid Installation
Druid can be deployed locally, via docker, in the Cloud within the customer’s VPC, a hybrid of both on prem and in the cloud or via Imply which offers fully managed DBaaS, hybrid and self-managed options. I will be providing a step-by-step guide to installing Druid locally.
Before we begin the installation, we need to ensure that the following prerequisites are met:
Prerequisites
The requirements for the installation are:
- A workstation or server with at least 16 GiB of RAM
- Linux, Mac OS X, or other Unix-like OS. (Windows is not supported)
- Java 8u92+ or Java 11
- Python2 or Python3
Set Home Environment Variable
The Druid installation requires that JAVA_HOME or DRUID_ JAVA _HOME be set.
On a mac the JAVA_HOME can be set by following these steps:
- Open up Terminal:
vi ~/.bash_profile- Add these lines below to file to set the path to your .jdk and save then exit the file:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home- Execute the command below to make the change permanent:
source ~/.bash_profile- Verify the path was correctly added by executing:
echo $JAVA_HOMEDruid Setup
- Download the 25.0.0 release from Apache Druid and extract the file.
- From the terminal change directories to the distribution directory for example:
cd apache-druid-25.0.0- From the apache-druid-25.0.0 package root, run the following command to start the micro-quickstart configuration:
./bin/start-micro-quickstart- This starts up instances of ZooKeeper and the Druid services
- After the Druid services finish startup, open the web UI at http://localhost:8888
Note: To stop Druid at any time, use CTRL+C in the terminal. This exits the bin/start-druid script and terminates all Druid processes.
Druid Console
The Apache Druid console is an easy-to-use, web-based interface for exploring and managing data in Apache Druid. It provides a graphical user interface (GUI) to interact with Druid clusters and explore the underlying data. The console provides the ability to import, query and visualize datasets, manage cluster resources, monitor performance metrics etc.
Importing Data via Druid SQL Ingestion
Druid SQL Ingestion supports executing SQL queries on the data source and ingesting the results into Druid. Enabling users to rapidly ingest large amounts of data from a variety of sources, including relational databases, streaming sources, and flat files. The process is highly configurable and can be customized for different types of data, such as csv, parquet JSON or Avro. This process is familiar to SQL users and doesn’t require learning a proprietary data access and query language.
Let’s import some data using SQL ingestion within the Druid UI.
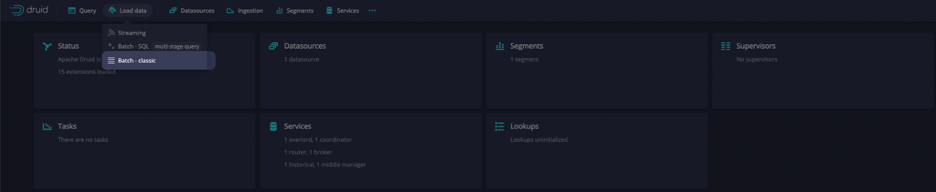
In the UI select Load data Batch – classic as shown in the screen capture below:
Select Start a new batch spec as shown in the screen capture below:

Select http(s) as shown in the screen capture below:
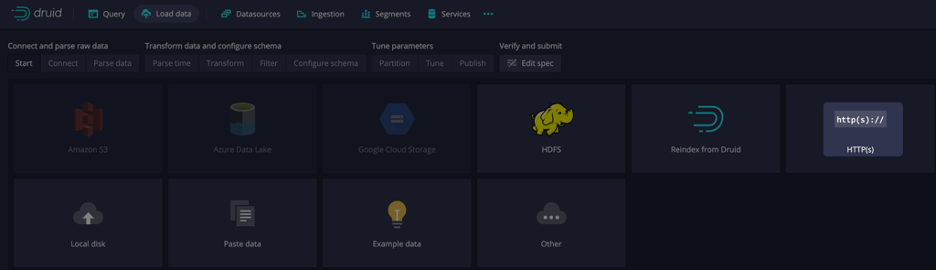
Now let’s generate a query that references externally hosted data using the Connect external data wizard. The following example uses EXTERN to query a JSON file located at https://druid.apache.org/data/wikipedia.json.gz.
Note: Although you can manually create a query in the UI, you can use Druid to generate a base query for you that you can modify to meet your requirements.
To generate a query from external data, do the following:
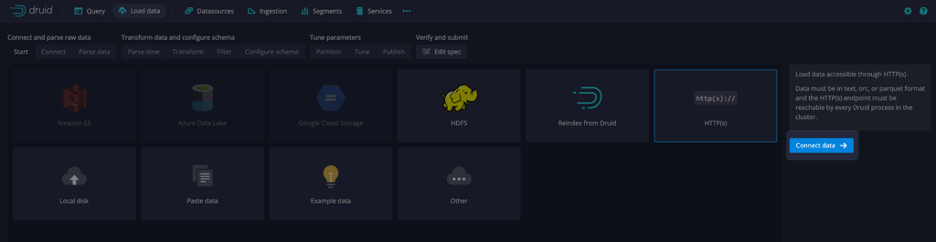
In the Query view of the web console, click Connect data as shown in the screen capture below:
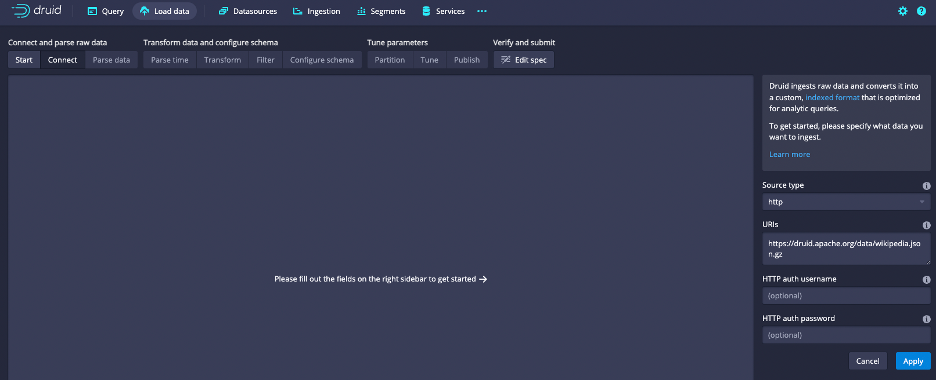
On the Select input type screen, choose HTTP(s) and enter the following value in the URIs field: https://druid.apache.org/data/wikipedia.json.gz. Leave the HTTP auth username and password blank.
The sample dataset is also located in the quickstart/tutorial/ folder, accessible from the Druid root directory, and represents Wikipedia page edits for a given day.
Click Connect data
Select Next: Parse data, you can perform additional actions before you load the data into Druid:
Expand a row to see what data it corresponds to from the source.
Customize how Druid handles the data by selecting the Input format and its related options, such as adding JSON parser features for JSON files.
Select Next: Parse time
o Here you can define the time column for the data
Select Next: Transform
o Here you can perform per row transforms for the incoming data
Select Next: Filter
o Here you can specify row filters to remove unwanted data
Select Next: Configure schema
o Here you can assign data types to each column
Select Next: Partition
o Here you can set the primary portioning by time
o Select hour for segment granularity
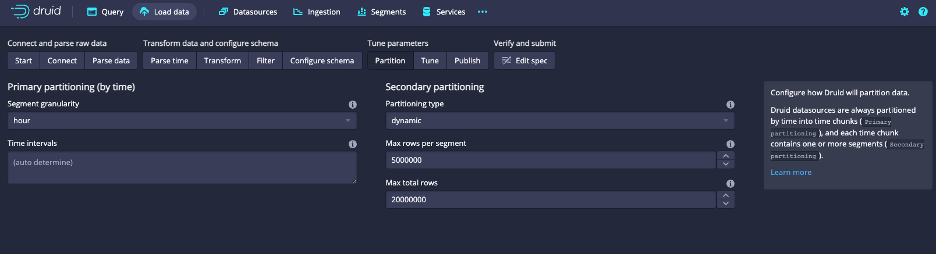
Select Next: Tune
o Here you can set tuning parameters for the import
Select Next: Edit spec
o Here you can edit the JSON import specification that the wizard created
Select Next: Submit
o Here you can set the primary portioning by time
Executing SQL queries
Druid’s architecture allows it to efficiently handle large volumes of queries from many concurrent users, making it ideal for real-time analytics. Through the use of indexing, caching, and advanced data retrieval techniques, Druid streamlines the process of data retrieval and enhances query performance.
Select Query tab
Let’s take a look at some records in the wikipedia table, by executing the query below:
SELECT * FROM "wikipedia"
LIMIT 1ONow let’s group by the channel and get the count for each channel in descending order, using the query below:
SELECT
channel,
COUNT(*)
FROM "wikipedia"
GROUP BY channel
ORDER BY COUNT(*) DESCLet’s assume that management wants to see how many of these entries are from a robot, using the query below:
SELECT
COUNT(isRobot)
FROM "wikipedia"The result should be: 24,433
And where the entry is not a robot, using the query below:
SELECT
COUNT(isRobot)
FROM "wikipedia"
WHERE (isRobot = false)The result should be: 14,569
So, what percentage of the wikipedia updates in this dataset were by a robot? 62.65%. That’s something that an analyst may be interested in.
Summary
Druid is the world’s most advanced real-time analytics database. Druid delivers near real-time access to millions of historical and real-time data points, allowing you to make informed decisions quickly and confidently. It supports batch ingestion of historical data but is intentionally architected for streaming ingestion of data in real-time, making it ideal for applications where immediate access to up-to-date data is required. Thanks to its ability to handle trillions of events and maintain low latency even during high concurrency, it facilitates sub-second performance at scale.
In this blog we learned about:
- Installing Druid locally
- Importing documents via SQL ingestion
- Executing SQL queries
Join me in my next blog which will show how to integrate Druid with other trending technologies.
About the Author
Rick Jacobs is a Senior Technical Product Marketing Manager at Imply. His varied background includes experience at IBM, Cloudera, and Couchbase. He has over 20 years of technology experience garnered from serving in development, consulting, data science, sales engineering, and other roles. He holds several academic degrees including an MS in Computational Science from George Mason University. When not working on technology, Rick is trying to learn Spanish and pursuing his dream of becoming a beach bum.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


