Back in 1993, Dr E.F. Codd coined OLAP, the then-new processing paradigm for decision support systems. That spawned the world of data warehouses as we know it: read-optimized, scalable systems designed to provide analytical insights for large data sets.
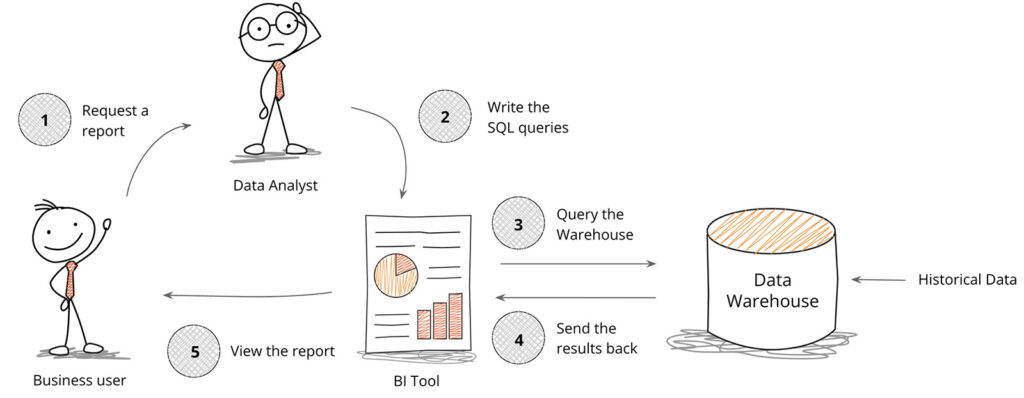
Over the last 20 years, the data warehouse market has evolved a few times. It went columnar with Vertica. Then it got cloudy with Snowflake. And now, it’s morphing into lakehouses. But across all those tech evolutions the core use case and workflow hasn’t really changed. It still looks something like this:
It starts with a business user looking to better understand metrics. That person contacts a data analyst who then spends a few days working with the business user to iron out the SQL queries. Then, the analyst uses their BI tool to run the SQL queries against the data warehouse and then emails the report when it’s done.
This is the classic BI and data warehouse workflow that supports every company and it will continue to be important. But there are a couple things to point out:
There’s a meaningful amount of latency introduced by the data warehouse when the data set being analyzed is large – ie. greater than 1TB or a few million rows. This is generally acceptable for a report as query time is less of a concern with all of the handoffs from steps 1-5 and the queries don’t change too often.
There’s a users-performance-cost relationship reminiscent of the ideal gas law (as temperature increases, pressure increases). Applied here, an increase in users and queries increases response time unless high expense is spent to scale the warehouse. This is also not an issue in classic BI as the number of users in step 1 initiating data requests is few and the use of the BI tool usually doesn’t strain warehouse performance.
Data warehouses are built for historical, batch-ingested data, often refreshed the night before to not impact query performance during work hours. This is acceptable when the insights are based on long historical windows, but not when insights on operational, real-time data are needed too.
While these may seem like limitations in data warehouses, they’re kinda not at the same time. Basic computing principles tell us to design purpose-built architectures – and data warehouses are purpose-built for the classic BI workflow. That said, each of these 3 points are very important for analyticsapplications.
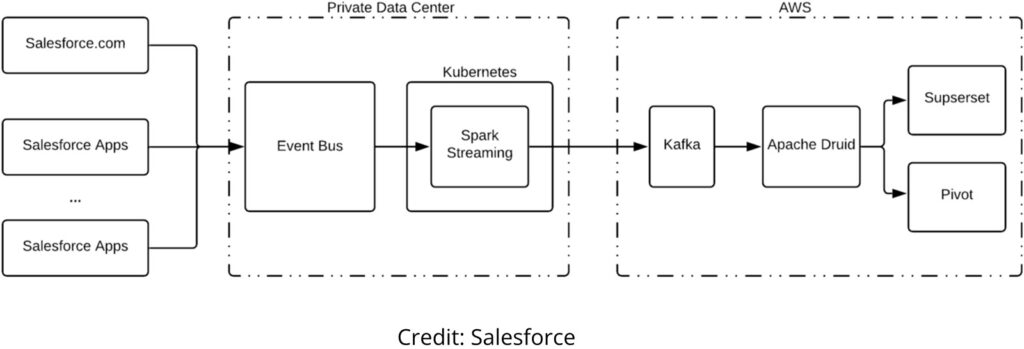
An example of this is at Salesforce. Their engineering team built an observability application that lets teams of engineers, product owners, customer service representatives, and others to interactively query real-time application performance metrics ingested at a rate of billions to trillions of Kafka log lines a day.
Do they need performance at scale? Yea. Are their teams given unrestricted ability to query raw data without latency? Yup. Are they analyzing streaming events as they are created at tremendous scale? For sure.
The reality is that 1000s of companies – originally digital natives but increasingly all organizations – have realized a whole new generation of analytics beyond classic BI. Their developers are building analytics applications that provide operational visibility at scale, extend analytics to customers, enable slice/dice at high volume, and support real-time, automated ML pipelines.
The database requirements for analytics applications
So if you’re building an analytics application what database should you use? You start thinking about what you already know.
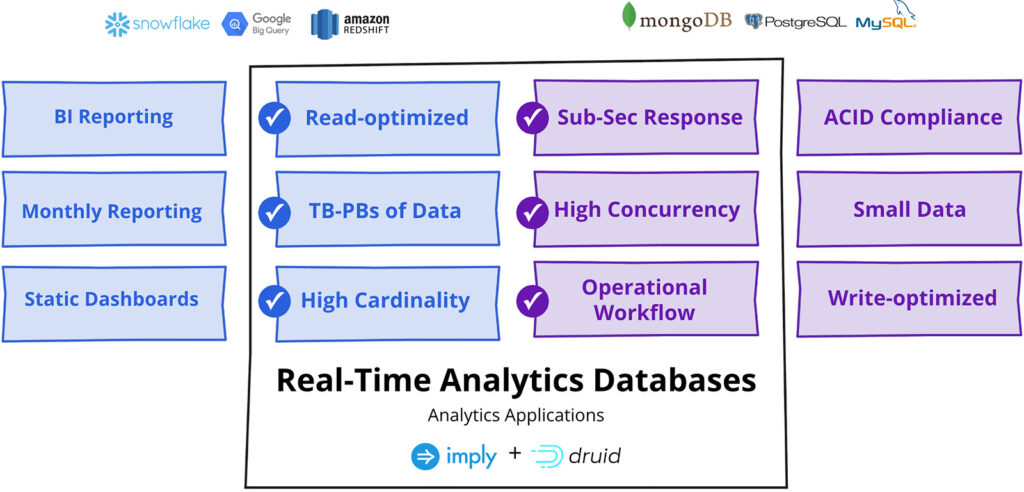
You need analytics capabilities to process terabytes, or maybe petabytes, of data for large aggregation and GROUP BY queries on high dimensional and cardinal data. So you think data warehouses.
But wait, you also need application traits of sub-second response with potentially 100s to 1000s of queries per second as well as high throughput up to millions of real-time data ingested per second. So you think of a transactional database. Wait, but that doesn’t work for the analytics requirements.
This dilemma is the reason why Apache Druid exists.
Druid was built for the intersection of analytics and applications. Not a play at HTAP, which is a fallacy of sorts to say that one database can work everywhere, but rather a real-time analytics database that provides the scale needed for analytics with the speed under load needed for applications.
Druid is built to handle complex queries on large data sets at the fast responsiveness expected for user-facing applications and automated pipelines. For example, Reddit uses Druid to process user data to serve real-time ads in <30 milliseconds.
Druid also uniquely achieves high queries per second without breaking the bank as its CPU efficient architecture keeps the cost down. For example, Twitch engineers happily run 70,000 queries per day on Druid.
And the fact that Druid supports true stream ingestion means that Kafka and Kinesis pipelines have a database built for data in motion. That’s why the engineers at Confluent, the original creators of Apache Kafka®, themselves use Druid to power their observability application with an ingestion rate of 3 million events per second.
New analytics use case, purpose-built open source database
The classic BI workflow isn’t going away. Business users will get insights from data analysts who’ll write SQL queries for BI tools that query a data warehouse. And Snowflake, Redshift, and BigQuery and the whole data warehouse and lakehouse gang will continue fighting over that workload.
But for those who are trying to build analytics applications then there’s a more interesting database to check out.
Apache Druid isn’t your traditional OLAP database because the developers at 1000s of companies using it – like Netflix, Confluent, and Target – aren’t doing conventional things with their data. They’re doing things that are pretty game-changing. They’re building analytics applications, an emerging use case that sits at the intersection of analytics and applications.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...