A new rhythm in streaming music analytics
In the diverse world of streaming analytics, Apache Druid has played a pivotal role across industries from telemetry to finance and IoT. However, for Druid to step into the spotlight of the entertainment industry and cater to artists posed a new set of challenges.
Apache Druid, known for handling analytics at scale and in real time, proved to be the perfect headliner for the task, offering solutions that compute metrics on the fly and scale effortlessly, all while keeping costs in check.
A spotlight on streaming music services
Today, three audio streaming platforms account for about 70% of the market. By analyzing their data, these services can extract various insights, organizations can extract various insights, including monthly listeners, demographic details, music preferences, and more. In addition, song statistics also provide crucial engagement metrics like listener count, number of saves, and distinct playlist adds via web or mobile.
Imagine the release of a new album from a global music icon. They can instantly access listener stats through their dashboards, getting real-time insights into their audience’s reception.
Chord discord: The challenges
- Speed: We know top artists won’t wait for slow query responses. They expect results from complex queries in milliseconds.
- Scale and accuracy: Managing data at the scale of terabytes or petabytes without losing accuracy is crucial. Top artists lose faith and credibility in the platform if it doesn’t scale and returns inaccurate results. Imagine the chaos if a popular track were inaccurately reported, affecting listener churn rates and playlist placements.
- Cost: As data volumes increase, so do costs. Managing these expenses is always challenging.
The solution requirements
- Uninterrupted service: The system must ensure zero downtime, maintaining continuous service regardless of external challenges.
- Global data accessibility: It is essential to provide data availability across various regions, enabling artists to track their global reach and chart positions, even while on tour.
- Advanced observability: The solution requires a sophisticated approach for debugging performance issues and outages, and for ensuring reliable, consistent service.
- Efficient data aggregation: The ability to aggregate large batches of tracks, potentially tens of thousands, in subsecond timeframes and at scale, is a critical requirement.
- Dynamic cohort analysis: The system should facilitate the study of fans’ behavior based on demographics and other categories, providing actionable insights for targeted marketing and fan engagement.
In essence, the solution must excel in performing data aggregations on the fly, at a massive scale, in a reliable, cost-effective manner.
The orchestra: Technical architecture
A sample data pattern to understand the scale of a modern music streaming architecture looks like this:
- Data Ingestion: The Imply solution handles a daily influx of 50 GB of parquet-formatted data, amounting to over 150 TB in total (at a total data retention of 3 years).
- Query Performance: Imply processes approximately 250 queries per second, for a total of 20 million queries per day with a response time of less than 500 ms per query.
- Elasticity: The system is designed to scale up seamlessly during peak data ingestion periods.
The top playlist: Data management
In most cases, music streaming platforms are looking to expand the user base and also provide more features to artists, which in turn calls for capabilities like high availability, uninterrupted scaling, and reliable, scalable queries (e.g., searching multiple artists simultaneously).
The successful recipe for such an architecture includes:
- A dedicated tier for heavy ingestion loads.
- Appropriate and efficient partitioning and sorting mechanisms to minimize scan times during queries.
- Techniques for handling high cardinality data, such as approximation sketches to reduce memory stress.
- Adherence to data modeling best practices.
- Rigorous load testing with mixed query loads to benchmark tolerance levels.
The Imply Engineering team also contributed by developing a custom extension capable of compressing bitmap data at the time of ingestion.
Artists’ queries
Below are some of the complex queries Imply handles:
- Determining the number of users on the US West Coast who added a new single to their playlists in the last seven days after Coachella.
- Analyzing the listening preferences of 15-19-year-old fans of R&B music and using that to tailor artist recommendations.
- Providing global and North American stats on Streams, Listeners, and Playlist adds over the last day broken down by different geographical locations.
- Active listeners categorized based on the listening patterns to be used for targeted campaigns to appropriate audience.
Imply’s contribution
What sets Imply apart when open source Apache Druid already offers so much? It’s Imply’s services. We offer:
- An observability platform (Clarity): Our in-house monitoring tool provides an internal view of customers’ clusters, acting as a gateway for troubleshooting.
- A visualization layer (Pivot): This built-in tool is intended to create interactive graphics and dashboards.
- Support and professional services: Our world-class, 24/7 support and comprehensive professional services range from solution design and migration to annual maintenance and quick tune-ups. We handle the heavy lifting, allowing customers to focus on being the top streaming music provider.
- Design patterns: We offer proven and effective design patterns for similar use cases.
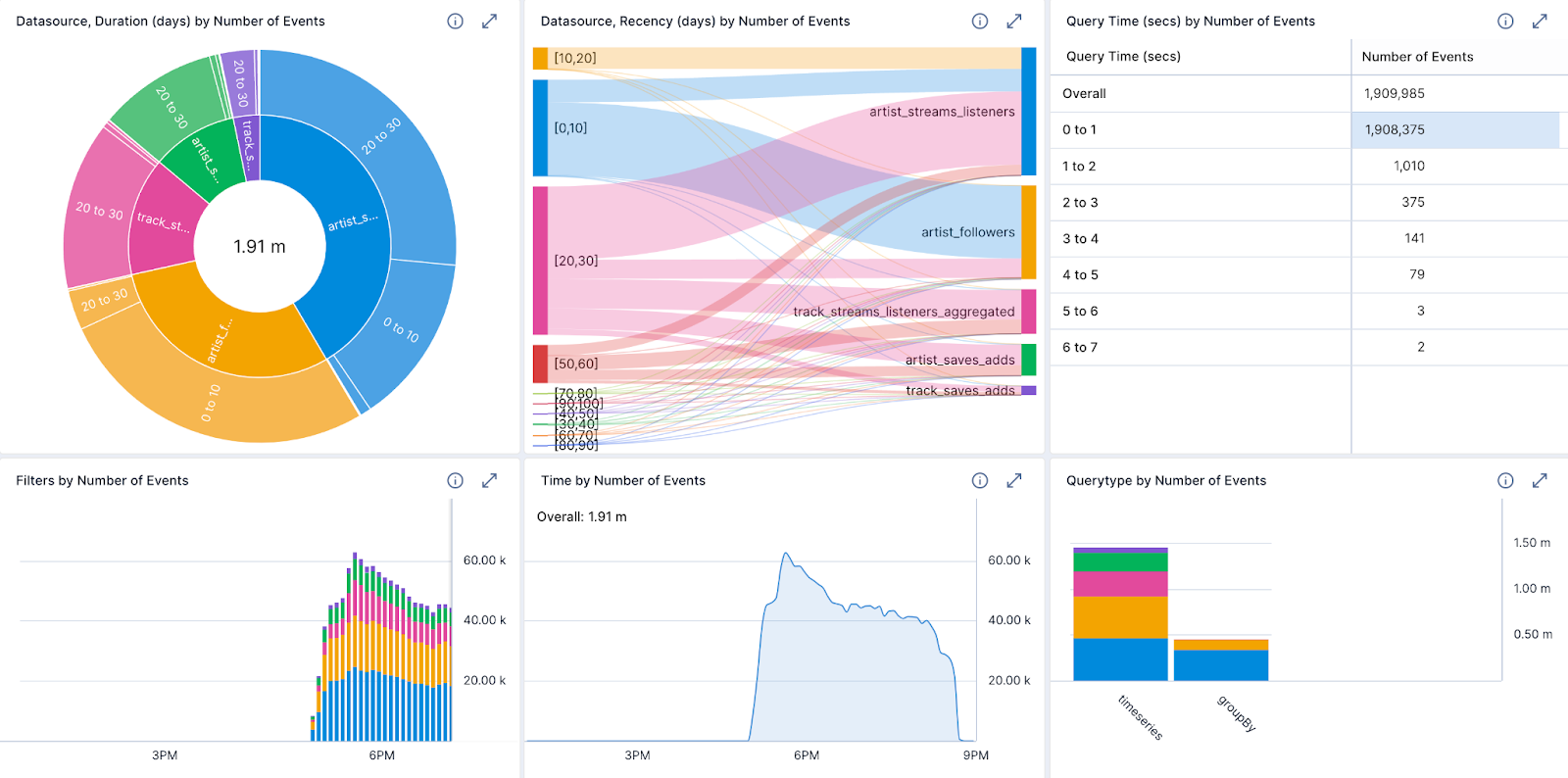
Led by the founders of Druid, our team ensures top-notch service, akin to a perfectly tuned instrument. Below is an example of a dashboard explaining the query usage during a cluster tune-up exercise using Imply Pivot. Based on the analysis and evidence, Imply provides guidance and recommendations to improve performance of the solution.
In the end
Music streaming platforms have not only leveraged Imply’s capabilities but also significantly contributed to the Druid community. In today’s music streaming industry, analytics are an essential tool for both established and emerging artists to target audience groups and launch fan-based campaigns, all powered by Apache Druid and Imply.For those ready to embark on their Druid journey, we offer a comprehensive cookbook to get started. Let’s collaborate to make your next application a chartbuster.