Community Spotlight: Pollfish survey insights, powered by Apache Druid
Oct 14, 2020
Peter Marshall
Pollfish, the “easiest and most affordable way to get real-time insights from real consumers”, delivers democratic, real-time insights with an innovative Apache Druid-powered pipeline that includes microservices leveraging an open-source Scala library for Apache Druid called Scruid. Anastasios Skarlatidis , Director of Data Engineering and Science at Pollfish, tells us more.
The Pollfish advanced data collection platform enables application developers to create mobile app and game surveys, reaching more than half-a-billion real consumers, helping global companies inform advertising, branding, market research, content, and product strategies with fresh and fast data.
“Whether understanding the time it will take to collect answers from their audience of interest, or breaking down results in real-time as respondents answer surveys, Druid delivers the high-performance time-series OLAP database we need to monitor, measure and explore data in real-time.”
Researchers extract and query statistical information on a plethora of dimensions, including income, gender, age distribution, country, state, city and geographical area over multiple time intervals with varying time granularities.
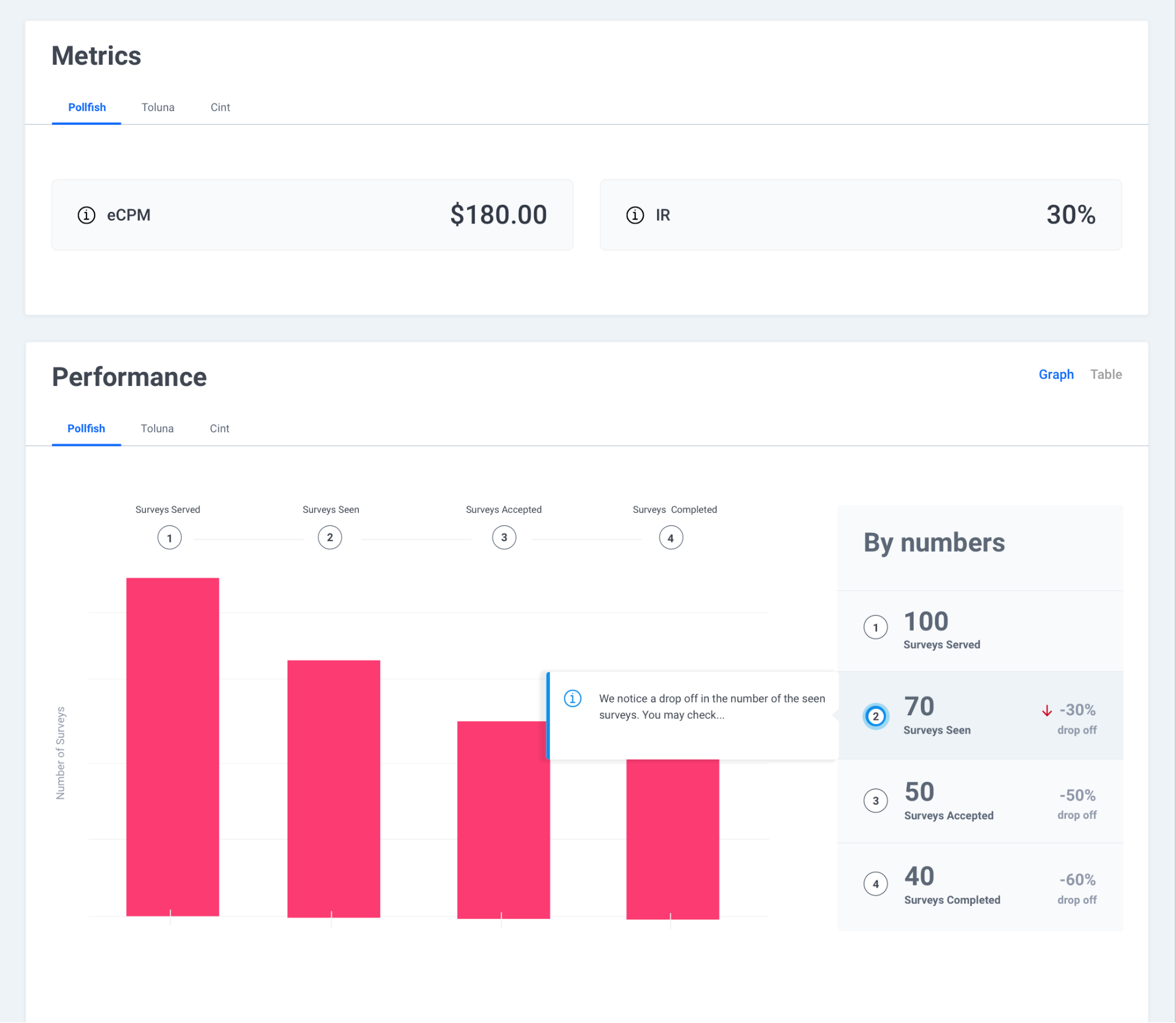
Real-time analytics dashboards show survey performance data: revenue, eCPM, funnel survey participation and more, live and direct from the stream.
The majority of data for analysis in this low-latency pipeline is passed through Apache Kafka, backed by a compute stack composed of Spark, Flink and Akka Streams. Micro-services are implemented mainly in Finatra / Finagle and provide RESTful and Thrift APIs. Cassandra and PostgreSQL live alongside Apache Druid and an HDFS-compatible data lake for raw data which is, for the most part, stored in Parquet and made accessible via Hive.
Enrichment processes (e.g., transformations, enrichments with demographic and geographic data, etc.) publish data to the Apache Kafka® stream, where Apache Druid acts a native sink powering Metabase and Looker for those ad-hoc queries, BI tasks and internal dashboards.
“Apache Druid accelerates and simplifies the process of exploring the data. On the one hand, you have a system that ingests real-time data and on the other hand, the same system, can directly answer any analytical query.”
Pollfish have built an inspirational example of the democratic, real-time data revolution.
Come into the spotlight! Share your Apache Druid story with the whole community, too. Email community@imply.io and we will get the ball rolling!
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake
Lumi Loglake lets Splunk teams query logs directly in object storage — AWS S3, Delta Lake, Apache Iceberg — using standard SPL, with results returned as native Splunk events that work with existing dashboards,...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...