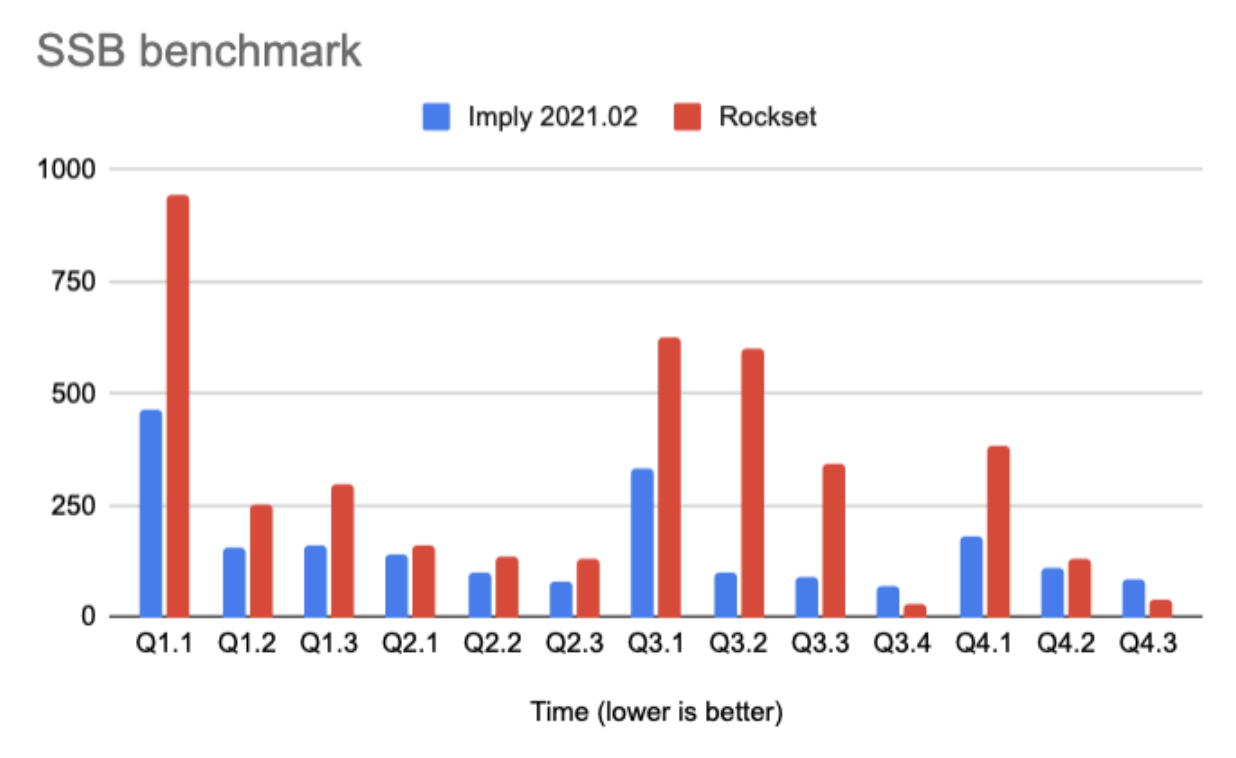
Rockset recently published a blog post that compared the performance of Apache Druid 0.18 versus Rockset using the SSB benchmark. Druid 0.18 is about 9 months out of date at this point, so we wanted to revisit the benchmark based on the latest version of Druid (0.20.1), which includes several performance improvements we’ve been doing over the last few months.
Our findings are below:
Query
Imply3.3.0
Imply 2021.02
Rockset
Q1.1
1245
462
944
Q1.2
155
154
254
Q1.3
92
160
296
Q2.1
662
139
161
Q2.2
591
102
136
Q2.3
319
79
129
Q3.1
292
333
626
Q3.2
514
102
598
Q3.3
417
91
343
Q3.4
100
72
32
Q4.1
883
179
384
Q4.2
389
109
132
Q4.3
384
87
41
6043
2069
4076
We can see a remarkable improvement in performance with the latest version of Druid. Two main things drove most of the change:
1) Many of these queries in the SSB benchmark use expressions. In older versions of Druid, we did not have vectorized expressions implemented, so many of the queries couldn’t vectorize. In the latest version, 100% of these queries vectorize.
2) The schema used to ingest data was changed to match what Rockset is doing. Similar to how Rockset “specified some keys for column-based clustering”, we also used column based clustering (in Druid it’s called partitioning). No further tuning was done in Druid.
In our next release of Druid, we are releasing another set of performance improvements. Stay tuned for more information.
Other blogs you might find interesting
No records found...
Feb 03, 2026
Imply Lumi product update: what’s new and what’s coming
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...
Observability is at a crossroads For years, observability has promised to give teams the visibility they need to keep digital services resilient. But as data volumes explode, many leaders are realizing the...