Anyone who works with databases, whether they’re an administrator, analyst, or engineer, will tell you that queries and data were not made equally. After all, databases must use resources to organize data and process queries—some of which are more urgent than others.
Data itself also varies in value and usage. Some data may be constantly retrieved immediately after its creation but become less useful as time passes, while other data may be infrequently accessed from the beginning.
As a result, databases have to tier their data, prioritizing resources for certain groups of queries or data types. In general, “hot” tiers are intended for very fast, frequent queries on more recent data, such as temperature readings for an oil well over the past hour. This data is vital for functions such as alerting on imminent failures, assessing performance, and managing day-to-day, minute-to-minute performance.
In contrast, “cold” tiers are reserved for older data that is either rarely utilized or limited to long-running queries. While this data has, in a sense, “aged out” and is no longer useful for routine operations, it is still valuable for other use cases, such as business strategy, reporting, or anomaly detection. As an example, algorithms may use historical temperature data from oil well sensors to build a baseline, so that any outliers can be immediately flagged and submitted to maintenance teams for further investigation and intervention.
How does tiering work in Imply?
Before we get into the mechanics of tiering with Imply, it helps to understand the architecture of Apache Druid, the open source, real-time analytics database that Imply products are built on. Data is stored in segments, or columnar files that can hold up to several million rows; in turn, this data is queried by and organized via various nodes, or specialized servers or processes.
Druid divides its key processes across several different types of nodes, but tiering primarily concerns historical nodes, which store data. Other nodes, such as brokers (which route queries) or coordinator nodes (which assign data to and balance loads within historical nodes), are only tangentially involved.
Within each historical node are multiple replica sets, or copies of data segments. This protects against data loss, ensuring that if one node fails, other nodes can simply take over with their copied data. More replica sets also leads to better query performance, as the system can more easily distribute read requests across multiple nodes with the same data.
With Druid and Imply, there are two primary tiering strategies: compute, which organizes historical nodes by frequency (and urgency) of queries, and storage, which categorizes nodes by datasource. The exact number of available tiers will depend upon your deployment, but by default there are three tiers.
The key to this process is that all the nodes in each tier will have the exact same hardware specifications in terms of power, volume, and performance. Therefore, all the historical nodes on a specific storage tier will have the same capacity, while all the historical nodes on a single compute tier will have the same resources (such as CPU). This helps simplify tasks like sharding, data allocation, and operations—ensuring that broker and coordinator nodes can more seamlessly query and move data around nodes within the same tier.
Tiering data by storage
Storage tiering is relatively straightforward, and can be further broken down into two methods.
By time period
Figure 1. Tier A (hot data from the past three months) has faster hardware, and thus more rapid query results, than Tier B (cold data older than three months).
This approach is the simplest. Imply will store data by when it was generated, moving it from one tier to another as time goes on. For this reason, Tier A could have hot data from the last three months, while further tiers (such as B, C, D, and so forth) could have cold data that is older than three months. Under this model, the two tiers have different hardware, as hot data tiers will have more expensive, performant machines for faster results.
As a note, the process of moving data between tiers can be automated. Simply configure your data retention policies by specifying when data will age out of one tier and into another, and your Imply clusters will do the work for you.
By how often data is queried
Figure 2. Tier G (hot data) has more replicasets, thus enabling faster queries than Tier K (cold data). Both tiers have the same hardware.
As mentioned earlier, recent data tends to be queried often, generally for operational purposes, and as it ages, queries become less frequent, less urgent, or both. A fleet management system, for instance, needs highly accurate, fresh data on metrics such as travel time, average delivery time, completion rate, and more.
In this scenario, data can be tiered by the number of replicas. As a general rule, more replica sets equate to a higher concurrency rate and more parallel queries. Therefore, a hot data tier will have more replica sets than a cold data tier—even though both tiers may have similar amounts of resources like CPU.
To return to the example of the fleet management platform, Tier G (which contains hot, frequently accessed data) could have eight replica sets containing data generated over the past six hours to power key functions like route optimization, real-time alerting, or monitoring driver behavior.
In contrast, Tier K (which contains older, cold data) could have two replica sets of data to enable less time-sensitive use cases, which could include predictive maintenance, compliance, or business reporting. Therefore, this tier will support fewer concurrent, rapid queries, and instead sustain slower, long-running queries.
Tiering data by compute
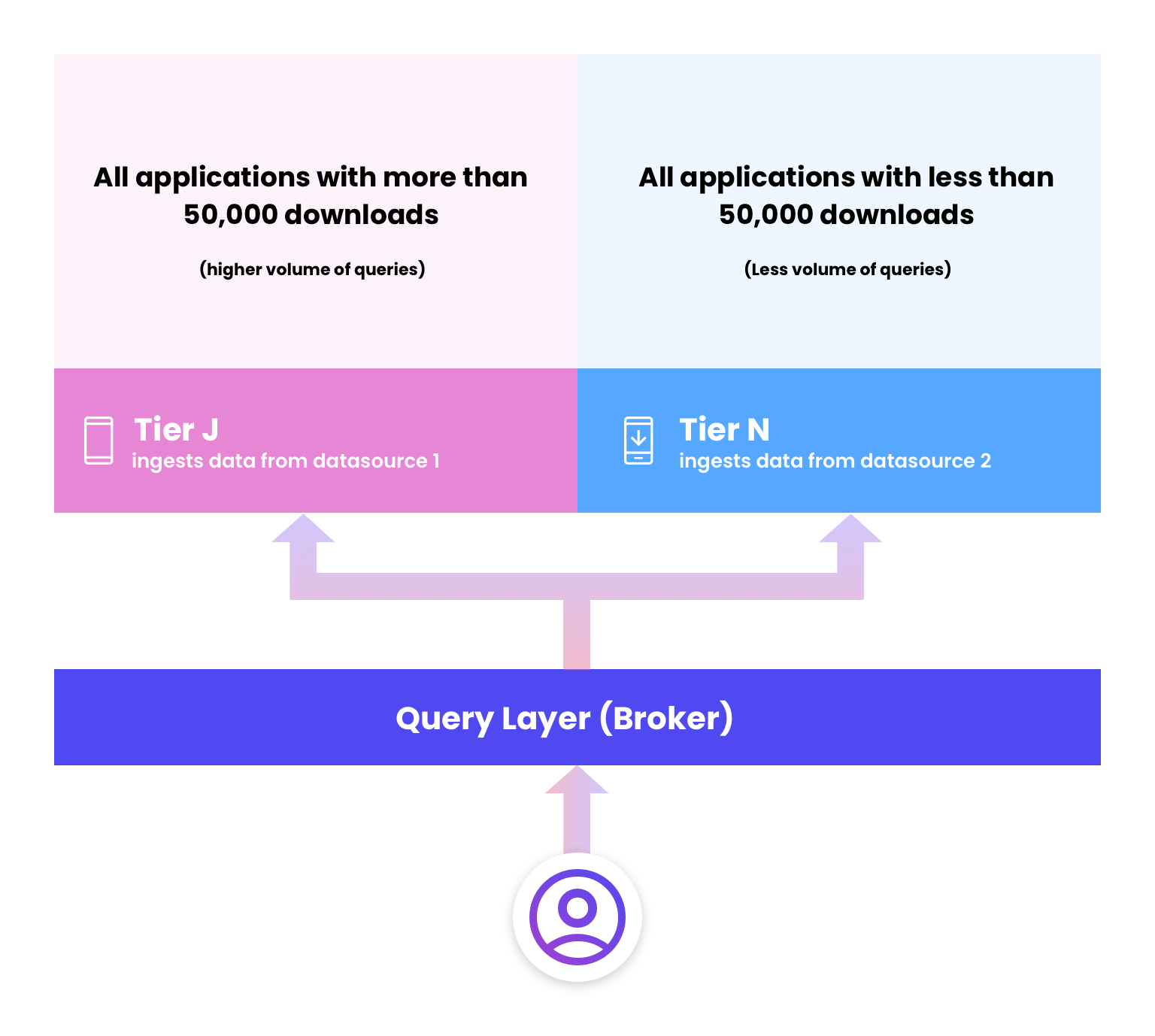
Figure 3. Tier J ingests data from datasource 1, which is far more frequently queried than Tier N, which ingests data from datasource 2.
The other tiering strategy is to separate data by compute, and is used primarily when clusters pull from multiple datasources (also known as multitenancy) and run mixed workloads that may vary in resource usage. In essence, this methodology separates data and resources such as CPU, cache, or RAM into tiers based on operational need.
One example of a real-life Imply customer is a leading marketplace for mobile digital applications. This provider needs to provide data on downloads to its customers, who sell their applications to mobile users on this platform.
However, the challenge is that not all applications are in equal demand—some see millions of downloads, while a larger majority see only a handful. In this situation, it makes sense to tier transaction data by compute in order to support multitenancy, as each application developer is a single tenant, and thus, an individual datasource.
As a result, this provider settled on two tiers. All applications with more than 50,000 downloads would be loaded into Tier J, while any applications with less than 50,000 downloads would reside in Tier N. Because more popular applications are likely created by bigger developers, which means a higher volume of queries, Tier J would also include more processing power and concurrency in order to support more demanding workloads and higher concurrency.
How to choose?
Ultimately, the tiering approach you choose will be based on your needs and your environment. Have plenty of multitenant clusters with mixed workloads? Tier your data by compute.
Need to sort data by when it was generated? Simply tier data by timestamp, and update your data retention policies to automate the process.
Need to organize data by when it was generated and how often it is queried? Add more replica sets to enable fast, concurrent processing.
Get started on tiering with a free trial of Imply Polaris—the easiest way to run Apache Druid. Have any lingering questions about Imply Polaris or data tiering? Set up a demo with an Imply expert today.