Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
We are excited to announce the release of Apache Druid 29.0. This release contains over 350 commits & 67 contributors.
In 2024, the three big themes we are interested in are performance, ecosystem, and SQL standard compliance.
On the performance side, the EARLIEST/LATEST aggregators now support numerical columns during ingestion. Making it easier for you to model the data into better shapes for querying.
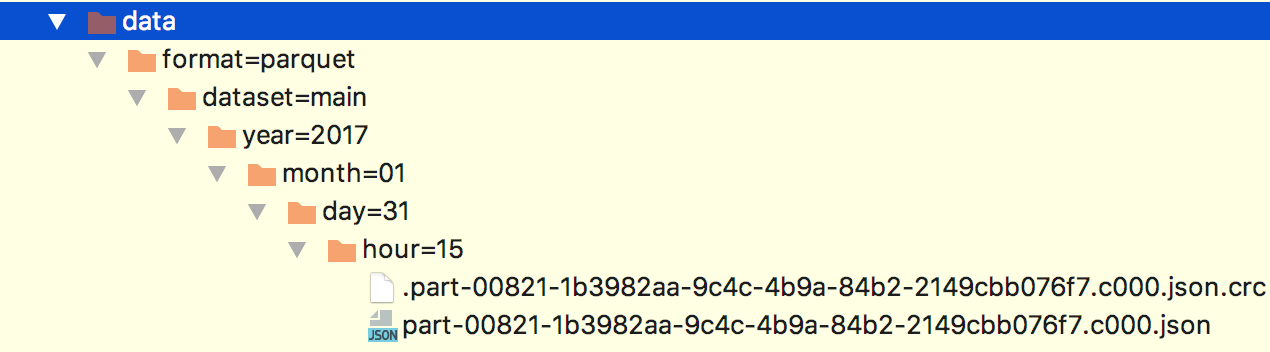
On the ecosystem side, we continue to improve the multi-stage query (MSQ) engine, adding more cloud support and the ability to export data. We’ve also improved the ingestion system. You can now ingest folder names (such as parquet partitions) into Druid. This enabled Druid to source data from Deltalake, making it substantially easier to integrate Druid into the rest of your data platform.
On the SQL standard compliance side, we have added support for PIVOT/UNPIVOT and unequal joins. Window functions have also seen substantial improvements and are ready for testing in more use cases.
Lastly, there are 2 new extensions, Spectator Histogram and DD Sketch, both of which provide improved versions of current data sketches for specific use cases.
Please read on for the details on the above-highlighted features. We are excited to see you use the latest version and to share your questions and feedback in the Druid Slack channel.
MSQ – Azure and GCP support
MSQ is a query engine that supports long-running queries. It uses object stores as intermediate storage to recover from failures. When MSQ was initially launched, the system was built to support the AWS S3 object store as intermediate storage to enable fault tolerance. In this release, we’ve introduced support for both Azure blob storage as well as GCP blob storage as options to enable fault tolerance on Azure and GCP clouds.
You can configure this by setting `druid.msq.intermediate.storage.type` to either `google` or `azure`.
MSQ – CSV Export
As we expand support for object stores, we are also working to make Druid easier to integrate with the rest of the data ecosystem. Oftentimes, people create useful metrics using Druid’s rollup capabilities during data ingestion. But sometimes, downstream systems might require access to those metrics in their own format.In this release, we’ve added the ability to export to S3 with CSV format using the syntax from the following example. Over time, we’ll expand support for other file formats and destinations. Please do reach out to us on the Druid community on Slack and let us know what other format/destination combination is most useful to you.
INSERT INTO EXTERN (S3(bucket=<...>, prefix=<...>, tempDir=<...>))AS CSVSELECT<column>FROM<table>
Unequal joins
Joins are fun; in many scenarios, the data relationship you are trying to analyze is asymmetric. For example, you might want to join a table of events with a table of promotions where the event date falls within the start and end dates of the promotion. Or analyze data in a social network, finding users who follow many but are followed by few. In those cases, you’ll need the ability to do non-equal joins. The highlights below are the new capabilities we are introducing in this release.
SELECT A.follower_id, a.following_count, b.follower_countFROM (SELECT follower_id, COUNT(*) AS following_countFROM FollowersGROUP BY follower_id) aJOIN (SELECT followed_id, COUNT(*) AS follower_countFROM FollowersGROUP BY followed_id) b ON a.follower_id = b.followed_idAND a.following_count > X -- X is the threshold for 'following many'AND b.follower_count < Y; -- Y is the threshold for 'followed by few'
PIVOT / UNPIVOT
Pivot table is a popular feature in Excel and used in a lot of reporting scenarios. Imagine you have the following table:
Product ID
Month
Sales
1
Jan
1000
1
Feb
1500
2
Jan
2000
2
Feb
2500
“Lets say you want a report that does a monthly summary per product over time similar to the one below. You could do a “Pivot” of your data to easily get this table into the desired report format
Product ID
Jan
Feb
1
1000
1500
2
2000
2500
PIVOT (aggregation_function(column_to_aggregate) FOR column_with_values_to_pivotIN (pivoted_column1 [, pivoted_column2 ...])
EARLIEST / LATEST support for numerical columns
In Druid, you can use LATEST() as an aggregation function to find the latest record for a given column based on __time. This is useful to find the last data point you’ve received, for example. Under the hood, LATEST() handles strings and numerical data differently (it is translated to the stringLast or doubleLast native functions)
Previously, you were limited to using numerical last/first aggregators at query time only. In this release, you will be able to use them on the ingestion side as well.
Native query first/last
SQL EARLIEST/LATEST
Ingestion first/last
String
Number
String
Number
String
Number
Druid 28
✓
✓
✓
✓
✓
✗
Druid 29
✓
✓
✓
✓
✓
✓
System fields ingestion
For those who have ventured into data lakes, it’s often that table partitions form part of the file structure, with prefixes or folder names. In this release, you gain the capability to ingest this system information, including file names and object bucket store prefixes.
Deltalake support
In Druid 28.0, we introduced experimental support for sourcing data from Iceberg. In this release, we are adding support for sourcing data from Deltalake.
It’s as simple as loading the “druid-deltalake” extension and point to your lake location in a multi-stage query SQL.
REPLACE INTO"delta-employee-datasource" OVERWRITE ALLSELECT*FROMTABLE( EXTERN('{"type":"delta","tablePath":"s3a://your-bucket/your-prefix/your-table"}','{"type":"json"}' )) EXTEND ("ID"INTEGER)PARTITIONED BY ALL
What’s cool about this is in conjunction with Async queries, you can now directly query a deltalake table via Druid without ingestion!
UNNEST and JSON_QUERY_ARRAY
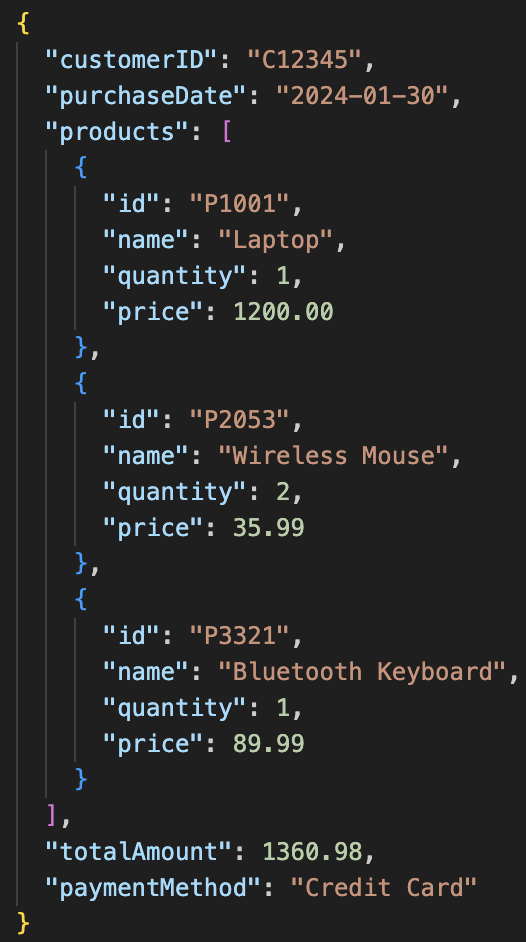
In this release, we’ve added JSON_QUERY_ARRAY, which is similar to JSON_QUERY except the return type is always an array. This allows you to apply UNNEST with JSON objects, providing a composite to flatten the arrays of objects.
For example, in the table below, it contains 3 purchases, you can now use JSON_QUERY_ARRAY(“products”, “$”) to extract the array of products and UNNEST it to produce the table below.
customerID
purchaseDate
productID
productName
quantity
price
totalAmount
paymentMethod
C12345
2024-01-30
P1001
Laptop
1
1200.00
1360.98
Credit Card
C12345
2024-01-30
P2053
Wireless Mouse
2
35.99
1360.98
Credit Card
C12345
2024-01-30
P3321
Bluetooth Keyboard
1
89.99
1360.98
Credit Card
Spectator histogram and DDSketch
The Spectator-based histogram extension (`druid-spectator-histogram`) provides approximate histogram aggregators and percentile post-aggregators based on Spectator fixed-bucket histograms.
Spectator histogram is more size efficient than the current quantile sketch and uses less memory during queries/ingestions. Based on the example data provided by the contributor, you can see an 8x reduction in storage footprint when comparing a spectator histogram column with a quantile sketch column.
Spectator histograms are optimized for accuracy at smaller values but with less absolute accuracy at higher values. Testing this with your own dataset will help you to make an informed space vs. accuracy trade-off.
In the same release, there is a community-contributed DDSketch (https://github.com/DataDog/sketches-java) into Druid. When compared to quantile sketches, DDSketch offers higher accuracy at the ends of the quantiles. Specifically, this makes it accurate to calculate P90 and P10 values with higher accuracy with less K tuning.
Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....