Imply Enterprise
Get the tools and support you need to efficiently run Apache Druid yourself on any hardware and across any cloud for real-time insights.
Commercial distribution of Druid
Imply Enterprise provides the ease and flexibility to deploy Imply’s commercial distribution of Druid on any cloud. It includes cluster management software, performance monitoring, and 24×7 committer-driven support to ensure Druid is running smoothly.
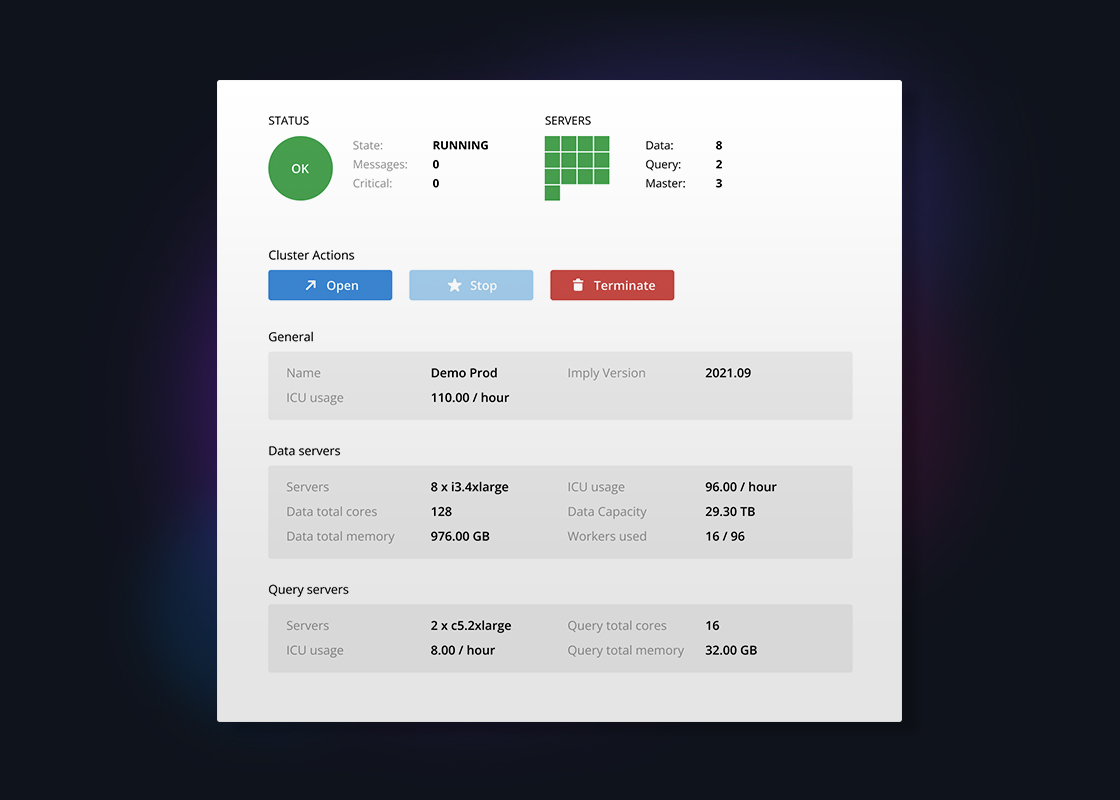
Data operations simplified
Easily manage your Druid clusters with Imply Manager’s comprehensive and intuitive UI. This enables you to stand up your cluster quickly and perform many cluster operations with point and click ease. You’re never flying blind because in a single location you get access to key cluster information such as instance types, logs, VPC, security certificates, and API endpoints.
Finally, our management software helps ensure a seamless experience for your end users because cluster operations like creating, deploying, running, monitoring, scaling, cloning, and terminating clusters are easily completed with zero downtime.
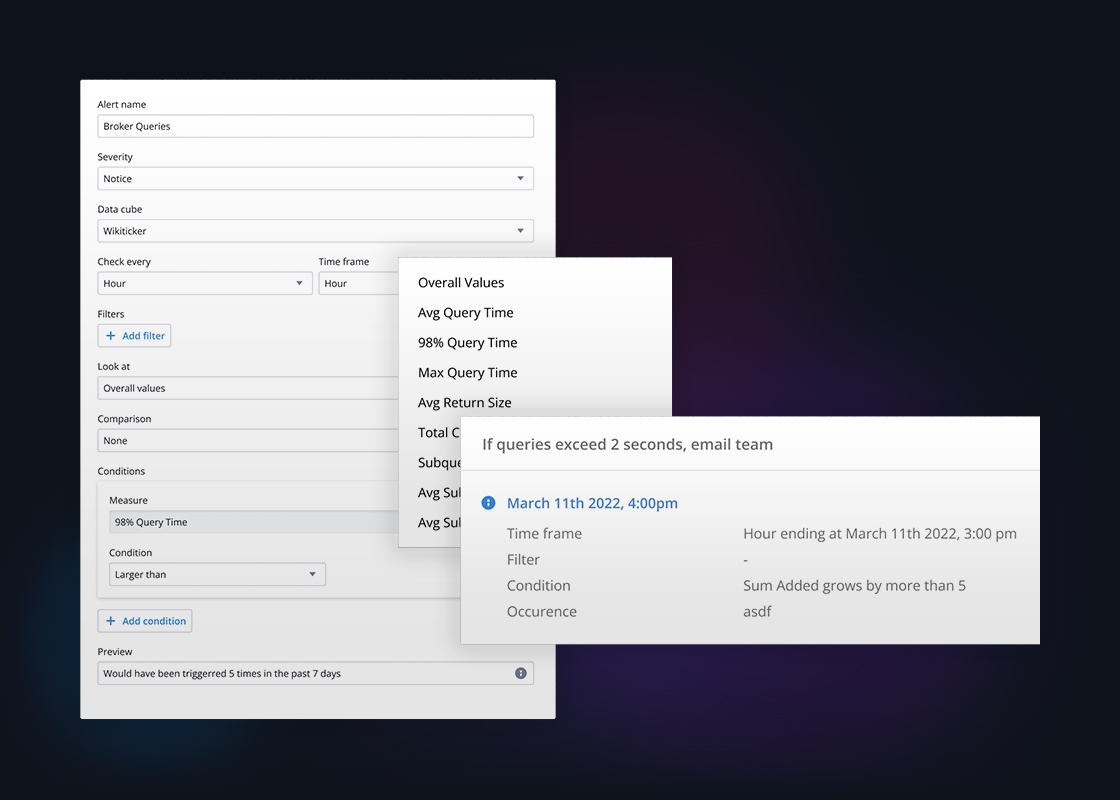
Advanced performance monitoring
Know your environment inside and out. 24×7 monitoring of your clusters helps you diagnose performance bottlenecks and avoid operational issues.
Create and view metrics, dashboards and alerts on the health of your Druid Cluster. Analyze query performance in detail by drilling down into all factors that contribute to query and ingestion issues. Reduce hardware expense and avoid over-provisioning with real-time insights into cluster-wide resource use.
Committer-driven support
Founded by the original creators of Apache Druid, Imply delivers deep expertise in Druid (so you don’t have to be an expert) and a world-class support organization to help whenever you need us. Best practices, whitepapers, and technical documentation provide the blueprint to easily optimize your cluster from the start. With Imply as your partner and our expert advice, you can take your next analytics application to the next level by getting up and running faster, easier, and with lower risk.

“Because Imply has all of these features built-in, engineers focus on making products, not operational work.”
-
Imply Polaris
Database-as-a-service- Fully managed cloud service
- Jumpstart or migrate projects quickly
- Conduct your own POC
-
Imply Enterprise Hybrid
Hybrid managed in AWS- Brings the ease of a cloud service to your AWS VPC
- Access to our managed control pane
-
Imply Enterprise
Commercial software- Deploy on-premises or in the public cloud
- Access to Imply’s Druid expertise and management software