Lightning fast and robust. What’s under the hood at Germany’s most advanced advertising platform
Mar 26, 2021
Fernando Melone
10M ARTICLES CREATED
30X NUMBER OF USERS ENABLED WITH SELF SERVICE ANALYTICS
25% COST REDUCTION WHILST IMPROVING PERFORMANCE
Business Goals
Ippen Digital, subsidiary of the Ippen Publishing Group in Germany led by Jan Ippen, offers an integrated platform to aggregate content, drive subscription growth and manage advertising across a broad range of digital content. Ippen Digital is a pioneer in helping publishers transition to new digital revenue achieved through more sophisticated use of audience data and content recommendations.
Back in 2018 they started with open source Druid 0.11 and managed to deploy and configure all by themselves.
the early Druid was kind of a beast, but we managed to get around some of the weaknesses of the open source product, and it proved to make sense in our environment”
Jan Ippen, CEO Ippen Digital.
At that time they were in the midst of creating a data application platform which meant they also had to create their data environment and the platform core. The content core didn’t involve too much data processing. It was a content distribution core, but for years Jan was convinced which route to take, and that was the data route. At that moment, they were trying out various technologies and various approaches to the data landscape when they found Druid and were immediately stuck with it.
Technology Requirements
Because Ippen Digital moves a lot of data along with that traffic they handle and with the data points they wanted to aggregate, they needed an engine that was way more capable than most of the other vendors, they thought of trying maybe just an in-memory database or other slower database solutions, but realized they use too much overhead to aggregate data. And real-time aggregation from their solution’s perspective was really interesting and at one point necessary
Make or buy – Why Imply
Druid was beloved by the team and quickly became mission critical. Ippen discovered professional services were needed and more stability and automation in the operations. A decision had to be made to either build a bigger team to manage Druid or have a partner, a vendor, that can provide stability, the services, with the experience to drive forward. That is when the decision to engage Imply was made.
Business Outcomes
Opened a new data stream to ad providers to immediately increase revenue
Ippen Digital opened their data streams to get from their upstream providers of the ads, all the information, details and dimensions they needed, so that they can aggregate and analyze all the advertising data. Things like: “are the advertisers bidding for this user, for the context and the user, or just for the context? In which segment of bidding height do they put this user?” and more, helps them support their editorial assistance tools to create more of that particular content, or that target group, or the size of the groups, etc. And all of these adjustments and optimizations depend 100% on real-time data exploration.
Data platform simplification for ease of use and scalability
“Scalability is the core of our product and our solution”
Jan Ippen
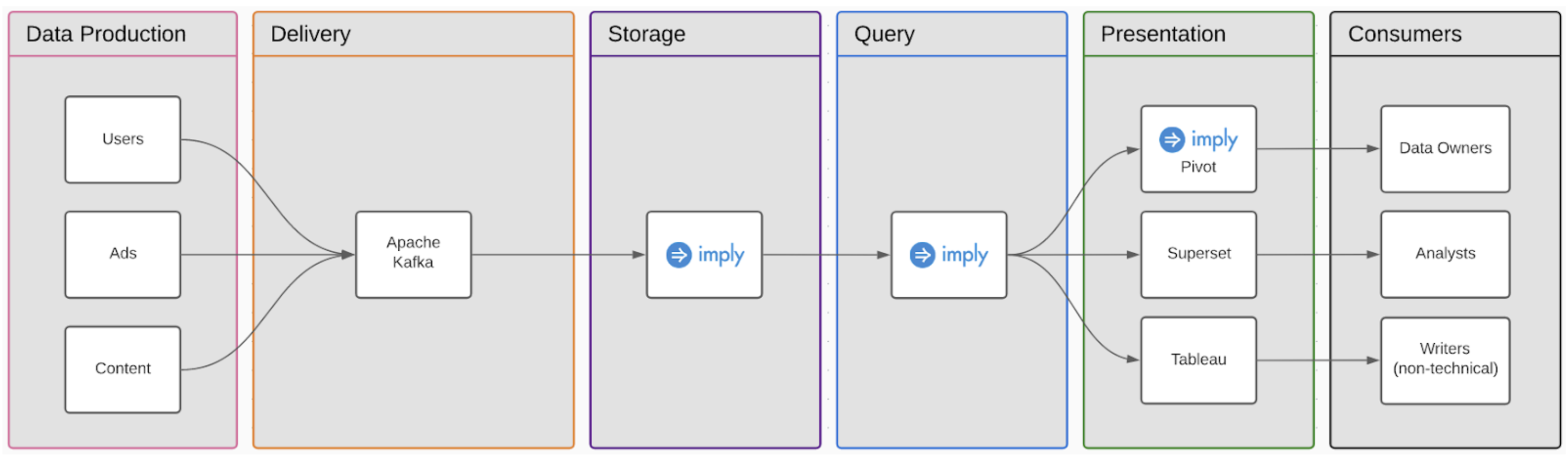
The data application platform that Jan set out to build is not just a data lake. It was pretty clear for them that they didn’t want to have 10 databases with hundreds of tables and files and have a “data swamp”, filled with silos that are not integrated. Ippen tried to figure out what was the setup to use that had the least amount of tools as possible , and that’s when they created their data application based on three main components, Kafka, Imply and TigerGraph. All data ends up in streaming Kafka topics, and it’s then ingested by Imply. Absolutely 100% of their data is accessible in real-time, and that’s what Jan envisioned from day 1.
Complete data ownership and Innovation is now possible thanks to Imply
“If your environment is ready and is optimized around the capabilities of Imply, it becomes a very valuable tool”
Ippen was able to unlock new possibilities and improvements thanks to having Imply at the core of their data platform. Everything related to machine learning improvements, tuning, and experimentation is fed by Imply to JupyterHub where the team collaborates and builds cutting edge capabilities for their product.
As mentioned before, the third component of their data application is TigerGraph, a graph database that processes over 10 million articles worth of data, aggregated and served by Imply. They utilize this for machine learning to optimize internal link building, growing their knowledge graph and extending user profiles.
This is a very compact, simple, yet powerful environment where they have real-time data for everything. They have aggregated data and analytics backend with Imply, and connected data with TigerGraph powered by Imply.
Last word to the CEO, Jan – “So few sources, and complete data ownership. We love it”
If your current architecture can no longer scale to meet your users’ load and the magnitude of events generated and collected, then check out how Imply can help.
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...