Independent Performance Benchmark: Apache Druid versus Presto and Apache Hive
Jul 17, 2019
Rick Bilodeau
A recent paper by researchers at the University of Minho in Portugal compared the performance of Apache Druid to well-known SQL-on-Hadoop technologies Apache Hive and Presto.
Their findings: “The results point to Druid as a strong alternative, achieving better performance than Hive and Presto.”
In the tests, Druid outperformed Presto from 10X to 59X (a 90% to 98% speed improvement) and Hive by over 100X.
Testing Methodology
The highlights of the test configuration are:
They ran the Star Schema Benchmark, a well-known test of database query performance. Since Druid does not fully support all types of joins, the data was denormalized into flat tables.
They ran tests at three “Scale factors”- workloads of 30 GB, 100 GB and 300 GB.
They used identical infrastructure for all tests.
They compared the configurations that delivered the best results from each technology.
They varied Druid segment granularity, query granularity and the use of partition hashing.
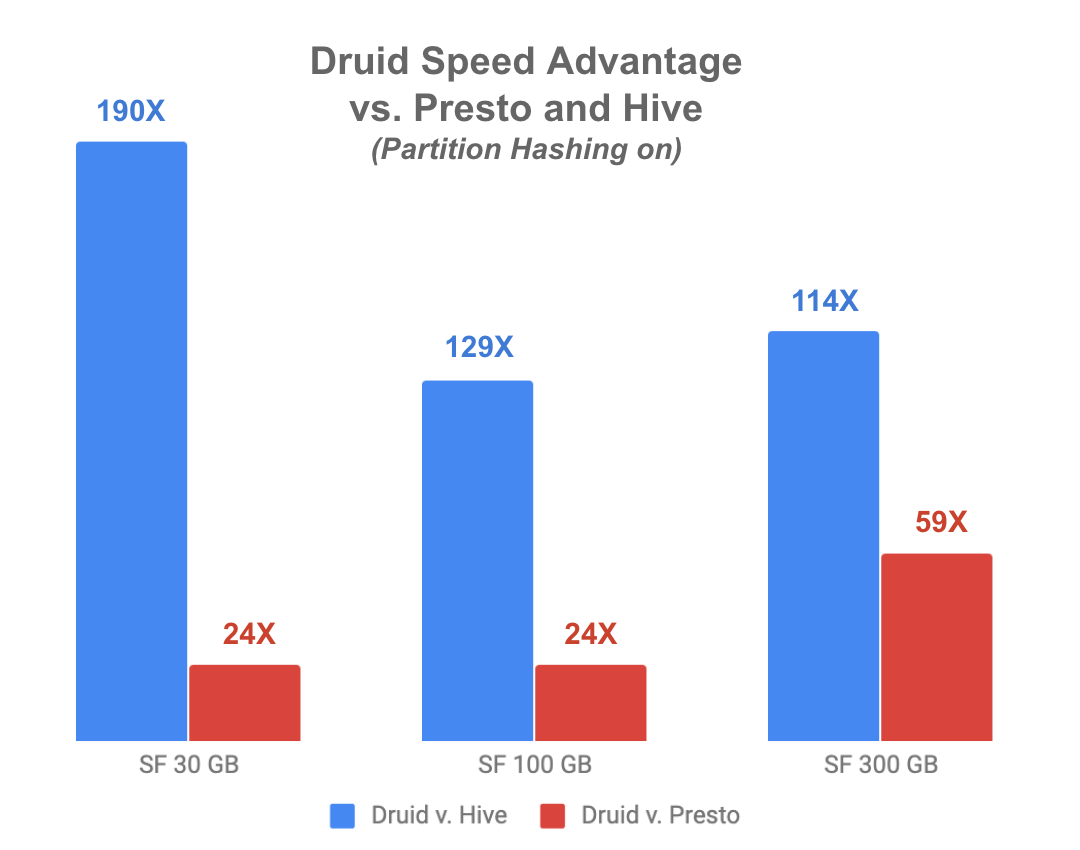
Druid up to 190X faster than Hive and 59X faster than Presto
Comparing the best results from Druid and Presto, Druid was 24 times faster (95.9%) at scale factors of 30 GB and 100 GB and 59 times faster (98.3%) for the 300 GB workload.
Comparing the best results from Druid and Hive, Druid was more than 100 times faster in all scenarios. Druid was 190 times faster (99.5% speed improvement) at a scale factor of 30 GB. This advantage fell to 114 times faster (99.1%) at 100 GB and 129 times faster (99.2%) for the 300 GB workload.
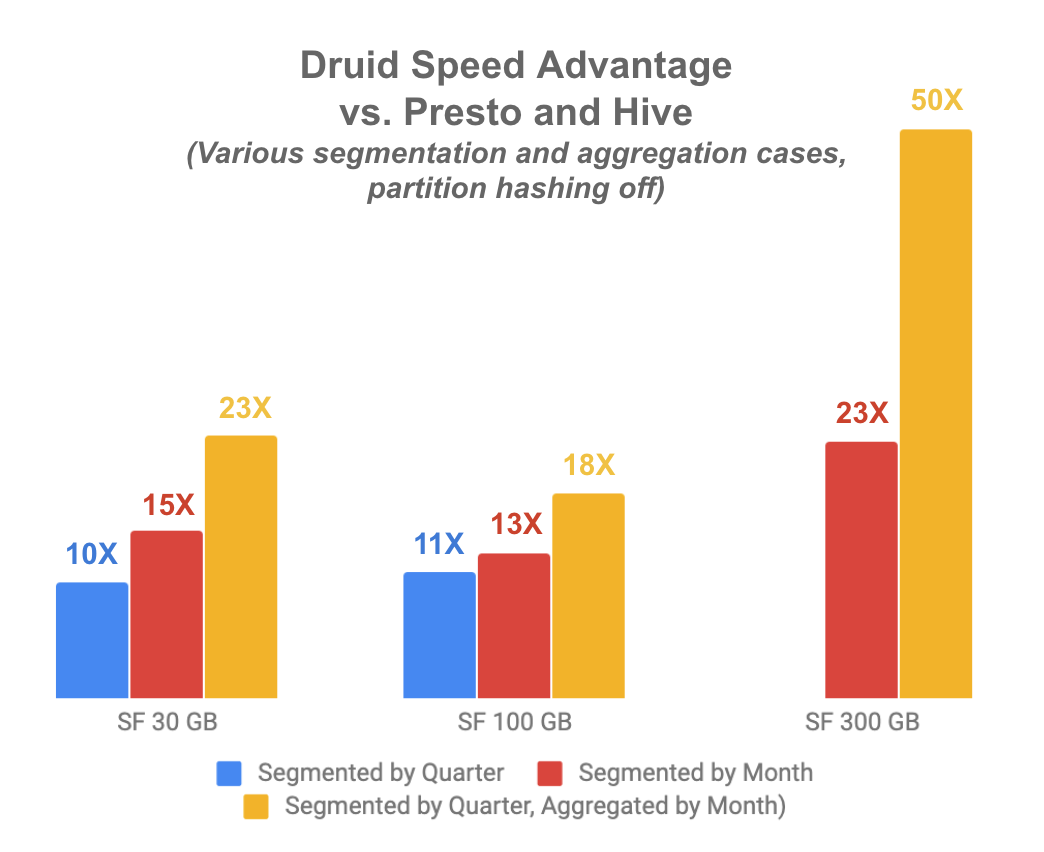
Partition Hashing Disabled: Druid 10X to 50X faster than Presto
Since partition hashing is an advanced option, the researchers decided to additionally test Druid against Presto with this feature disabled. While Druid’s performance declined, it was still much faster than Presto, ranging from 10 times to 50 times faster depending on table and scale factor.
The chart below demonstrates performance using three different tables. The first table (blue) includes all attributes (named Scenario A in the report) with no aggregation, segmented by quarter. The second table (red) is segmented by month, using a data set that only includes attributes needed to answer the queries (Scenario N). The third (yellow) is segmented by quarter and aggregated by month, using Scenario N.
Druid’s performance advantage grew with the scale of the workload and the ability to aggregate, reaching a peak of 50 times faster than Presto, even with partition hashing disabled.
For more details on how these tests were conducted and the complete results, we encourage you to download the paper Challenging SQL-on-Hadoop Performance with Apache Druid from authors Jose Correia, Maribel Yasmina Santos, and Carlos Costa of the University of Minho.
If you are interested in using Druid to enable real-time analytics from your Hadoop data lake, take a look at our Hadoop guide on the subject.
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....