Tutorial: An End-to-end Streaming Analytics Stack for syslog Data
Apr 18, 2019
Eric Graham
Read Part 1. This is Part 2 of our ongoing series on using Imply for network telemetry data.
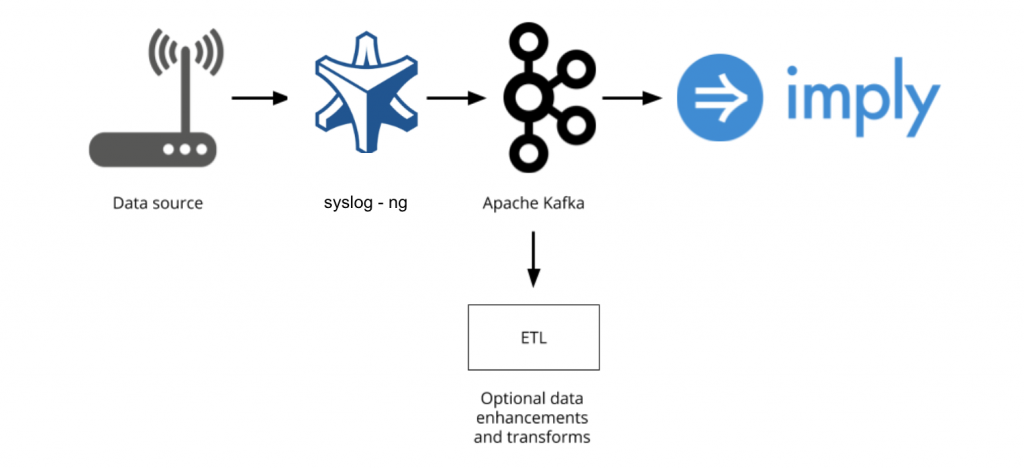
In this tutorial, we will step through how to set up Imply, Kafka, and syslog-ng kafka to build an end-to-end streaming analytics stack that can handle many different forms of log data. The setup described will use a single AWS instance for simplicity, but can be used as reference architecture for a fully distributed production deployment.
Prerequisites
A bare metal server or cloud instance (such as an AWS m5d.xlarge instance) with 16GB RAM, 100GB of disk, and an ethernet interface.
The server should be running Linux.
You should have sudo or root access on the server.
A router, switch, firewall, or host that can send syslog data.
The architecture we will be setting up looks like the following:
Install librdkafka, syslog-ng and syslog-ng kafka
Follow the installation steps for librdkafka, syslog-ng and the syslog-ng kafka connector from the following URL but ignore the configurations:
For the syslog-ng configuration use the following as an example. Fill in the source IP and destination port of your device sending syslog data. This setup is specific for UDP syslog and can be used to collect from external devices, like routers, sending syslog.
sudo vim /etc/syslog-ng/syslog-ng.conf
######################## # Sources ######################## # This is the default behavior of sysklogd package # Logs may come from unix stream, but not from another machine. # source s_src { # system(); # internal(); udp(ip(<your source router IP>) port(514)); };
Modify conf-quickstart/druid/\_common/common.runtime.properties with the right directories for segments and logs. If you have plenty of local disk you can keep the default configuration. A good reference is the Imply quickstart documentation: https://docs.imply.io/on-prem/quickstart
Start Imply from the Imply directory with the quickstart configuration by typing the following:
Create a Kafka topic using the following command where \<topic name> is replaced with the name you want – such as syslog. From the Kafka installation directory, run:
Start sending syslog to the system you have just set up. Make sure to change your security rules to allow the source IP of the syslog sender and the destination port that you configured on the router to send to. If everything is working properly you should see syslog messages displayed on your console. When you see syslog messages registered, you can check your Kafka consumer by running the following from the Kafka installation directory.:
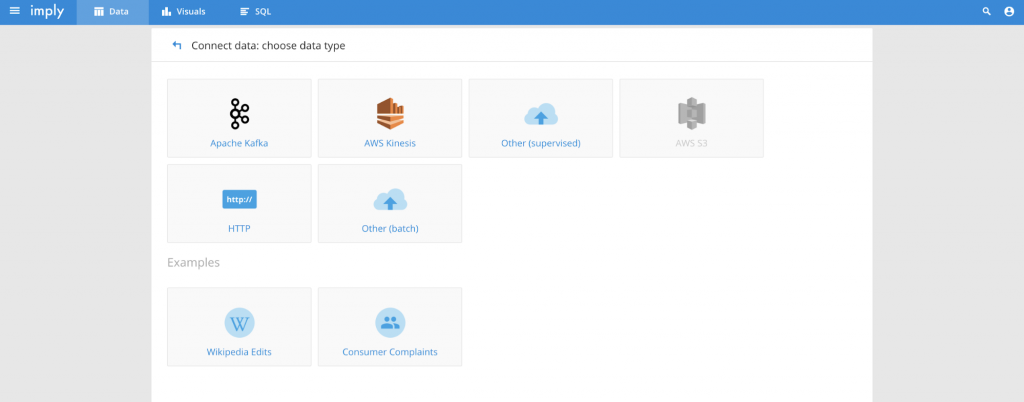
Start Imply by opening a browser and either going to localhost:9095 (if browser is being run from your localhost) or \<public_ip:9095>. Remember to modify your security rules to allow destination port 9095 from your source IP. Select the Data/+Load Data (upper right), and the following options will be displayed.
Select the Apache Kafka.
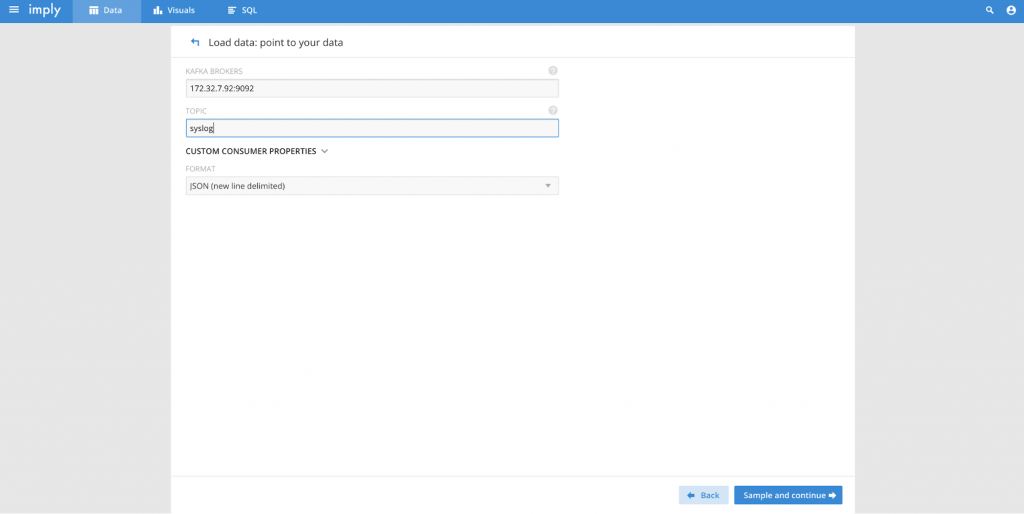
Fill in the details for the Kafka process including IP:consumer port (typically 9092) and the topic name that you created previously (e.g. 192.168.1.2:9092).
Select “Sample and continue”
Select “Next” for the remaining screens to start loading your syslog data into Imply.
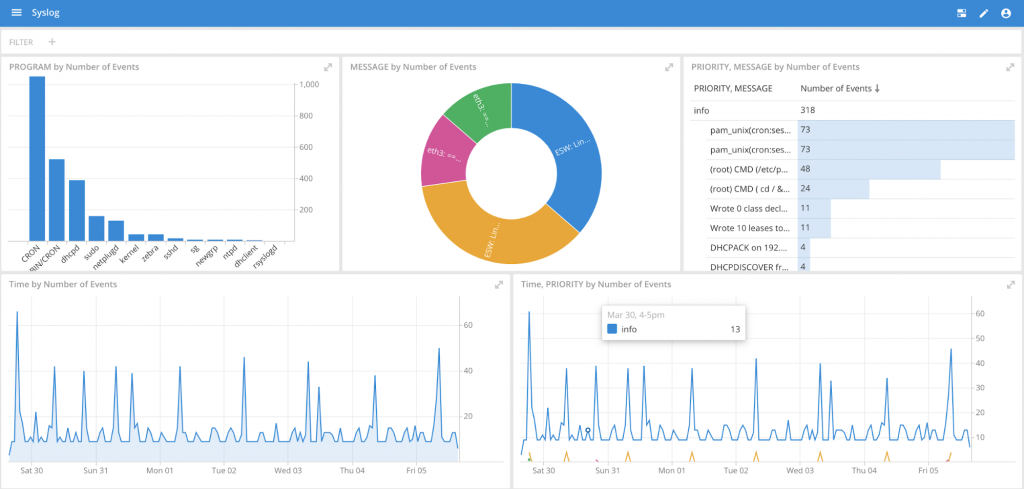
When your data is loaded you can now slice and dice your syslog data at amazing speeds.
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...