We’ve added some new features, functionality and connectivity to Imply Polaris over the last two months. We’ve expanded ingestion capabilities, simplified operations, and made it easier to only pay for what you need.
Polaris, a Druid as-a-Service, enables you to start extracting insights from your data within minutes—without the need to procure any infrastructure. You can use the same cloud database to manage your data from start to scale, with automatic tuning and continuous upgrades that ensure the best performance at every stage of your application’s life.
The combination of these new Imply Polaris options continue to help developers build modern analytics applications faster, cheaper, and with less effort. In this blog, I’ll provide you with an overview of all the recent additions.
Flexible Data Ingestion
More options for Streaming Ingestion Since the foundation for instant decision-making and agile development are streaming data pipelines, we’re excited to support more ways to mobilize streams in Polaris.
On top of pull-based ingestion capability for Confluent Cloud and native API-based push streaming, Polaris now adds support for ingesting streams of events from both Kafka and Kinesis.
Apache Kafka: HTTPS-based Kafka connection uses our Push API endpoint to automatically group and compress your data and handles authorization token renewal for you.
For any Kafka API, you can use Polaris to ingest data from any number of Kafka topics.
Amazon Kinesis: Easily ingest data from an existing Kinesis stream by reading data from a connection. To create a connection, users only need to grant a few standard security permissions (using AWS IAM) and provide a stream name and endpoint. You can configure any number of data streams.
Note: For Confluent Cloud, Apache Kafka, and Amazon Kinesis, Imply Polaris ingests data with exactly-once semantics to ensure that each event is ingested once and only once. Every event is immediately available for querying, as discussed here.
More data formats for batch ingestion Initial batch ingestion support for Polaris was the JSON data format which is great when your source data is coming from a NoSQL database like MongoDB. Now, we’ve added additional formats to make it easier to ingest batch data using common open source data formats:
Delimiter-separated values: Comma-separated values (CSV), Tab-separated values (TSV). and Customer text delimiter Apache Parquet: column-oriented data file format Apache ORC: column-oriented data file format Apache AVRO: row-oriented data file format
Native S3 ingestion For batch-based analytical use cases, such as evaluating results with a large amount of historical data, Imply Polaris supports native ingestion from Amazon S3. Users only need to grant a few IAM permissions to create a connection to an S3 bucket.
Ingestion-time data transformations Data transformation makes data useful by enhancing, enriching, aligning, and combining raw data sources into data sets that are easy to use. You may want to add approximations, such as Theta Sketches. You may want to join data from multiple tables to create an easier to use denormalized large table.
Or you may want to roll up a collection of transactions by time, such as hourly or daily totals. Usually, these aggregations are implemented with ahead-of-time aggregation, which means you don’t have access to your data until the end of the aggregation interval. But what if you want both rollup summaries for fast query response and immediate access to incoming data?
With Table to Table ingestion, you can now ingest data directly from an existing table into a new table in Polaris.
This is a really nice feature if you have a detail table for customer transactions for a single day, which allows for fine-grained slicing and dicing, but you also need to consider customer trends of the same data over an extended period of time. This is now possible by ingesting from the detail table into an aggregate table. Now, your end users can query the data from different perspectives without having to re-ingest the data from an external source. The summary data is available in the aggregate table while incoming data is always available in the detail table, which you can JOIN together at query time to get both quickly!
Push ingestion as an explicit job As I mentioned earlier, Polaris enables push streaming directly in applications. By using an API call, events can be pushed to Polaris. This is a good approach to utilize streaming data in your application without having to do the work of configuring and managing a streaming service. Polaris creates and manages all the streaming architecture needed for fast, reliable event delivery.
Polaris now offers the option of push Ingestion as an explicit job where you can choose to define data transformation during ingestion. The most common use case is for ETL (extract, transform, load) style ingestion. This automates the process of effectively preparing raw data for fast analysis (saving you time) by enabling high data quality, availability, and reliability.
Append & Replace data Data in Polaris is partitioned by time, and many of the data management operations of Polaris work on a time-partition by time-partition basis.
We’ve made it really easy to update your time partitions based on a “Append” or “Replace” method. With Append, you can easily add newly ingested data to existing partitions. With Replace, Polaris is intelligent enough to only replace the partitions that actually have replacement data (while the partitions that have no replacement data are not touched).
Additional Roll-up Granularities Today’s applications can create millions of events in streaming data each second. As data accumulates, it increases the storage footprint, often leading to higher storage costs and decreased query performance.
Imply Polaris has long supported rollup granularity by intervals of a second, minute, hour, day, week, month, or year. Now that’s been expanded to add granularity by intervals of milliseconds, 15-minutes, 30-minutes, and calendar quarters.
Simplified Operations
With Polaris, we wanted to make it easier for anyone to get started building modern analytics applications. And most importantly, to get all the performance and availability out of Druid with the least amount of effort.
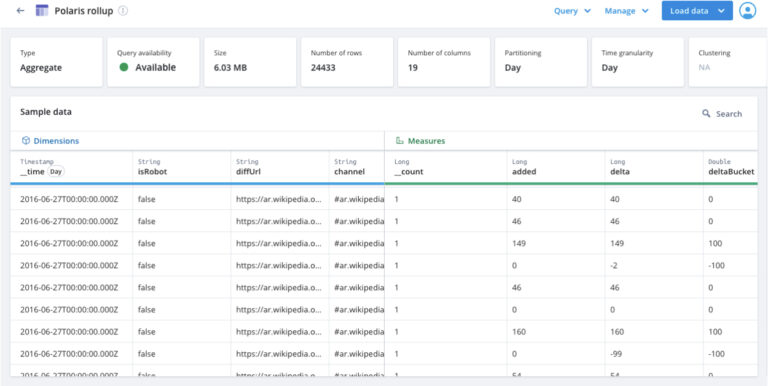
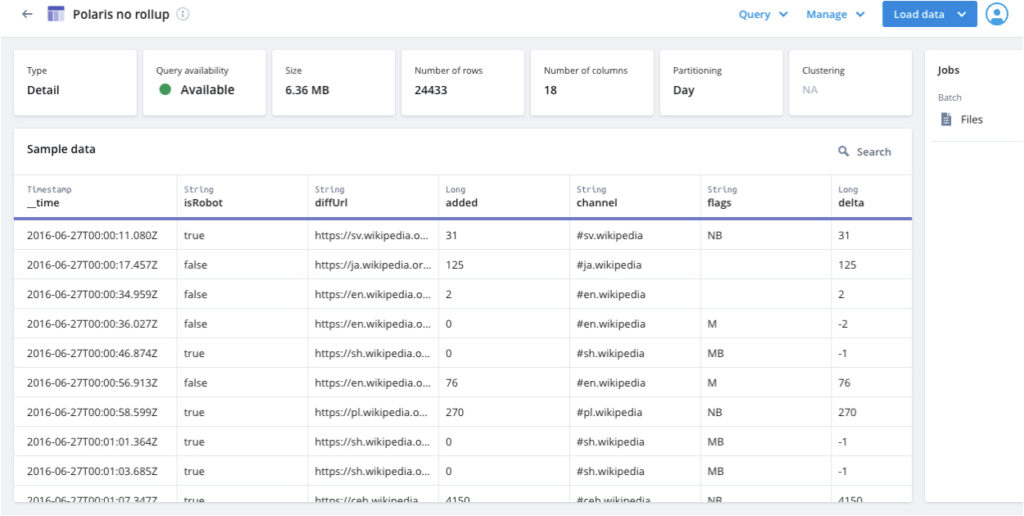
Tables with tags We’ve added a “Detail” tag or “Aggregate” tag for all tables at creation time. The reason behind this is to prevent users from changing a table from rollup to non-rollup (and vice versa) after a table has been created. Since detail and aggregate tables have different options, this helps prevent confusion for what’s possible with each table.
The following screenshots show two tables created using the same dataset. The first table is an aggregate table with time granularity set to Day.
The second table is a detail table without rollup.
Null Columns now queryable
You can now create a table and immediately start querying that table, even before ingesting any data. In the past, if you queried a table with no data the result would be an error message. Now, if you run that same query it will occur with no failure.
This can be important when you’re using automated code, such as dbt, which will create a blank table and test it before loading data.
SQL IDE in Polaris Polaris now has a new and improved SQL workbench to make it easier to execute a variety of SQL queries with tighter integration between Polaris and your analytics application. You can write your own queries across multiple tabs and there’s greater interactivity with the query result set. This enables you to get a seamless experience in your journey from testing queries in the SQL IDE to deployment in an application.
Fault tolerance across multiple availability zones Polaris runs on the AWS cloud. All components of Polaris now span across multiple AWS Availability Zones, where each Availability Zone has its own isolated power and network connections, making Polaris even more reliable.
Only Pay for What You Need
Polaris now delivers more flexible and predictable pricing. With Polaris, we’ve always offered the flexibility to pay per consumption for things like file storage and data ingestion but the query cluster was always-on. Now, you can pause that cluster when not in use for additional savings and easily turn it back on when you want to run queries.
Learn More and Get Started for Free!
Ready to get started? Sign up for a free 30-day trial of Imply Polaris—no credit card required! As always, we’re here to help—if you want to learn more or simply have questions, set up a demo with an Imply expert.
Other blogs you might find interesting
No records found...
Apr 14, 2025
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...
We are excited to announce the release of Apache Druid 32.0. This release contains over 341 commits from 52 contributors. It’s exciting to see a 30% increase in our contributors!
Druid 32.0 is a significant...