Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
We are excited to announce the release of Apache Druid 32.0. This release contains over 341 commits from 52 contributors. It’s exciting to see a 30% increase in our contributors!
Druid 32.0 is a significant release focusing on stability, performance, and moving experimental features forward.
Druid 32 introduces a key new feature – Projection, that can help you significantly improve query performance by pre-computing aggregations.
Distributed Embedded Projection
How can your dashboards load in seconds instead of minutes when there are billions of rows? One key trick is pre-computed aggregation or materialized views in traditional databases.
However, building materialized views in a distributed database is hard. The distributed nature of the data can lead to incorrect results due to a variety of conditions, such as intermittent network issues, node failures, cluster scaling or upgrades, etc.
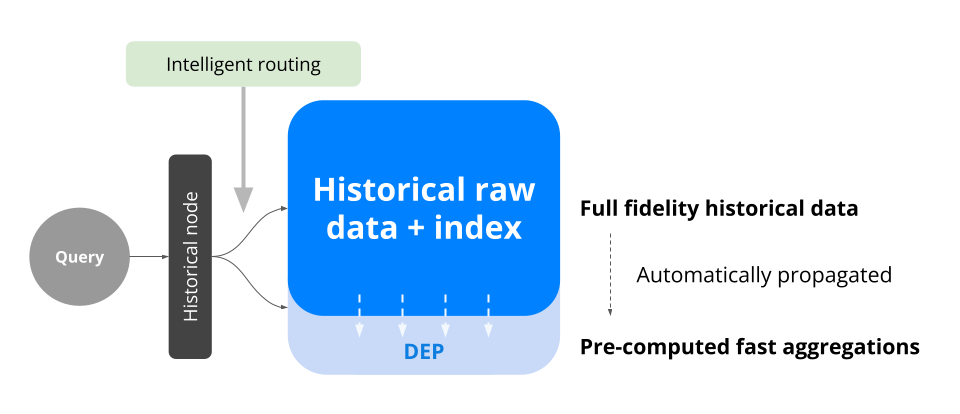
In this release, Druid introduces Distributed Embedded Projection (Projection abv.) that enables pre-computed aggregation while maintaining data consistency.
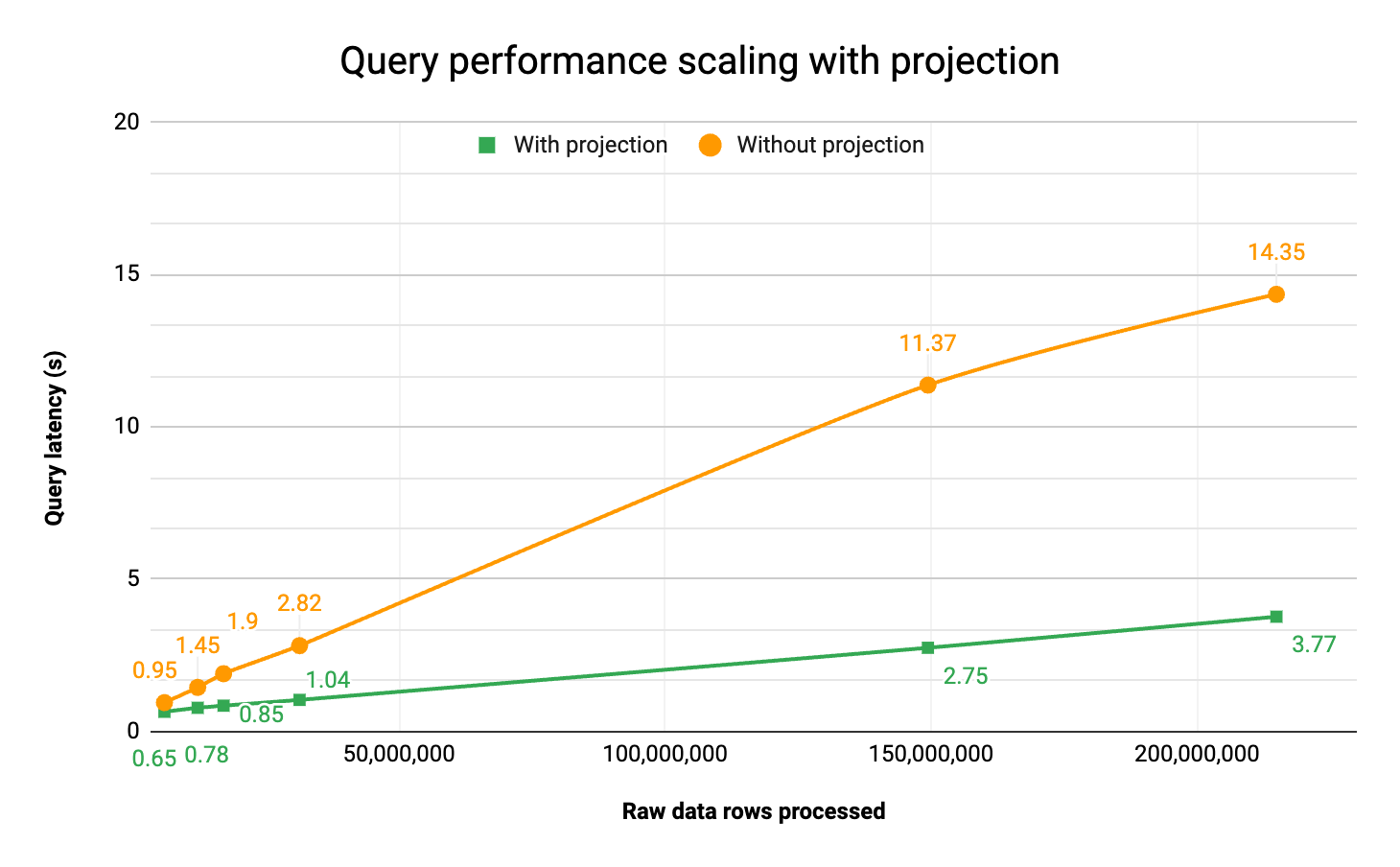
The most important part is the performance impact:
As you can see, as the data required to fulfill a query scales up, projection is able to maintain a much flatter latency curve.
It works by intelligently routing queries to pre-computed aggregates. Each table can contain more than one projection and the historical nodes will find the lowest cost one to fulfill the query fragment it receives.
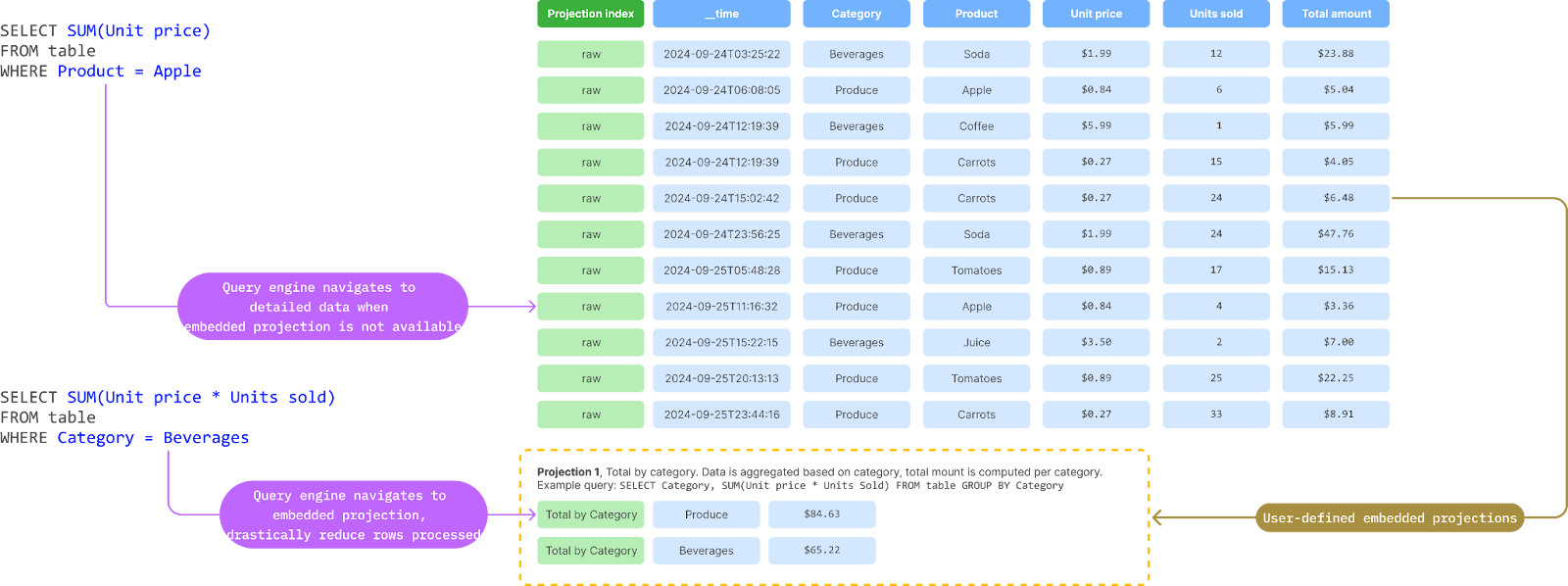
Conceptually, Projection acts like a series of “mini-rollups” inside the same segment file. Below is a diagram of how a subset of columns and different time granularity is made into a projection.
Iceberg AWS Glue support
In Druid 30, we’ve introduced Iceberg table format support. The initial version requires either the HiveMetastore or Iceberg local catalog. In this release, we are adding AWS Glue catalog support. This is also the first REST catalog we are supporting, paving the way for supporting other REST-based catalogs in the near future.
With the support of the Iceberg table format, you can easily ingest data from Iceberg, as well as query Iceberg as external tables without ingestion.
Deltalake improvements
Similar to Iceberg support, in Druid 29, we’ve introduced support for Deltalake as well. Over the past few releases, we’ve been steadily improving the integration with Deltalake. With added support for pushing down column selection to the file access layer, this substantially reduces the amount of data processed during query. In this release, we’ve addressed other issues on snapshot access, as well as decimal ingestion support.
We aim to remove the experimental tag on Deltalake in the near future. We encourage you to try out Deltalake integration and provide feedback on functionality and usability via Slack or Github.
MSQ Join hints
SQL-based ingestion has been the recommended solution for batch ingestion into Druid. This includes support to load data from Iceberg, Deltalake and a variety of sources. During ingestion, it’s very common to enrich and denormalize the data through a range of joins. Druid supports two kinds of joins, optimized for different queries:
Join type
How it works
Suitable for
Broadcast
Broadcast complete copy of dimension tables in joins to all processing nodes.
Fact(Big table)-Dimension(Small table) join
Sort merge
Only send data required for the small join batch to the required nodes
Fact(Big table)-fact join
What if you want to do both dimension-fact join and fact-fact joins in the same query? This is where join hints come in. For each join in a query, you can “hint” the engine by specifying the algorithm to use ー allowing a single query to operate both efficiently and scale out.
SELECT /*+ sort_merge */ w1.cityName, w2.countryName FROM ( SELECT /*+ broadcast */ w3.cityName AS cityName, w4.countryName AS countryName FROM wikipedia w3 LEFT JOIN wikipedia-set2 w4 3ON w3.regionName = w4.regionName ) w1 JOIN wikipedia-set1 w2 ON w1.cityName = w2.cityName where w1.cityName='New York'
Explore view
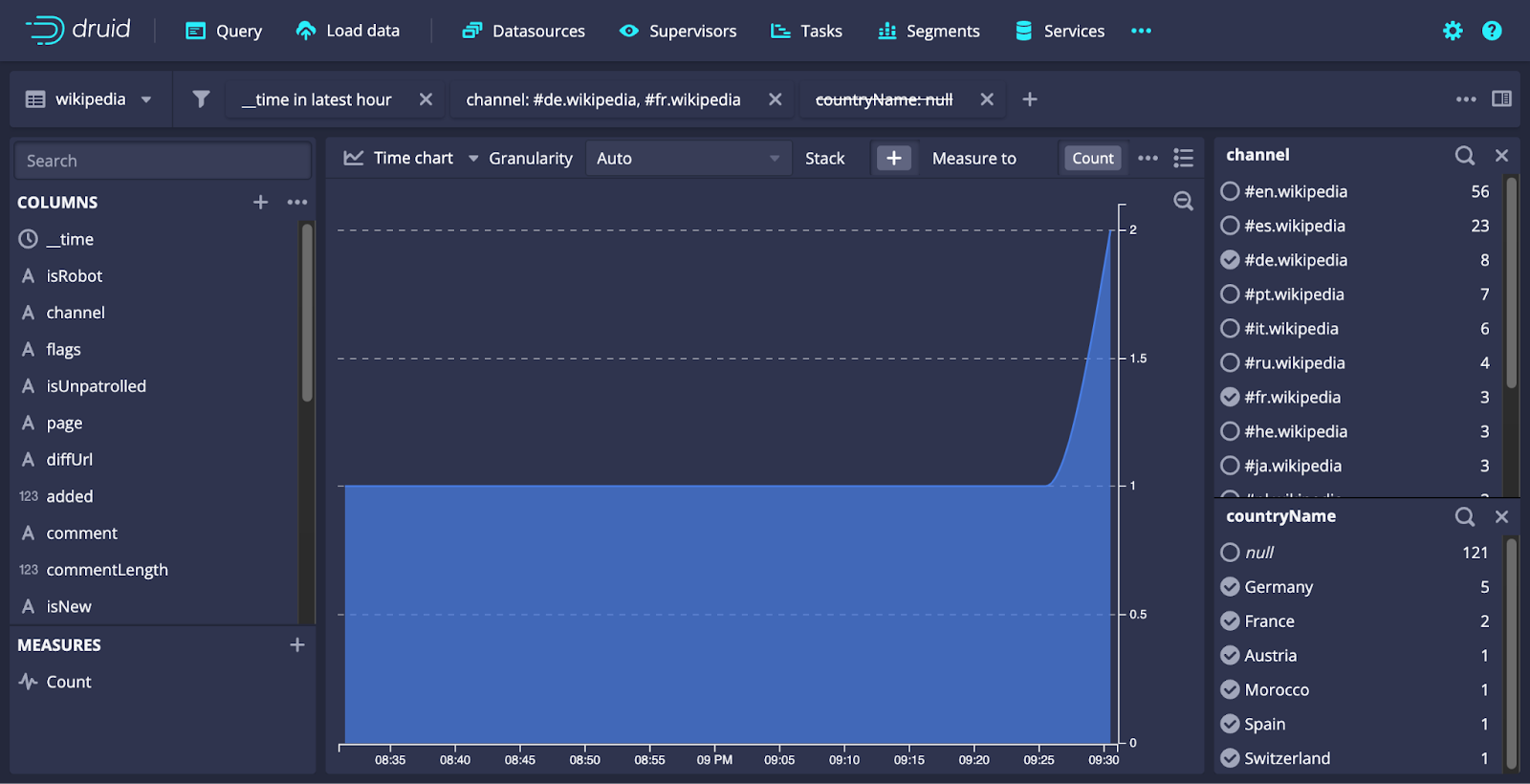
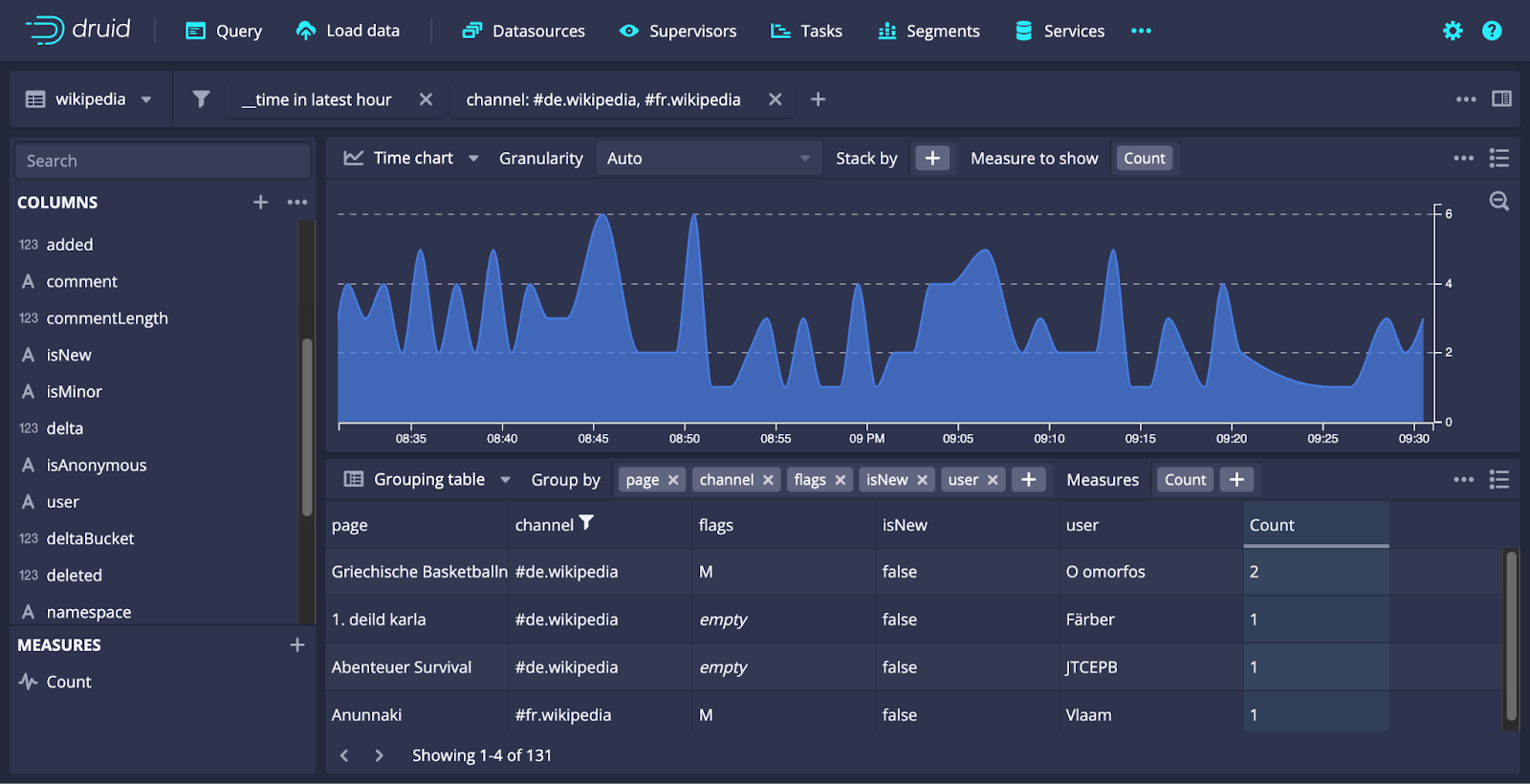
Switching gears, let’s look at the UI enhancements. In Druid 28, we introduced Explore view, an interactive dashboarding tool to allow you to quickly visualize Druid data in the web console. In this release, we’ve added a few other enhancements to the Explore view.
Filter helpers on the right to help you choose WHERE clause filters quickly with real data. (And stats!)
Side-by-side tiles allow you to mix and match various visualization types.
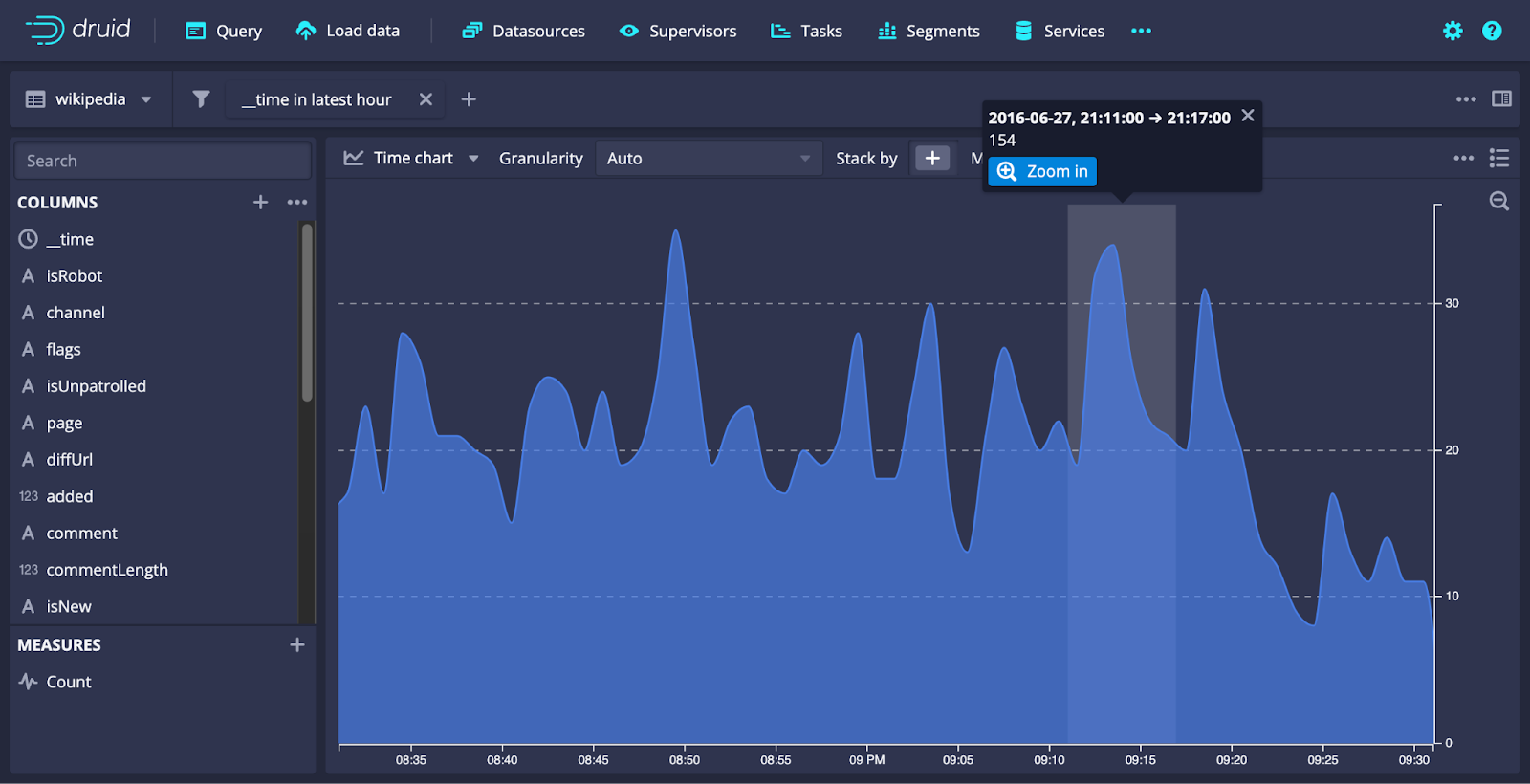
Lastly, a nifty zoom tool allows you to easily adjust the time range on time charts.
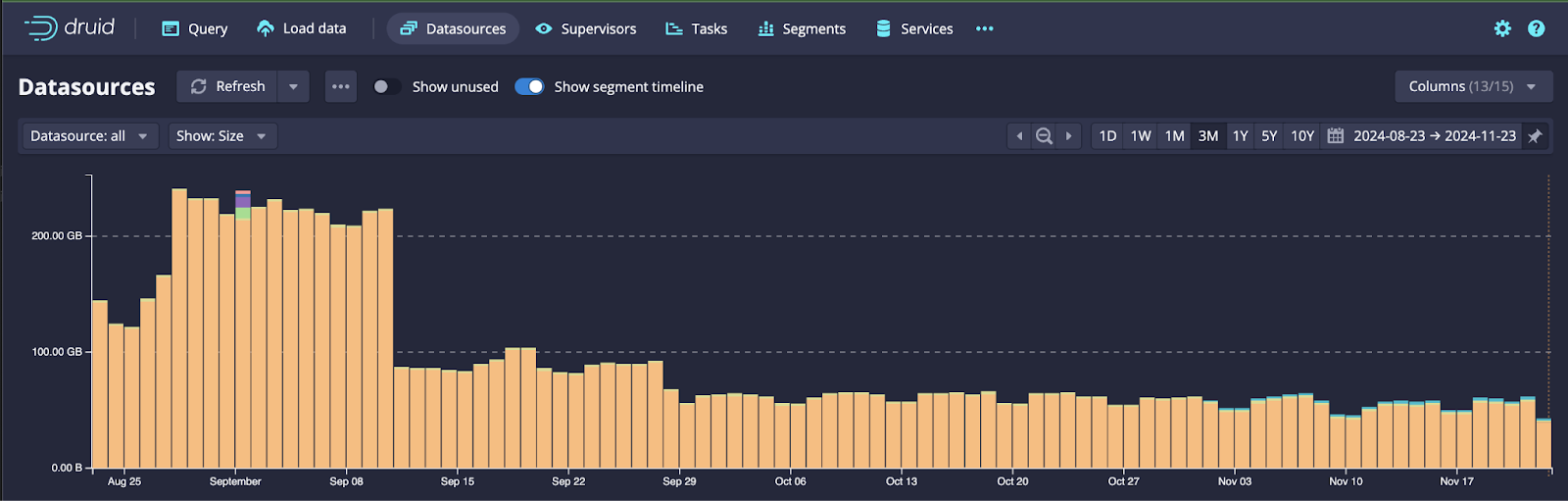
Segment timeline view
Segment timeline is an essential tool for any Druid cluster operator. Knowing where your data lives and understanding its distribution allows operators to proactively act on fragmentation and data skew issues before they impact query performance. The new segment timeline view is a lot more flexible. The DateTime selection is a lot more dynamic and allows you to view the segment timeline with different time granularity.
Other highlights
In addition to the above features, there are a few other impactful improvements.
Auto-guess numbers for CSV/TSV
This makes ingesting numbers from CSV/TSVs much less of a guessing game. By enabling the tryParseNumbers flag during ingestion, the ingestion engine will automatically map integers to long and floating point numbers to double.
gRPC/protobuf support for SQL queries
gRPC/Protobuf is an efficient API protocol. It uses very little bandwidth and is suitable for high concurrency workloads. But gRPC also has strict schema requirements. Thus, it’s mostly ideal for building APIs with fixed query result shapes.
To use gRPC, you can use the following code example:
QueryRequest.newBuilder().setQuery("SELECT * FROM foo").setResultFormat(QueryResultFormat.CSV).setQueryType(QueryOuterClass.QueryType.SQL).build();
This outputs the result in CSV format as a blob. You can also use protobuf by switching to
Lastly, Druid now officially supports ZGC, a garbage collector introduced in Java 11. By default, Druid uses G1GC, which is optimized for mixed workloads. ZGC has seen promising results in reducing latency as well as working well on large heap settings. If you believe you have a stable workload that’s highly concurrent, with relatively fixed query shapes and strong low latency requirements, ZGC is definitely an option you can consider.
Check out our blogs, videos, and podcasts! Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.
Other blogs you might find interesting
No records found...
Feb 25, 2026
Imply Lumi Product Preview: Removing the Cost–Performance Tradeoff in Observability
If you caught our recent product update, you’ve already seen the pace of development on Imply Lumi has been relentless. Last quarter, we delivered major performance and usability improvements to data...
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...