Ingestion from Confluent Cloud and Kafka in Polaris
Apr 20, 2023
Timmy Freese
One of the foundational pillars of real-time data analytics is the ability to move data from one place to another quickly; Apache Kafka® is a widely adopted solution for this functionality. Confluent Cloud provides a fully-managed solution for Kafka. Whether you use Confluent Cloud, self-hosted Kafka, or alternative hosting platforms such as AWS MSK or Aiven MAK, Imply Polaris offers a solution for you to ingest data.
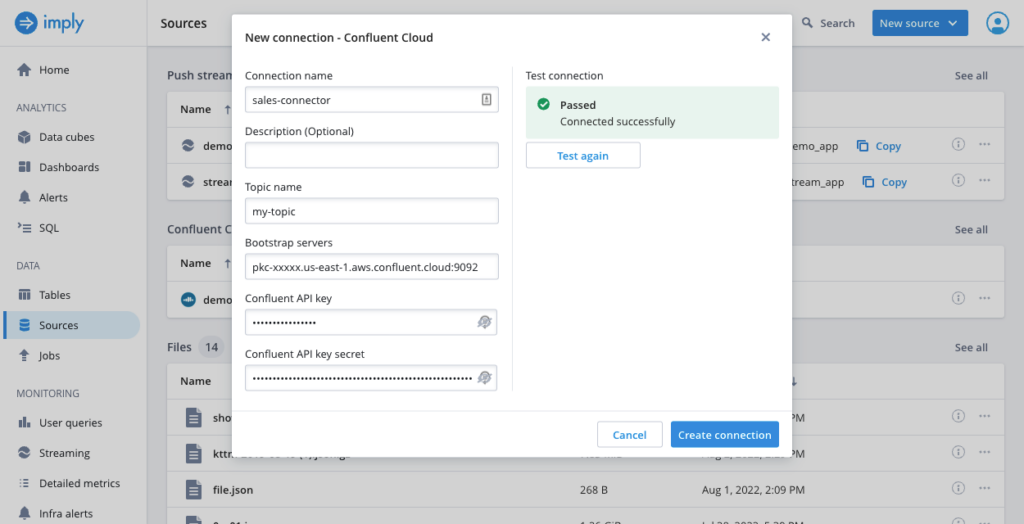
For Confluent Cloud users, Polaris offers a native, pull-based ingestion capability. Users only need to specify a few fields to establish a connection to their Confluent Cloud account and can ingest data in no time—every event enters the database and is queryable with sub-second latency. Additionally, this method offers exactly-once semantics and infers the schema from available data using Druid’s sampler.
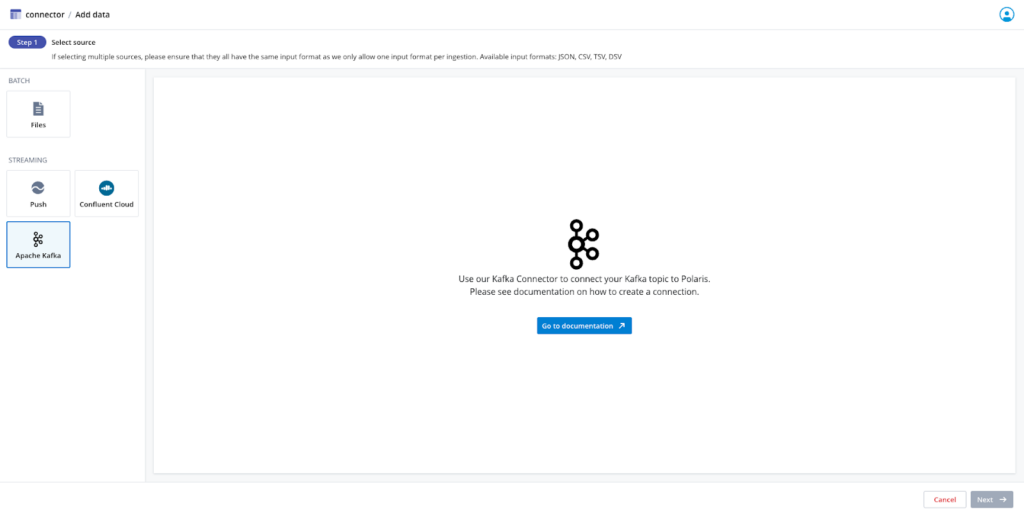
For self-hosted and other Kafka solutions, Polaris offers an HTTP-based Kafka Connector which uses our Push API endpoint. This connector will automatically batch and compress your data and handles auth token renewal for you. Additionally, this solution can be used in tandem with Polaris’s PrivateLink offering to provide enhanced security.
Regardless of which solution you choose, you can expect high throughput and low latency results. We provide OLAP functionality with OLTP performance.
Imply Lumi Product Preview: Removing the Cost–Performance Tradeoff in Observability
If you caught our recent product update, you’ve already seen the pace of development on Imply Lumi has been relentless. Last quarter, we delivered major performance and usability improvements to data...
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...