An introduction to utility management
IoT devices and data play a critical role in electric grid operations. Utilities must accurately predict energy consumption in order to efficiently manage grid operations, plan load schedules, and acquire additional power to make up for any shortfalls.
As energy demand fluctuates throughout the day, maintaining a steady energy supply is crucial. At our current levels of technology, bulk energy storage is not yet economically feasible, although emerging technologies like pumped storage hydropower or gravity batteries are quite promising. Until these solutions become cheaper and more efficient however, utilities need to balance supply and demand across various sources, plants and transformers.
This requires teams of analysts to query consumption data, predict electricity needs, purchase power from outside plants, and manage complex machine learning models—all within specific time windows when energy markets are open. Because of these constraints, queries are both urgent and high volume, as analysts race the clock to complete their tasks and ensure a stable grid with plenty of electricity to go around.
As renewable energy sources become more popular and widespread, with consumers building their own microgrids using solar panels or wind turbines, utilities will also have to adapt to an increasingly decentralized energy grid. Despite the benefits of microgrids in diversifying energy sources and improving resilience, they also introduce complexities like net metering or additional IoT data.
The advantages of Apache Druid for utility management
Scalability. Druid’s elastic scaling can accommodate fluctuations in energy usage due to factors like time of day, weather conditions, or holidays. Features like rollup, pre-aggregation, and compression also help manage data storage expenses, especially when data from new meters or microgrids are ingested.
Consistency. Druid’s exactly-once ingestion ensures data integrity and consistency across various sources like transformers, smart meters, and wind turbines. Events will never be duplicated, regardless of how complex a utility’s energy environment may be.
High concurrency. Druid provides subsecond query responses regardless of the number of users or the volume of queries. Even when hundreds of analysts are struggling to purchase power for peak demand periods (such as the hours from 7-11 p.m.), Druid’s query speeds will still remain in the milliseconds.
High interactivity. To get their results in a timely manner, analysts must swiftly explore data visualizations, drilling down, zooming into regions, or filtering by time periods. Druid supports this dynamic data exploration, freeing teams from templated dashboards with little functionality.
Customer example: Innowatts
Innowatts is an AI-enabled SaaS platform that assists power plants, retailers, utilities, and grid operators in serving more than 45 million customers across the globe.
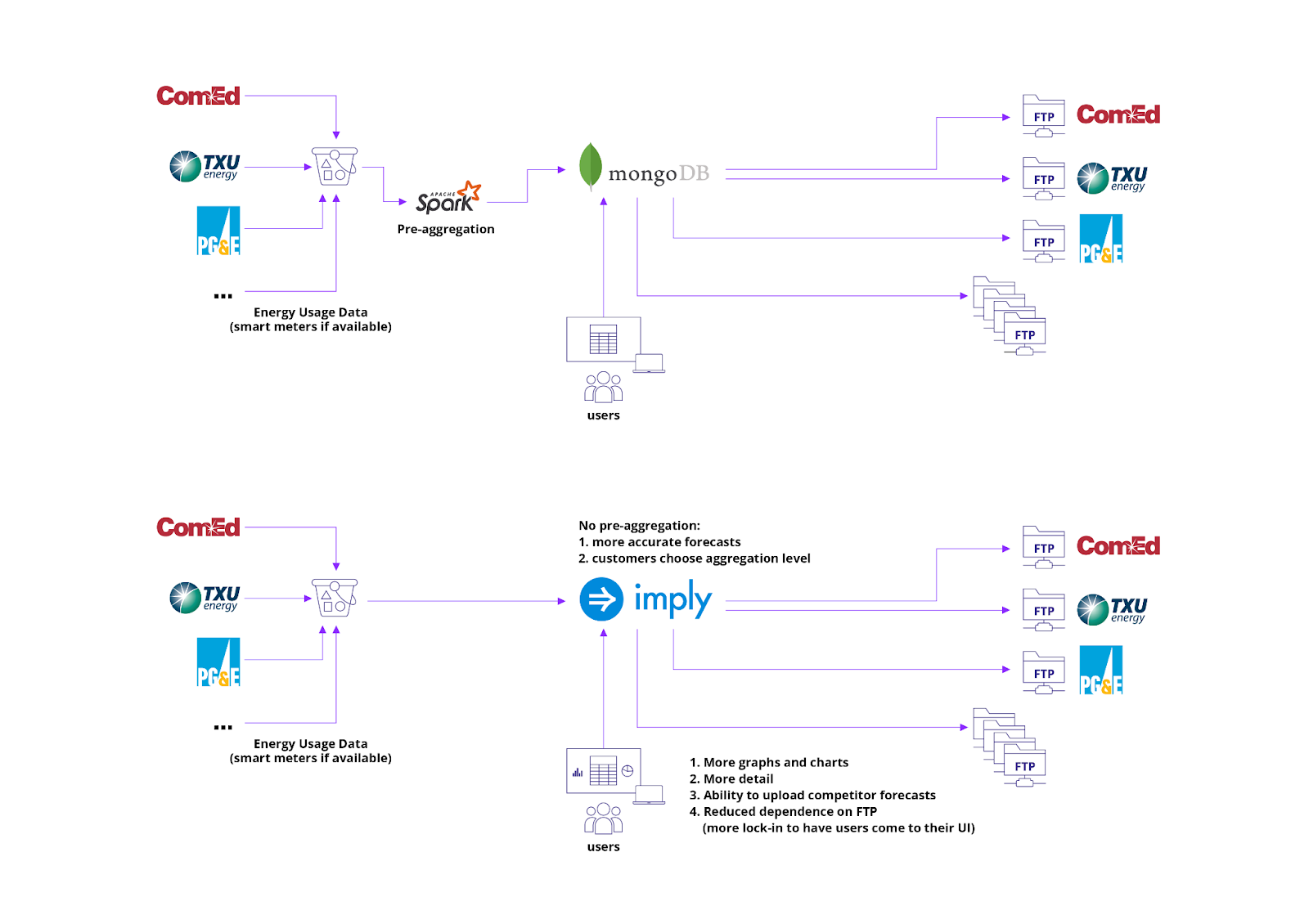
Initially, utility customers would submit data to Innowatts directly or through an additional connector. Afterwards, this data was uploaded into an Amazon S3 bucket, and the Innowatts team would then create Amazon Athena tables atop the data. Lastly, this data was pre-aggregated in Apache Spark, uploaded into MongoDB for analytics and other operations, and finally visualized for external users in Innowatts’ own user interface.
As Innowatts grew, its data intake almost doubled, rapidly growing from 40 million to 70 million smart meters and bypassing the scaling limits of their data infrastructure. In addition, this growth in smart meter data also led to a corresponding increase in user activity, as more and more analysts would query and work with this data during market windows.
Latency would render the data useless. Engineer Daniel Hernandez explains, “We go off this notion that if the client has it and it’s not fast, then it might as well be broken, because they need to be able to create insights really quickly off of that data.” ¹
Unfortunately, because of the limits of their previous database, Innowatts was unable to provide granular, meter-level data to utilities—even though they themselves built their brand and product through analyzing this individual data. At the time, Innowatts also could not support flexible data exploration (such as breaking down usage by zip code or area), a feature that customers often requested.
By transitioning to Druid, Innowatts was able to improve their infrastructure in several ways. They simplified their architecture by removing Apache Spark, and instead ingested meter data into Druid directly. Innowatts also planned to switch from batch to streaming data, a move that could enable more precise forecasting and more real-time insights. Because Druid is natively compatible with streaming services like Apache Kafka and Amazon Kinesis, the Innowatts team has basically future proofed their data environment.
Before and after architecture diagrams
The Innowatts team was also able to reduce their workload and remove rote tasks, so that they could spend more time building and improving their product. In contrast to a relational database, which would necessitated schema changes for every time a new utility customer was onboarded (or an existing one updated their own schema), Hernandez explains that “Druid would automatically detect new columns, removing the bottleneck of having to configure a new model for that client.” ²
Before Druid, this process was time consuming and required the sales team to reach out to clients in order to understand their environment, before returning to the engineering team to discuss how any changes would affect schema. Today, however, the engineering team no longer needs to get involved in the process.
Now, end users—whether they were utility customers or internal stakeholders—could take advantage of interactive dashboards, as well as ad hoc aggregations. Innowatts built their customer-facing interface on Imply Pivot, the GUI for building flexible visualizations from Druid data. Analysts can now compare historical data against current usage, fine tune their forecasts, and more accurately determine consumption patterns.
Innowatts engineers can more easily tailor aggregations to their needs. Engineers created a time block filter, breaking down event data by weekdays, filtering out weekends and any hours with missing data. In addition, they were also able to tokenize the data and implement role-based access.
By leveraging Druid, Innowatts was able to achieve a cost reduction of $4 million, improve forecast accuracy by 40 percent, and increase customer lifetime value by $3,000.
Sources
¹ ² : Innowatts: Analyzing electric meters using Druid