Enhancing Data Security with Role-Based Access Control in Druid and Imply
Jan 23, 2024
Jyoti Shekhar
Managing user access to relevant data is a crucial aspect of any data platform. In a typical Role Based Access Control (RBAC) setup, users are assigned roles that determine their access to relevant data.
How does one achieve RBAC in Druid? We will discuss two different ways of doing this, with one of them being able to achieve this at a more granular level.
Basic RBAC in Druid allows for the limitation of READ and/or WRITE access at the datasource level. For more granular control, especially in restricting access to specific rows and columns, Imply View Manager comes into play.
NOTE: Imply View Manager is an experimental (alpha) feature available with the Imply Druid distribution
RBAC in Druid:
One can limit both READ and/or WRITE access on datasources, system tables, configs, state, query_context, and external sources (for example, S3).
RESOURCE TYPE
DESCRIPTION
DATASOURCE
Druid table (popularly known as datasource)
SYSTEM TABLES
Contain metadata on the Druid cluster. Examples: TABLES, segments, server_segments, servers, supervisors ….
CONFIG
Configuration resources exposed by the cluster components. Enabled by default for the ADMIN role
STATE
Cluster-wide state resources: Example: coordinator
QUERY_CONTEXT
For internal use, no action needed with this resource
EXTERNAL
Queries to access external data through the EXTERN function. Example: Ingestion from S3 with MSQ
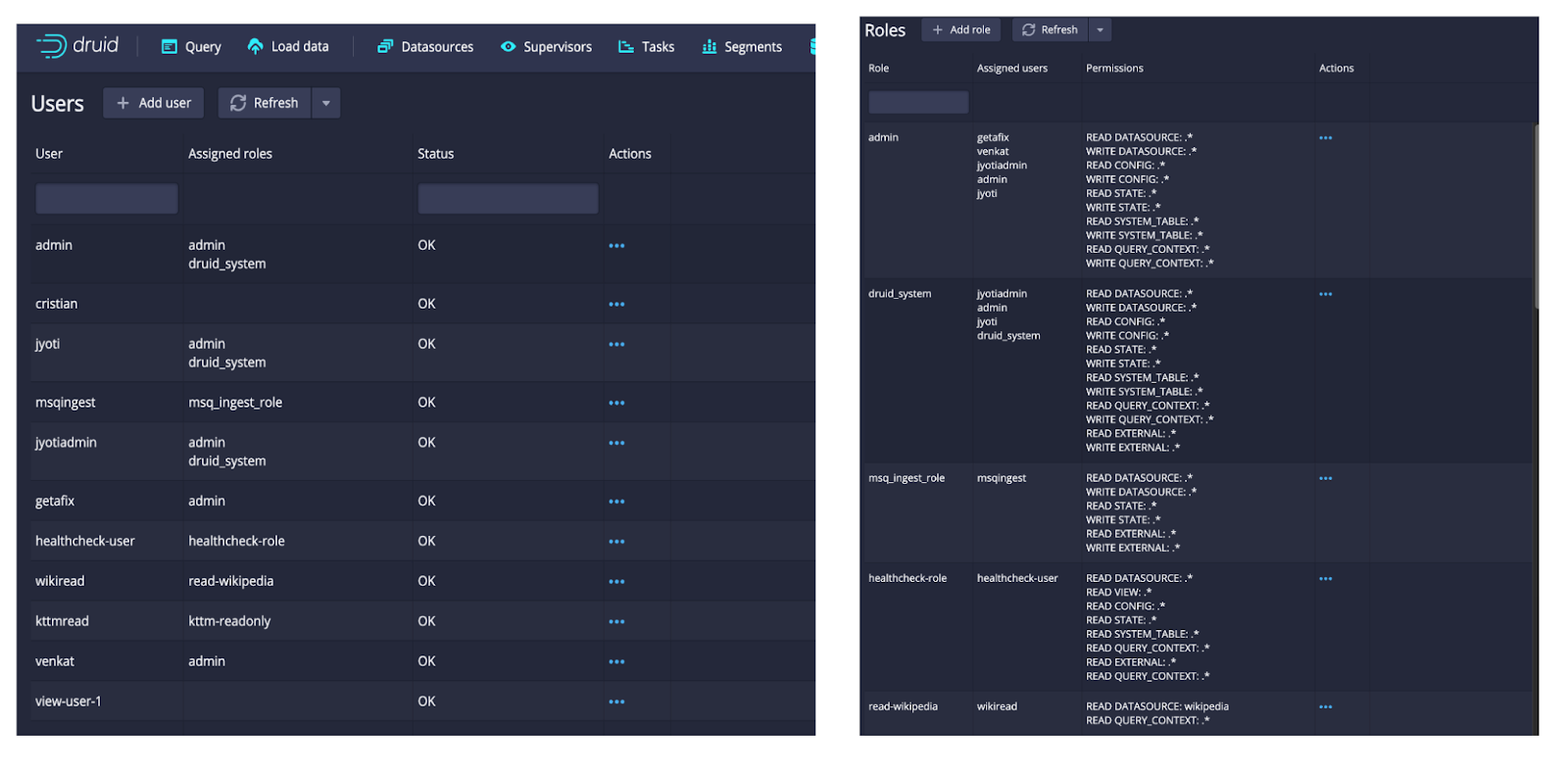
In the examples below, we will use basic auth from the Druid console:
Under User Management, we see options for managing users as well as roles+privileges:
[ Some examples further down the document under “Examples with Auth at the Resource level” ]
From the table above, one can see that the privileges can be assigned for a specific resource like
But it is for the entire resource. What if we wanted to limit access to specific rows/columns?
In comes Imply View Manager …
Imply View Manager offers a sophisticated way to limit access to data for specific users. Similar to traditional database views, Imply views are object definitions that sit on top of a datasource, eliminating the need to duplicate a subset of the data. Imply Views are a way to implement row and column-level security.
**Imply View Manager is different from the Materialized Views feature in Apache Druid**
The View Manager is managed by an extension “imply-view-manager” that is loaded in the cluster at startup.
For clusters where view Manager is implemented, we see a new resource in the Resource types dropdown:
Note that the admin role (and any other relevant role) needs VIEW READ and WRITE access specifically granted via the Druid UI or APIs.
Here is an example of a view creation
curl -k -u admin:admin --location --request POST \'https://imply-b23-elbexter-s9ruz7uko71p-10298291.us-east-1.elb.amazonaws.com:9088/proxy/coordinator/druid-ext/view-manager/v1/views/wiki-anonymous' \--header 'Content-Type: application/json'--header 'Accept: application/json' \--data-raw '{"viewSql": "SELECT \"__time\", \"channel\", \"page\", \"comment\", \"commentLength\" FROM druid.wikipedia WHERE \"isAnonymous\" = '\''true'\''" }'
Here, the API endpoint is the proxied coordinator API endpoint.
You can also use the coordinator API endpoint where applicable. Example below:
curl -k -u admin:admin --location --request POST \'http://localhost:8081/druid-ext/view-manager/v1/views/wiki-anonymous' \--header 'Content-Type: application/json'--header 'Accept: application/json' \--data-raw '{"viewSql": "SELECT \"__time\", \"channel\", \"page\", \"comment\", \"commentLength\" FROM druid.wikipedia WHERE \"isAnonymous\" = '\''true'\''" }'
The view is now available, and we can grant read access to the view:
Now let us try and access the data as the user view-user-1:
curl -k -u view-user-1:viewuser1 --request POST --header 'Content-Type: application/json''https://imply-b23-elbexter-s9ruz7uko71p-10298291.us-east-1.elb.amazonaws.com:9088/druid/v2/sql/'--data '{ "query": "SELECT * FROM view.wiki_anonymous limit 2"}'|jq
Results:
[{"__time":"2016-06-27T00:00:34.959Z","channel":"#en.wikipedia","page":"Bailando 2015","comment":"/* Scores */","commentLength":12},{"__time":"2016-06-27T00:01:14.343Z","channel":"#es.wikipedia","page":"Sumo (banda)","comment":"/* Línea de tiempo */","commentLength":21}]
The above can also be accomplished via the Druid console by selecting the view namespace in the Query tab:
And running the sql “select * from view.wiki_anonymous limit 2”
[ Additional API examples on Imply Views in the sections below under “Imply Views Examples” ]
Happy Viewing!
Examples with Auth at the Resource level
Example below using wikiread user (only has read privileges on wikipedia):
curl -k -u wikiread:wikiread --request POST --header 'Content-Type: application/json''https://imply-b23-elbexter-s9ruz7uko71p-10298291.us-east-1.elb.amazonaws.com:9088/druid/v2/sql/'--data '{ "query": "SELECT count(*) FROM wikipedia"}'[{"EXPR$0":24433}]--> RESULT
We now try and read another datasource as the wikiread user:
curl -k -u wikiread:wikiread --request POST --header 'Content-Type: application/json''https://imply-b23-elbexter-s9ruz7uko71p-10298291.us-east-1.elb.amazonaws.com:9088/druid/v2/sql/'--data '{ "query": "SELECT count(*) FROM "\wikipedia-kafka\""}'{"Access-Check-Result":"Unauthorized"}--> RESULT
The above failed as the user does not have access to the wikipedia-kafka datasource.
Example: Specifying multiple datasources for the role read-wikipedia in the Druid unified console:
Get user role details:
curl -k -u admin:admin --request GET 'https://imply-b23-elbexter-s9ruz7uko71p-10298291.us-east-1.elb.amazonaws.com:9088/proxy/coordinator/druid-ext/basic-security/authorization/db/basic/users/wikiread'{"name":"wikiread","roles":["read-wikipedia"]}--> RESULT
Imply Lumi Product Preview: Removing the Cost–Performance Tradeoff in Observability
If you caught our recent product update, you’ve already seen the pace of development on Imply Lumi has been relentless. Last quarter, we delivered major performance and usability improvements to data...
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...