Bringing Real-Time Data to Solar Power with Apache Druid
Sep 05, 2023
William To
As temperatures increase and our climate changes around us, renewable energy plays a vital role in reducing carbon emissions, ensuring energy independence, and building the foundation for a greener future.
Data also promises to transform solar energy operations. By utilizing sensor and telemetry data through Internet of Things (IoT) devices, solar operators can optimize energy generation, ensure the efficient conversion of energy from direct to alternating current, and monitor the performance of hardware from inverters to panels.
The unique challenges of solar power
When it comes to solar power generation, IoT engineering teams do encounter unusual obstacles. For instance, utility-scale solar installations are often located in far-flung areas, simply because they are so massive. Unfortunately, these locations may not have reliable network communications, which can lead to delays between when a sensor creates an event—and when an IoT environment receives it. This delay can be anywhere from hours to weeks, which makes it difficult to ensure data continuity and consistency.
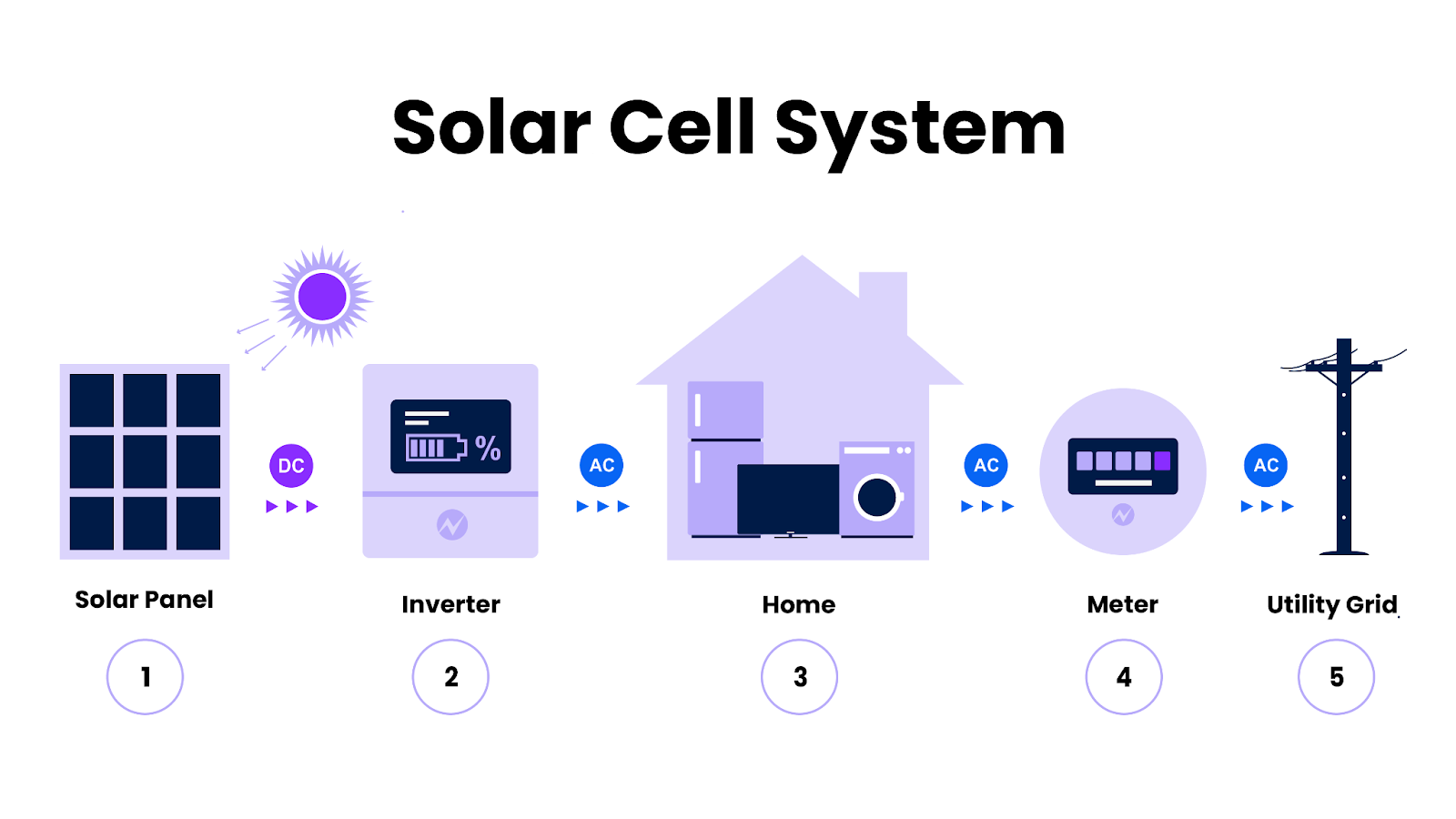
Further, the rapid spread of solar systems has led to the creation of incentives like net metering, which offsets home utility bills with credits for excess generation during daylight hours. However, this necessitates more data, whether it’s for utility analysts determining customer discounts or homeowners watching their electricity production. This leads to more user and query traffic—which makes it more difficult for smart portals to serve critical real-time data.
An example of a residential solar energy system, with solar panels, inverters, meters, and utility connection.
The advantages of Apache Druid for solar power
Scalability. Druid seamlessly scales to keep up with growing numbers of solar panels, inverters, and other hardware—and the data they generate, whether it’s terabytes or petabytes of data.
Durability and resilience. Druid provides continuous data availability through a deep storage layer, ensuring that operations run smoothly even if single nodes fail. In this situation, Druid will automatically rebalance its workload, pulling the necessary data from deep storage and distributing it across the surviving nodes.
Immediate accessibility. Data ingested into Druid is instantly available for queries, without having to be batched or persisted first. Each streamed event is ingested directly into database memory, so that users can extract urgent insights without further delays.
Concurrency. Druid supports high user and query traffic without compromising response times. In fact, queries will still be retrieved in milliseconds, regardless of the amount of data generated by smart meters or other devices, the number of analysts or homeowners accessing data, or the rate of their queries.
Consistency. Druid’s exactly-once data ingestion ensures that data is not duplicated. This is especially important for large solar energy installations with many devices distributed across various locations.
Support for time-series data. By organizing data into segments which are then partitioned by time, Druid simplifies any time-based queries, such as a WHERE operation that filters the past year’s worth of data for trend identification and analysis. Druid also automatically backfills late-arriving data in the correct place, highly valuable for companies that operate devices in remote locations with connectivity or network problems.
Apache Druid for solar power
One Apache Druid user is a leading manufacturer of high-quality photovoltaic inverters. Founded in 1981 and headquartered in Germany, this company earned €1.07 billion of revenue in 2022, an 8.4 percent increase from the previous year.
Recently, this company decided to diversify its services, providing solar power data and analytics to their customers. As part of this transition, the company collected, analyzed, visualized, and delivered data from hundreds of thousands of inverters in real time, so that users could monitor, optimize, and troubleshoot their electricity production.
Their customer-facing interface was initially built on Microsoft SQL Server. However, as their customer base expanded exponentially, they soon encountered serious scalability issues. For one, SQL Server was unable to scale past 60,000 photovoltaic plants and two million devices—even as this company’s network grew by over 10,000 plants monthly (for a total network of tens of millions of devices). In these conditions, SQL Server provided a suboptimal user experience, with slow data retrieval and even incomplete queries.
At the same time, managing SQL Server was a very manual process. The company’s software engineers had to run several instances to fit all of their customers’ facilities, and also had to manually scale each instance or patch their proprietary middleware whenever issues came up. This also applied to routine tasks: for reports and analysis, engineers had to gather data from their operational systems, copy and modify it, and finally input it into a separate SQL Server instance for analytics.
As a result, the company switched to Apache Druid, deploying it privately and using Imply tools like Clarity and Manager for monitoring and management. These programs automated rote tasks such as configuration, provisioning, and scaling, and freed up their engineers to focus on other issues.
Today, this solar equipment manufacturer generates almost one gigabyte of data daily and nearly 132 billion rows monthly, with a data retention period of one year. Once they have completed their migration, the team estimates that they will be able to receive up to 50 million events daily from 700,000 solar installations while accommodating 200,000 logins. Their customer portal is expected to support 100 concurrent queries per second while maintaining response times in the milliseconds.
Druid also solved the problem of late-arriving data. Even when data was delayed and ingested long after the event was generated, Druid automatically sorts and stores the data in the correct segment, organizing it by when it was generated, instead of when it was ingested, taking a significant load off the team’s shoulders.
In the future, this company is deliberating the use of Druid for advanced aggregation and highly granular metrics for grid operators, for which their teams still use SQL Server. By using Apache Druid, the company aims to empower their customers to investigate their data at a deeper level, and to provide more detailed, actionable insights.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...