I recently read a great article by Jeffrey Heer, Michael Bostock, and Vadim Ogievetsky that showcases the various techniques for visualizing and interacting with diverse data sets. I thought it may be useful to write something similar to showcase the various open source systems that exist in the “big data” space, including Druid, which is an open source data store I work on.excerptEnd Advances in computing have led data volumes to grow extremely quickly in recent years, and many open source systems have emerged to solve different problems around handling large volumes of data. Much like animals in a zoo, these systems come in all shapes and sizes, and it can be difficult to determine what a a system is good for. I hope this post helps to inform readers about the general classes of data infrastructure systems that exist and the primary value add of these systems.
One Solution Doesn’t Fit All
In the traditional analytics world, a single machine relational database may have been all you needed for your backend infrastructure. Events were delivered, stored, and queried all in a single system. As data volumes grew, these various aspects of data management became increasingly difficult to solve at scale. Modern “big data” architectures evolved where systems started specializing in solving different classes of problems, and most technology savvy organizations nowadays run a conglomerate of different solutions for their analytic needs. Running multiple data infrastructure systems is akin to running multiple applications on your computer; each application is designed to solve a particular problem, and it is unlikely that a single application can solve all of your use cases. It should be no surprise that resource management frameworks such as ApacheYARN and Apache Mesos have been gaining popularity for helping to manage distributed infrastructure at scale.
Looking at the modern data infrastructure space, there are four broad categories for data management technologies: delivery, storage, processing, and querying. Depending on the use cases and requirements of an organization, systems from one or all 4 categories can be combined to form an end to end solution for analytics at scale. It should be noted that many technologies may not neatly fit into one of the categories, but for the purposes of simplification, we’ll talk about these 4 groups.
The first category we’ll examine is data delivery. Events that need to be analyzed are often produced by servers in the form of logs. These events are immutable, and an event stream can be unbounded in size. These events are often of critical business value, and need to be delivered correctly so that they can analyzed. Data delivery systems focus on routing events to where they need to go, and ensuring events are not dropped along the way.
One potential location where events are transmitted to is a processing system. The processing system extracts, transforms, and loads the data in a process called ETL. The purpose of the processing system is to clean and enrich the data such that useful insights can be extracted later on. Events can be transformed one at a time as they are being streamed in with stream processors, or an entire batch of events can be transformed at once with batch processors.
Transformed events can be stored for further use, or directly loaded into a system that supports queries. Dedicated storage systems target the first use case, and store events for an indefinite period of time. Databases target the second use case. Traditionally, storage and querying systems often overlapped as databases offered support for both storage and querying. Nowadays, separate storage and querying layers are becoming much more common as “big data” solutions continue to evolve to focus on solving one class of problems very well.
Putting things together, a common setup to load a data stream and query it from an application is to combine the classes of technologies in a linear fashion.
We’re going to into more detail about this setup, but it should be noted that this is not the only way to arrange the boxes and not all of the boxes are necessary. However, with this particular arrangement, data can be delivered, processed, stored, and queried at scale, providing a flexible and scalable data management stack.
This post will go into some basic descriptions about various technologies for each of the 4 categories but is not meant to discuss the architecture of any particular system in detail. We’ll also talk about some technologies that belong in each grouping. Please note that many of the systems belonging to one grouping are not just exact replacements for one another. Similar technologies can often be used together depending on the use case. Finally, I’m sure I missed many technologies as new systems are being open sourced every day, and I am not an expert in many of the discussed technologies. If anything is incorrectly represented, please let me know in the comments.
Delivery
There are several technologies that focus on storing data for a limited period of time and delivering those events to where they need to go.
Three systems with three different approaches to data delivery are Apache Kafka, RabbitMQ, and Apache Flume. Kafka and RabbitMQ both use a publish-subscribe message model, which means multiple data consumers can read from the same set of events. Apache Kafka’s architecture is heavily influenced by transaction logs, whereas RabbitMQ’s architecture is influenced by distributed queues. One of Kafka’s main focuses is to provide resource isolation and availability guarantees between things that produce data and things that consume it. Kafka is able to store data in an intermediate buffer for a period of time, and events can still be produced even if event consumers are offline. RabbitMQ focuses more on event delivery, and provides rich routing capabilities with AMQP. To contrast the delivery models of these two systems, Apache Flume uses a push-based approach to event delivery. Apache Flume also provides native support for delivering events to HDFS and HBase.
There are dozens of other message brokers. Although the architectures of these systems can vary significantly, the high level use cases of the various systems still focuses on delivering events from one place to another.
Storage
There can be some overlap between storage systems and data delivery systems. For example, if the data retention time in Kafka is set sufficiently long enough, and if you squint hard enough, Kafka can start looking like a long term store. Distributed file systems are often used for long term storage of data, and many databases incorporate both storage and querying capabilities. HDFS is arguably the most widely used open source distributed file system, although there are numerous others that are used.
Dedicated storages hold data for further processing. SQL-on-Hadoop engines, which we will discuss later on, can also access these storages for queries.
Processing
There is some conceptual overlap between systems centered around data processing and systems centered around data querying. One way to explain the difference is that processing systems are designed to transform data, and when a data set is processed, the output result set is similar in size to the initial input set. On the other hand, for many querying systems, the output result set is usually much smaller than the input set (for example, when aggregating, filtering, or searching). Having separation between processing systems and querying systems is becoming much more standard nowadays. In the OSS world, some systems have evolved to handle long-running workloads and others have evolved to handle low-latency queries. Deploying both systems can get the best of both worlds.
Processing systems can be broadly divided into 2 categories:
Stream Processors
Stream processors deal with unbounded sequences of messages/events. Events are modified (cleaned up, enriched, or otherwise transformed), and are either sent downstream for further processing or written to a sink for further analysis. Processing on streams typically occurs before data is stored.
Three systems with three different approaches to stream processing are Apache Samza, Apache Storm, and Apache Spark Streaming. Samza and Storm share many of the same concepts: a partitioned stream model, a distributed execution model, and APIs for manipulating streams. Samza offers a different take than Storm on resource isolation – Samza tasks are independent entities and Samza does not maintain a graph of processing tasks like in Storm. Samza tasks also manage state locally, with backups in Kafka. Spark Streaming offers a slightly different model for stream processing. Events are grouped in micro-batches as RDDs and processed via Spark’s batch processing framework. While Spark Streaming is not a pure stream processor because of the micro-batching model, micro-batches are processed at near real-time speeds. One last new-comer to the streaming processing space is Apache Flink, which handles both streaming and batch ingestion through a single API.
There are many other notable stream processors. Stream processors can be used for simple querying, aggregation, and analysis, however, they are not specialized for these use cases. Connecting a stream processor to a dedicated query system is a more common approach. The stream processor handles the ETL process, and the query system is used for detailed analysis. The processing system changes a view of data and materializes the data in a query system.
Batch Processors
Batch processors manipulate large static sets of data and run similar processing tasks as stream processors. Batch processing often runs over stored data and the output is saved in storage.
MapReduce in Hadoop has long been the standard way of manipulating large batches of data. However, because of the algorithm’s generality, it is not optimized for many workflows. For example, MapReduce has no particular optimizations for processing data where the workflow follows a complex directed-acyclic graph of tasks. Both Apache Spark and Apache Tez are frameworks architected for these use cases. Spark’s architecture is also optimized for iterative workflows, such as those often found in machine learning.
Querying/Analysis
The querying space is the largest and most complex given the broad range of use cases that exist. With many traditional databases (e.g. general purpose relational databases), there is significant overlap between querying and storage. Events can be written directly to a database, and the database provides both dedicated storage and computation.
There are a set of querying technologies that enable ad-hoc queries on a variety of input and storage formats, including the Apache Parquet column format. Commonly known as SQL-on-Hadoop query engines, five technologies here are Apache Hive, Apache Spark SQL, Presto,Apache Drill and Impala. Hive decomposes queries into MapReduce jobs to retrieve data. This is extremely flexible; however, it suffers from the overhead of running MapReduce jobs. Spark SQL is similar in that it can decompose SQL queries into a workflow with RDDs. Presto, Drill, and Impala act as execution engines that pull data from an underlying store and they do not store data themselves. These systems all support plugins to a variety of databases and naturally complement databases by providing query planning and advanced execution. With SQL-on-Hadoop engines, the output data set can be similar in size to the input data set.
In many analytic workflows, the output data set is significantly smaller thanthe initial data set. Small input sets are much more human readable, and much easier to visualize in applications. One example where this is found is in search systems. Search systems create search indexes on unstructured data for full text search. Apache Solr and Elasticsearch both leverage Apache Lucene as their search index.
Looking at OLAP workflows, where queries require aggregating metrics for some particular set of filters, the output set is also much smaller than the input set. While general purpose relational databases such as MySQL, PostgreSQL, and many other row-oriented stores remain standard for OLTP workloads, the limitations of relational row-oriented databases for OLAP workloads have become well-known. Most analytic queries do not require every column of data, and scanning an entire row of data as part of a query is needlessly expensive.
One approach to improve query performance is to store pre-computed aggregates and queries in key/value stores such as HBase and Cassandra. The key is the exact parameters of the query, and the value is the result of the query. The queries return extremely quickly, but at the cost of flexibility, as ad-hoc exploratory queries are not possible with pre-computing every possible query permutation Pre-computing all permutations of all ad-hoc queries leads to result sets that grow exponentially with the number of columns of a data set, and pre-computing queries for complex real-world data sets can require hours of pre-processing time.
One other approach to using key/value stores to use the dimensions of an event as the key and the event measures as the value. Aggregations are done by issuing range scans on this data. Timeseries specific databases such as OpenTSDB use this approach. One of the limitations here is that the key/value storage model does not have indexes for any kind of filtering other than prefix ranges, which can be used to filter a query down to a metric and time range, but cannot resolve complex predicates to narrow the exact data to scan. When the number of rows to scan gets large, this limitation can greatly reduce performance. It is also harder to achieve good locality with key/value stores because most don’t support pushing down aggregates to the storage layer.
To overcome the limits of key/value stores and relational databases for analytics, column-oriented databases have been gaining popularity. With column stores, only the columns that are directly related to a query are scanned, and the format is inherently designed for fast filtering and scanning. Druid is one such column store optimized for OLAP queries. Druid combines a column format with search indexes to scan exactly what is needed for a query. This architecture enables extremely fast scans and filters, and Druid is most often used to power user-facing analytic applications that require sub-second response times to provide a good user experience.
Given the wide range of use cases of querying systems, many organizations will often run multiple querying systems, adding more as new use cases develop. Returning to the idea presented at the beginning of this post, querying systems are best used when combined with other data infrastructure technologies to form an end-to-end stack.
End-to-end Analytics with OSS
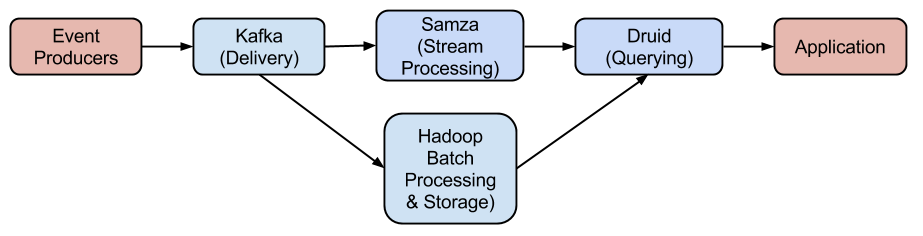
We’ve written before about a concrete open source version of an end-to-end OLAP analytics stack that has scaled to trillions of events and petabytes of data. The cornerstones of the stack are Kafka, Samza, Hadoop, and Druid.
In the above stack, Kafka provides a fast message bus and is the delivery point for machine-generated event streams. Samza and Hadoop work together to process and load data into Druid. Samza provides stream processing for near-real-time data, and Hadoop provides batch processing for historical data. Druid provides flexible, highly available, low-latency queries.
If you are interested in learning more about these technologies, please check out the project webpages.
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...